Ls 1 - Understanding the nature of Spark Streaming
What is Spark Streaming?
According to the Official Apache Spark website, Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
Spark Streaming can integrate with different kinds of input source, e.g. such as Kafka, Flume, HDFS/S3, Kinesis and Twitter. The input source will be extracted and transformed by the Spark Streaming application. The transformed data can be loaded into HDFS file system, different databases e.g. Redis, MySQL or Oracle etc. It can also connect to live dashboard.

Caption from Apache Spark website:
Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.

Spark Streaming Data Flow experiment
I will base on the Blacklist Filtering examples to look into the details of the data flow. Let me update the socket time to 5 mins and see what happen to the data flow.
From the History Sever, the job takes a total of 4.9 mins to complete the application.

Select the job you just ran, you can see clearly that it has executed 5 jobs. Next, we will go and check one by one.
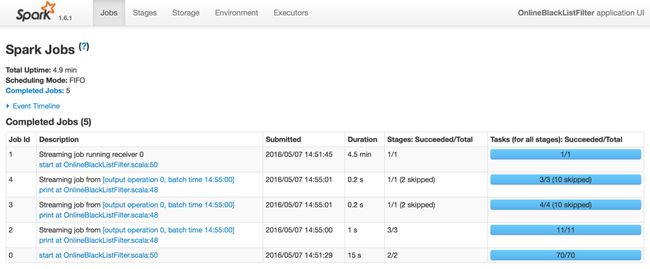
Job Id 0
We will start checking the details by Job Id 0. As you can see for Job 0, it has 2 stages, stage 0 and stage 1.
From the Spark Streaming UI, we can see that It has executed an reduceByKey function. But according to our program, we don’t have any reduceByKey transformation, so why?
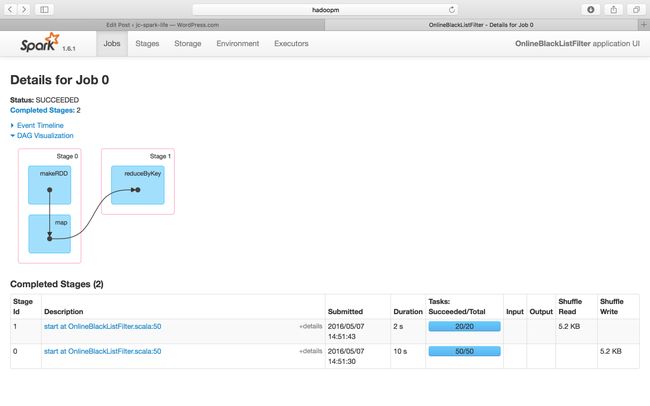
Job Id 0 – Stage 0
This is the first job inside one Spark Application
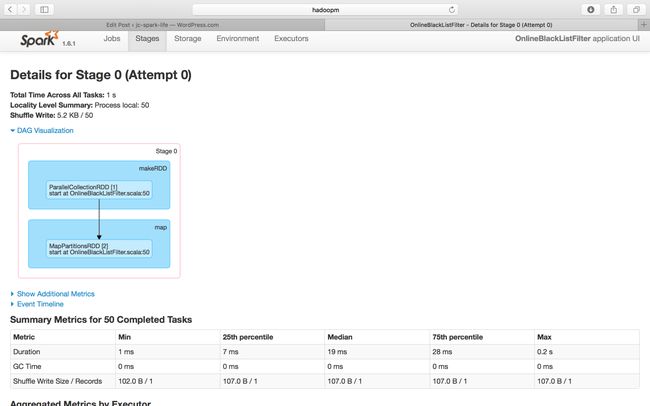

Job Id 0 – Stage 1
This tells us a very important message that the initiation of Spark Streaming program will automatically generate one or more Spark Jobs that consists of Action type transformation such as reduceByKey.
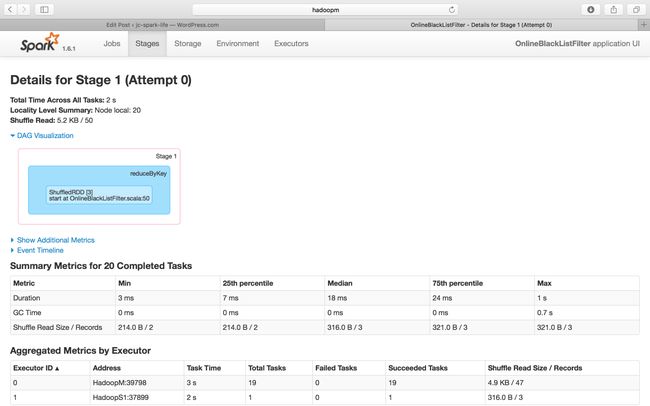
Next, go to Job Id 1 and check the details
As you read through the screenshot, you can figure out the total duration of this job is 4.9 mins, however, you can see below, Job 1 was executed for 4.5 mins which is around 95% of the whole Spark Streaming Application.
What is inside Job 1, why is it needs to consume such a higher percentage of time. Let’s deep dive and see what’s going on inside this Job.

It was very surprising that a Spark Streaming program needs around 95% of time to create a Receiver for receiving streaming data and it executed on one node e.g. HadoopS1 with one task only. The Initiation of Receiver on Executor is triggered by a Spark Job which consists of an Action type transformation.
Have you ever thought of the difference between the job created by the Receiver and the normal Spark Job? They are indeed no difference and the result here implies that we can create a lot of Spark job in one application. Different jobs can integrate with each other. The automatically created Receiver (job) in Spark Streaming Application serve as a very good starting point to collect data for other complicated program to process, such as passing the streaming data for graph analysis or machine learning. A complicated Spark application must consists of a couples of jobs.
Another point to note is the locality level, it shows that the locality level for the Receiver is Process Local, means the data will first keep in ram until it was full and then move to disk, such as HDFS.
Qs: How many jobs are being initiated by your Spark Application and how did different jobs in the same program integrate with each others?
Qs: But why it needs take so long to create a Receiver, what is it actually done?
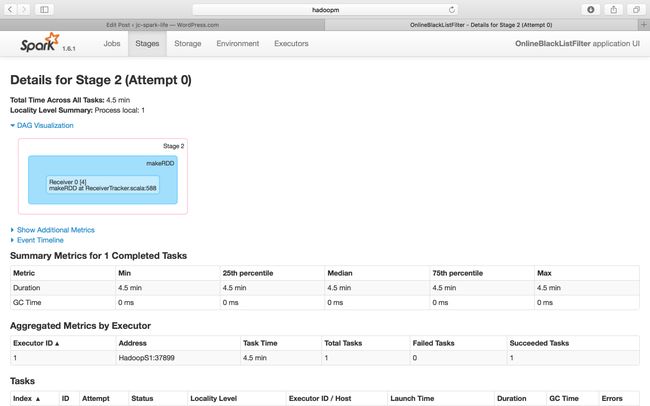
Next, go to Job ID 2 and check the details
It generated a BlockRDD that came from the sock text stream, this is by input DStream based on the time interval (300 seconds) to generate the RDD. When the job is running, it will have a regular data input.
We receive data on one executor but we process the data on the Spark Cluster (3 worker nodes)

Stage 3 of Job Id 2
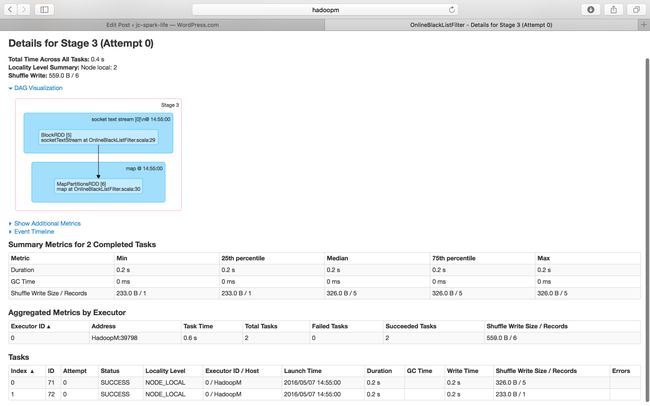
Stage 4 of Job Id 2
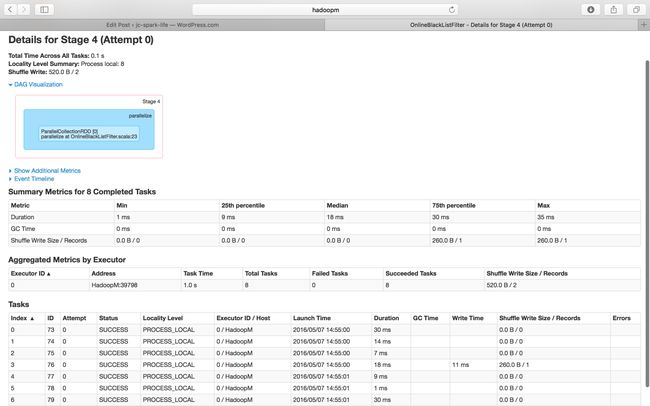
Stage 5 of Job Id 2
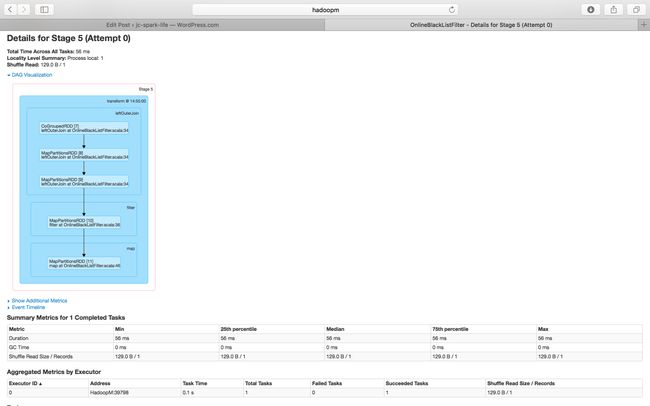
Stage 6 of Job Id 3

Qs: why there are so many tasks being skipped?
Stage 11 of Job id 4
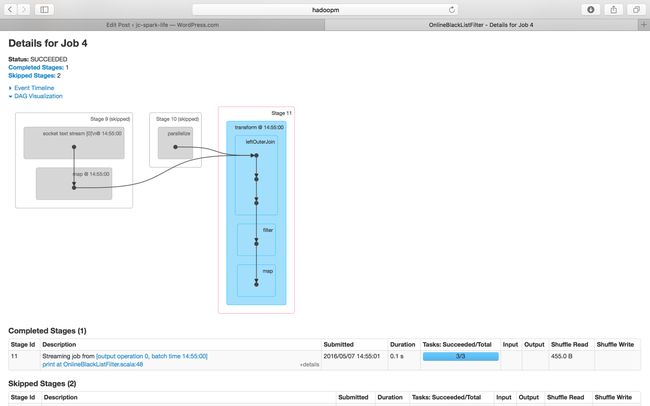
In Conclusion
This exercise aimed to show the readers about the process flow inside a Spark Streaming Application. There was only one business logic which aimed to filter out the blacklist (e.g. name/ ip). However, when we looked into the DStream Graph of an application. It founds out that it was also triggered and automatically generated other jobs for the streaming program to function properly.
Obviously, I still got a few questions in my mind what is the function of the other jobs and why is it needed? (Those questions will be not answered at this moment)
Spark Streaming is basically a batch process with regular time interval to generate an RDD which called DStream. The time interval can pre-configure to per mili-second. In our examples, we have configured the time interval to 5 mins, means for every 5 mins, the program will generate an RDD with action type transformation to trigger a job.
The DStream will also generate a DStream Graph about different job dependencies which are the same concept of RDD-DAG.
Bullet Point:
1. Spark Streaming is an extension of the core Spark API.
2. DStream = RDD + Time Interval
3. Receiver is one of the job that executed on Executor and it consumes 95% duration of the Spark Streaming Application
Thanks for reading
Janice
——————————————————————————————–
Reference: DT大数据梦工厂SPARK版本定制課程 – 第1课:通过案例对SparkStreaming 透彻理解三板斧之一:解密SparkStreaming另类实验及SparkStreaming本质解析
Sharing is Good, Learning is Fun.
今天很残酷、明天更残酷,后天很美好。但很多人死在明天晚上、而看不到后天的太阳。 –马云 Jack Ma