javaweb学习总结——HttpServletResponse对象(一)
Web服务器收到客户端的http请求,会针对每一次请求,分别创建一个用于代表请求的request对象、和代表响应的response对象。
request和response对象即然代表请求和响应,那我们要获取客户机提交过来的数据,只需要找request对象就行了。要向客户机输出数据,只需要找response对象就行了。
一、HttpServletResponse对象介绍

HttpServletResponse对象代表服务器的响应。这个对象中封装了向客户端发送数据、发送响应头,发送响应状态码的方法。查看HttpServletResponse的API,可以看到这些相关的方法。
1.1、负责向客户端(浏览器)发送数据的相关方法

1.2、负责向客户端(浏览器)发送响应头的相关方法


1.3、负责向客户端(浏览器)发送响应状态码的相关方法
![]()
1.4、响应状态码的常量
HttpServletResponse定义了很多状态码的常量(具体可以查看Servlet的API),当需要向客户端发送响应状态码时,可以使用这些常量,避免了直接写数字,常见的状态码对应的常量:
状态码404对应的常量
![]()
状态码200对应的常量

状态码500对应的常量
![]()
二、HttpServletResponse对象常见应用
2.1、使用OutputStream流向客户端浏览器输出中文数据
使用OutputStream流输出中文注意问题:
在服务器端,数据是以哪个码表输出的,那么就要控制客户端浏览器以相应的码表打开,比如:outputStream.write("中国".getBytes("UTF-8"));使用OutputStream流向客户端浏览器输出中文,以UTF-8的编码进行输出,此时就要控制客户端浏览器以UTF-8的编码打开,否则显示的时候就会出现中文乱码,那么在服务器端如何控制客户端浏览器以以UTF-8的编码显示数据呢?可以通过设置响应头控制浏览器的行为,例如:response.setHeader("content-type", "text/html;charset=UTF-8");通过设置响应头控制浏览器以UTF-8的编码显示数据。
范例:使用OutputStream流向客户端浏览器输出"中国"这两个汉字
package gacl.response.study;
import java.io.IOException;
import java.io.OutputStream;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class ResponseDemo01 extends HttpServlet {
private static final long serialVersionUID = 4312868947607181532L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
outputChineseByOutputStream(response);//使用OutputStream流输出中文
}
/**
* 使用OutputStream流输出中文
* @param request
* @param response
* @throws IOException
*/
public void outputChineseByOutputStream(HttpServletResponse response) throws IOException{
/**使用OutputStream输出中文注意问题:
* 在服务器端,数据是以哪个码表输出的,那么就要控制客户端浏览器以相应的码表打开,
* 比如:outputStream.write("中国".getBytes("UTF-8"));//使用OutputStream流向客户端浏览器输出中文,以UTF-8的编码进行输出
* 此时就要控制客户端浏览器以UTF-8的编码打开,否则显示的时候就会出现中文乱码,那么在服务器端如何控制客户端浏览器以以UTF-8的编码显示数据呢?
* 可以通过设置响应头控制浏览器的行为,例如:
* response.setHeader("content-type", "text/html;charset=UTF-8");//通过设置响应头控制浏览器以UTF-8的编码显示数据
*/
String data = "中国";
OutputStream outputStream = response.getOutputStream();//获取OutputStream输出流
response.setHeader("content-type", "text/html;charset=UTF-8");//通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
/**
* data.getBytes()是一个将字符转换成字节数组的过程,这个过程中一定会去查码表,
* 如果是中文的操作系统环境,默认就是查找查GB2312的码表,
* 将字符转换成字节数组的过程就是将中文字符转换成GB2312的码表上对应的数字
* 比如: "中"在GB2312的码表上对应的数字是98
* "国"在GB2312的码表上对应的数字是99
*/
/**
* getBytes()方法如果不带参数,那么就会根据操作系统的语言环境来选择转换码表,如果是中文操作系统,那么就使用GB2312的码表
*/
byte[] dataByteArr = data.getBytes("UTF-8");//将字符转换成字节数组,指定以UTF-8编码进行转换
outputStream.write(dataByteArr);//使用OutputStream流向客户端输出字节数组
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
运行结果如下:
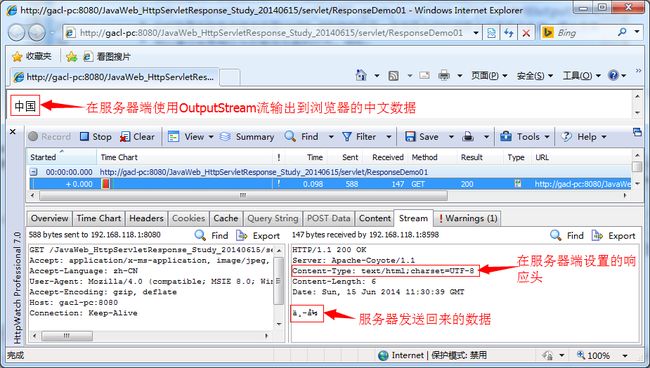
客户端浏览器接收到数据后,就按照响应头上设置的字符编码来解析数据,如下所示:

2.2、使用PrintWriter流向客户端浏览器输出中文数据
使用PrintWriter流输出中文注意问题:
在获取PrintWriter输出流之前首先使用"response.setCharacterEncoding(charset)"设置字符以什么样的编码输出到浏览器,如:response.setCharacterEncoding("UTF-8");设置将字符以"UTF-8"编码输出到客户端浏览器,然后再使用response.getWriter();获取PrintWriter输出流,这两个步骤不能颠倒,如下:
1 response.setCharacterEncoding("UTF-8");//设置将字符以"UTF-8"编码输出到客户端浏览器 2 /** 3 * PrintWriter out = response.getWriter();这句代码必须放在response.setCharacterEncoding("UTF-8");之后 4 * 否则response.setCharacterEncoding("UTF-8")这行代码的设置将无效,浏览器显示的时候还是乱码 5 */ 6 PrintWriter out = response.getWriter();//获取PrintWriter输出流
然后再使用response.setHeader("content-type", "text/html;charset=字符编码");设置响应头,控制浏览器以指定的字符编码编码进行显示,例如:
1 //通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码 2 response.setHeader("content-type", "text/html;charset=UTF-8");
除了可以使用response.setHeader("content-type", "text/html;charset=字符编码");设置响应头来控制浏览器以指定的字符编码编码进行显示这种方式之外,还可以用如下的方式来模拟响应头的作用
1 /** 2 * 多学一招:使用HTML语言里面的<meta>标签来控制浏览器行为,模拟通过设置响应头控制浏览器行为 3 *response.getWriter().write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'/>"); 4 * 等同于response.setHeader("content-type", "text/html;charset=UTF-8"); 5 */ 6 response.getWriter().write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'/>");
范例:使用PrintWriter流向客户端浏览器输出"中国"这两个汉字
package gacl.response.study;
import java.io.IOException;
import java.io.OutputStream;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class ResponseDemo01 extends HttpServlet {
private static final long serialVersionUID = 4312868947607181532L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
outputChineseByPrintWriter(response);//使用PrintWriter流输出中文
}
/**
* 使用PrintWriter流输出中文
* @param request
* @param response
* @throws IOException
*/
public void outputChineseByPrintWriter(HttpServletResponse response) throws IOException{
String data = "中国";
//通过设置响应头控制浏览器以UTF-8的编码显示数据,如果不加这句话,那么浏览器显示的将是乱码
//response.setHeader("content-type", "text/html;charset=UTF-8");
response.setCharacterEncoding("UTF-8");//设置将字符以"UTF-8"编码输出到客户端浏览器
/**
* PrintWriter out = response.getWriter();这句代码必须放在response.setCharacterEncoding("UTF-8");之后
* 否则response.setCharacterEncoding("UTF-8")这行代码的设置将无效,浏览器显示的时候还是乱码
*/
PrintWriter out = response.getWriter();//获取PrintWriter输出流
/**
* 多学一招:使用HTML语言里面的<meta>标签来控制浏览器行为,模拟通过设置响应头控制浏览器行为
* out.write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'/>");
* 等同于response.setHeader("content-type", "text/html;charset=UTF-8");
*/
out.write("<meta http-equiv='content-type' content='text/html;charset=UTF-8'/>");
out.write(data);//使用PrintWriter流向客户端输出字符
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
当需要向浏览器输出字符数据时,使用PrintWriter比较方便,省去了将字符转换成字节数组那一步。
2.3、使用OutputStream或者PrintWriter向客户端浏览器输出数字
比如有如下的代码:
package gacl.response.study;
import java.io.IOException;
import java.io.OutputStream;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class ResponseDemo01 extends HttpServlet {
private static final long serialVersionUID = 4312868947607181532L;
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
outputOneByOutputStream(response);//使用OutputStream输出1到客户端浏览器
}
/**
* 使用OutputStream流输出数字1
* @param request
* @param response
* @throws IOException
*/
public void outputOneByOutputStream(HttpServletResponse response) throws IOException{
response.setHeader("content-type", "text/html;charset=UTF-8");
OutputStream outputStream = response.getOutputStream();
outputStream.write("使用OutputStream流输出数字1:".getBytes("UTF-8"));
outputStream.write(1);
}
}
运行上面代码显示的结果如下:
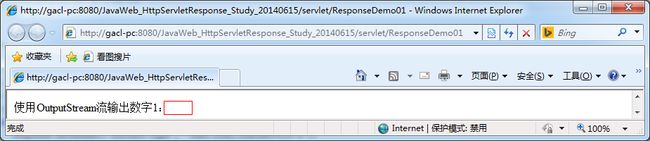
运行的结果和我们想象中的不一样,数字1没有输出来,下面我们修改一下上面的outputOneByOutputStream方法的代码,修改后的代码如下:
/**
* 使用OutputStream流输出数字1
* @param request
* @param response
* @throws IOException
*/
public void outputOneByOutputStream(HttpServletResponse response) throws IOException{
response.setHeader("content-type", "text/html;charset=UTF-8");
OutputStream outputStream = response.getOutputStream();
outputStream.write("使用OutputStream流输出数字1:".getBytes("UTF-8"));
//outputStream.write(1);
outputStream.write((1+"").getBytes());
}
1+""这一步是将数字1和一个空字符串相加,这样处理之后,数字1就变成了字符串1了,然后再将字符串1转换成字节数组使用OutputStream进行输出,此时看到的结果如下:
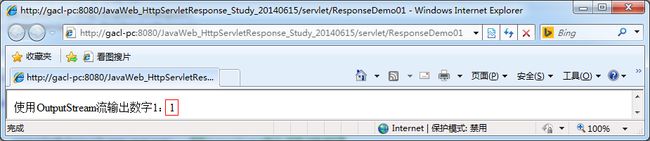
这次可以看到输出来的1了,这说明了一个问题:在开发过程中,如果希望服务器输出什么浏览器就能看到什么,那么在服务器端都要以字符串的形式进行输出。
如果使用PrintWriter流输出数字,那么也要先将数字转换成字符串后再输出,如下:
/**
* 使用PrintWriter流输出数字1
* @param request
* @param response
* @throws IOException
*/
public void outputOneByPrintWriter(HttpServletResponse response) throws IOException{
response.setHeader("content-type", "text/html;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();//获取PrintWriter输出流
out.write("使用PrintWriter流输出数字1:");
out.write(1+"");
}
2.4、文件下载
文件下载功能是web开发中经常使用到的功能,使用HttpServletResponse对象就可以实现文件的下载
文件下载功能的实现思路:
1.获取要下载的文件的绝对路径
2.获取要下载的文件名
3.设置content-disposition响应头控制浏览器以下载的形式打开文件
4.获取要下载的文件输入流
5.创建数据缓冲区
6.通过response对象获取OutputStream流
7.将FileInputStream流写入到buffer缓冲区
8.使用OutputStream将缓冲区的数据输出到客户端浏览器
范例:使用Response实现文件下载
package gacl.response.study;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @author gacl
* 文件下载
*/
public class ResponseDemo02 extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
downloadFileByOutputStream(response);//下载文件,通过OutputStream流
}
/**
* 下载文件,通过OutputStream流
* @param response
* @throws FileNotFoundException
* @throws IOException
*/
private void downloadFileByOutputStream(HttpServletResponse response)
throws FileNotFoundException, IOException {
//1.获取要下载的文件的绝对路径
String realPath = this.getServletContext().getRealPath("/download/1.JPG");
//2.获取要下载的文件名
String fileName = realPath.substring(realPath.lastIndexOf("\\")+1);
//3.设置content-disposition响应头控制浏览器以下载的形式打开文件
response.setHeader("content-disposition", "attachment;filename="+fileName);
//4.获取要下载的文件输入流
InputStream in = new FileInputStream(realPath);
int len = 0;
//5.创建数据缓冲区
byte[] buffer = new byte[1024];
//6.通过response对象获取OutputStream流
OutputStream out = response.getOutputStream();
//7.将FileInputStream流写入到buffer缓冲区
while ((len = in.read(buffer)) > 0) {
//8.使用OutputStream将缓冲区的数据输出到客户端浏览器
out.write(buffer,0,len);
}
in.close();
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
运行结果如下所示:
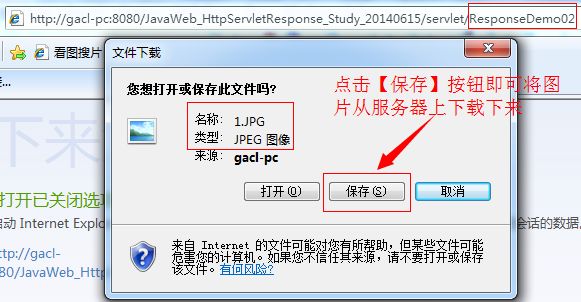
范例:使用Response实现中文文件下载
下载中文文件时,需要注意的地方就是中文文件名要使用URLEncoder.encode方法进行编码(URLEncoder.encode(fileName, "字符编码")),否则会出现文件名乱码。
package gacl.response.study;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @author gacl
* 文件下载
*/
public class ResponseDemo02 extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
downloadChineseFileByOutputStream(response);//下载中文文件
}
/**
* 下载中文文件,中文文件下载时,文件名要经过URL编码,否则会出现文件名乱码
* @param response
* @throws FileNotFoundException
* @throws IOException
*/
private void downloadChineseFileByOutputStream(HttpServletResponse response)
throws FileNotFoundException, IOException {
String realPath = this.getServletContext().getRealPath("/download/张家界国家森林公园.JPG");//获取要下载的文件的绝对路径
String fileName = realPath.substring(realPath.lastIndexOf("\\")+1);//获取要下载的文件名
//设置content-disposition响应头控制浏览器以下载的形式打开文件,中文文件名要使用URLEncoder.encode方法进行编码,否则会出现文件名乱码
response.setHeader("content-disposition", "attachment;filename="+URLEncoder.encode(fileName, "UTF-8"));
InputStream in = new FileInputStream(realPath);//获取文件输入流
int len = 0;
byte[] buffer = new byte[1024];
OutputStream out = response.getOutputStream();
while ((len = in.read(buffer)) > 0) {
out.write(buffer,0,len);//将缓冲区的数据输出到客户端浏览器
}
in.close();
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
运行结果如下所示:
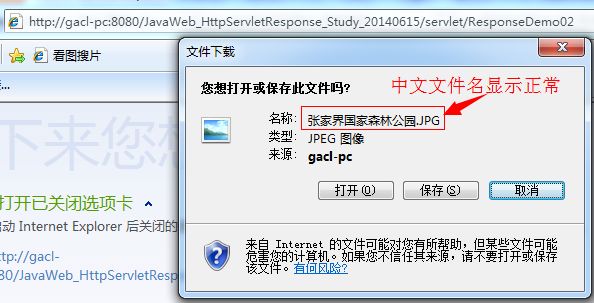
文件下载注意事项:编写文件下载功能时推荐使用OutputStream流,避免使用PrintWriter流,因为OutputStream流是字节流,可以处理任意类型的数据,而PrintWriter流是字符流,只能处理字符数据,如果用字符流处理字节数据,会导致数据丢失。
范例:使用PrintWriter流下载文件
package gacl.response.study;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @author gacl
* 文件下载
*/
public class ResponseDemo02 extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
downloadFileByPrintWriter(response);//下载文件,通过PrintWriter流
}
/**
* 下载文件,通过PrintWriter流,虽然也能够实现下载,但是会导致数据丢失,因此不推荐使用PrintWriter流下载文件
* @param response
* @throws FileNotFoundException
* @throws IOException
*/
private void downloadFileByPrintWriter(HttpServletResponse response)
throws FileNotFoundException, IOException {
String realPath = this.getServletContext().getRealPath("/download/张家界国家森林公园.JPG");//获取要下载的文件的绝对路径
String fileName = realPath.substring(realPath.lastIndexOf("\\")+1);//获取要下载的文件名
//设置content-disposition响应头控制浏览器以下载的形式打开文件,中文文件名要使用URLEncoder.encode方法进行编码
response.setHeader("content-disposition", "attachment;filename="+URLEncoder.encode(fileName, "UTF-8"));
FileReader in = new FileReader(realPath);
int len = 0;
char[] buffer = new char[1024];
PrintWriter out = response.getWriter();
while ((len = in.read(buffer)) > 0) {
out.write(buffer,0,len);//将缓冲区的数据输出到客户端浏览器
}
in.close();
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
运行结果如下:
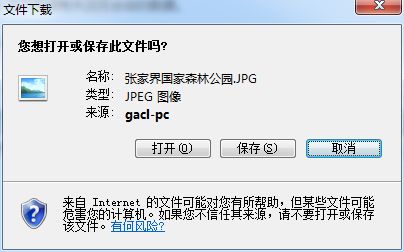
正常弹出下载框,此时我们点击【保存】按钮将文件下载下来,如下所示:
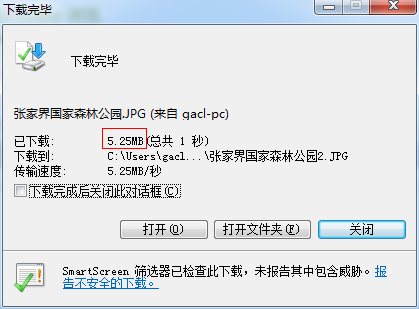
可以看到,只下载了5.25MB,而这张图片的原始大小却是
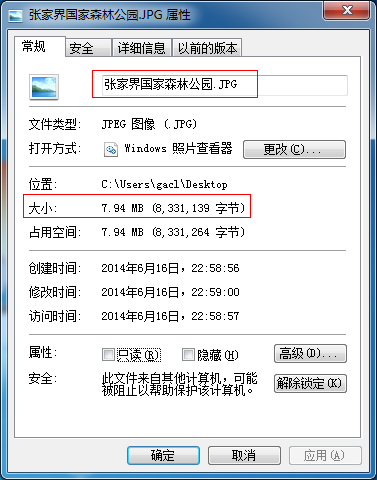
这说明在下载的时候数据丢失了,所以下载不完全,所以这张图片虽然能够正常下载下来,但是却是无法打开的,因为丢失掉了部分数据,如下所示:
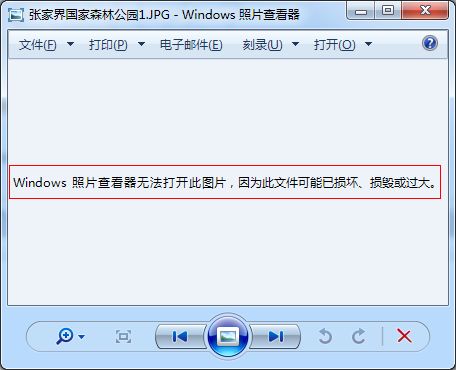
所以使用PrintWriter流处理字节数据,会导致数据丢失,这一点千万要注意,因此在编写下载文件功能时,要使用OutputStream流,避免使用PrintWriter流,因为OutputStream流是字节流,可以处理任意类型的数据,而PrintWriter流是字符流,只能处理字符数据,如果用字符流处理字节数据,会导致数据丢失。