百度对象存储BOS(Baidu Object Storage)进行冷存储数据备份
最近有需求就是冷存储数据进行异地灾备,同时为了更多的节省本地的存储成本,维护成本,人力资源等等,选择使用相对更为优惠的百度对象存储来进行备份数据,BOS产品介绍:BOS介绍,为了快速的,批量的上传文件,利用BOS Python SDK开发了一套分布式多任务上传解决方案,本文主要来介绍一下BOS Python SDK的使用方法,为BOS免费做了广告,怎么感谢我!
一、创建虚拟环境
# yum install python-virtualenv # mkvirtualenv bos # workon bos使用virtualenv主要是使用虚拟环境来搭建python开发环境,将不同的python项目进行隔离,避免相关的包的冲突,简单的介绍一下virtualenv的使用:
列出虚拟环境列表:
workon/lsvirtualenv
新建虚拟环境:
mkvirtualenv [虚拟环境名称]
启动/切换虚拟环境:
workon [虚拟环境名称]
删除虚拟环境:
rmvirtualenv [虚拟环境名称]
离开虚拟环境:
deactive
二、安装BOS SDK
2.1 下载bos sdk安装包
URL:https://bce.baidu.com/doc/SDKTool/index.html#Python
wget http://sdk.bce.baidu.com/console-sdk/bce-python-sdk-0.8.8.zip2.2 执行安装脚本
python setup.py install
三、编写配置文件
bos_sample_conf.py:
import logging
import os
import sys
from baidubce.bce_client_configuration import BceClientConfiguration
from baidubce.auth.bce_credentials import BceCredentials
PROXY_HOST = 'localhost:8080'
bos_host = "bj.bcebos.com"
access_key_id = "a6748c1334a44c2d8af60fcdf098b30d"
secret_access_key = "3d7621d35b0c426ea2c0dfdbfca45151"
logger = logging.getLogger('baidubce.services.bos.bosclient')
fh = logging.FileHandler("sample.log")
fh.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
logger.setLevel(logging.DEBUG)
logger.addHandler(fh)
config = BceClientConfiguration(credentials=BceCredentials(access_key_id, secret_access_key), endpoint = bos_host)
配置文件指定了上传的host,id和secret,并执行了client的初始化配置config。
四、文件上传
import os,sys,hashlib
from baidubce import exception
from baidubce.services import bos
from baidubce.services.bos import canned_acl
from baidubce.services.bos.bos_client import BosClient
import base64
import bos_sample_conf
##init a bos client
bos_client = BosClient(bos_sample_conf.config)
##init a bucket
bucket_name = 'wahaha'
if not bos_client.does_bucket_exist(bucket_name):
bos_client.create_bucket(bucket_name)
print "init bucket:%s success" % bucket_name
##upload object from string
object_key = 'Happy Spring Festival'
str = 'this is the test string'
bos_client.put_object_from_string(bucket_name,object_key,str)
##put object from file
file_name = "/root/baidu_object_storage/test/file_to_be_upload"
response = bos_client.put_object_from_file(bucket_name, object_key + ' plus',file_name)
print "response.metadata.etag = " + response.metadata.etag
##get object meta data
response = bos_client.get_object_meta_data(bucket_name, object_key+' plus')
print "response object meta data:"
print response
##list objects in bucket
response = bos_client.list_objects(bucket_name)
for object in response.contents:
print 'object.key = ' + object.key
##get bucket list
response = bos_client.list_buckets()
for bucket in response.buckets:
print "bucket.name = " + bucket.name
##get object
print bos_client.get_object_as_string(bucket_name,object_key)
#get unfinished multipart upload task
print "get unfinished multipart upload task:"
for item in bos_client.list_all_multipart_uploads(bucket_name):
print 'item.upload_id = ' + item.upload_id
#abort unfinished multipart upload task
print "abort unfinished multipart upload task"
for item in bos_client.list_all_multipart_uploads(bucket_name):
bos_client.abort_multipart_upload(bucket_name, item.key.encode("utf-8"), upload_id = item.upload_id)
response = bos_client.list_multipart_uploads(bucket_name)
for item in response.bukcet:
print item.name
结果:

五、大文件上传
import os
import sys
import hashlib
sys.path.append("../bos")
import bos_sample_conf
from baidubce import exception
from baidubce.services import bos
from baidubce.services.bos import canned_acl
from baidubce.services.bos.bos_client import BosClient
default_path = os.path.dirname(os.path.realpath(__file__))
#init a bos client
bos_client = BosClient(bos_sample_conf.config)
#init a bucket
bucket_name = 'wahaha'
if not bos_client.does_bucket_exist(bucket_name):
bos_client.create_bucket(bucket_name)
#init object key
object_key = 'this is object_key of big file'
#upload multipart object
upload_id = bos_client.initiate_multipart_upload(bucket_name,object_key).upload_id
print 'upload_id = ' + upload_id
file_name = default_path + os.path.sep + 'big_file'
if os.path.isfile(file_name):
print "file_name = %s" % file_name
else:
exit(-1)
#set the beginning of multipart
left_size = os.path.getsize(file_name)
#set the offset
offset = 0
part_number = 1
part_list = []
e_tag_str = ""
while left_size > 0:
#set each part 50MB
print "size left: %dMB" % (left_size/1014/1024)
part_size = 50*1024*1024
if left_size < part_size:
part_size = left_size
response = bos_client.upload_part_from_file(
bucket_name,object_key,upload_id,part_number,part_size,file_name,offset)
left_size -= part_size
offset += part_size
part_list.append({
"partNumber":part_number,
"eTag":response.metadata.etag
})
part_number += 1
e_tag_str += response.metadata.etag
print part_number, " ", response.metadata.etag
print "\n"
response = bos_client.complete_multipart_upload(bucket_name,object_key,upload_id,part_list)
print response
m = hashlib.md5()
m.update(e_tag_str)
e_tag_str_to_md5 = "-" + m.hexdigest()
if e_tag_str_to_md5 == response.etag:
print "e_tag match great!!!"
else:
print "etag does not match, e_tag_str_to_md5 = %s" % e_tag_str_to_md5
print "\n"
print response.bucket
print response.key
print response.etag
print response.location
结果:
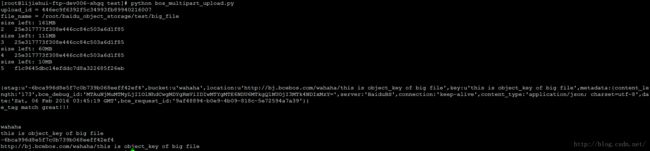
注:
1.对于小文件上传返回的response值的etag值就是小文件的md5值。
2.对于大文件上传,完成分块上传的etag是每一个分块上传返回的etag值相加之后再计算md5值得到的值之前再加个"-"(好抽象)。
Author:忆之独秀
Email:[email protected]
注明出处:http://blog.csdn.net/lavorange/article/details/50639849