oracle教程之oracle关于表的结构、操作、相关概念解析
oracle 表(上)
Posted on 2012-09-24 23:40 虫师 阅读( 1405) 评论( 1) 编辑 收藏
对于我们初学者来说,对表的概念也有一定的认识。因为我们对数据库的操作,90%以上是对表的操作。
常见表的类型:
规则表(Regular table),严格意义上来说又叫heap table(堆表),也就是我们最普通的一张表。
partition talbe、Index-organized table、Cluster 三种表类型,在讲解数据结构的时候有做过简单的描述,这里就不介绍,本节的重点也就是讲解普通的表。
对于一张普通的表,他的插入规则是无序,我们把数据的存储空间看成学生宿舍楼一个连一个的房间。并不是第一个来的人就一定先在第一个房间。先来的人只要发现某个房间还有床位是空的就可以入住。
那么我们如何让他变成的有序的呢?那么我可以专业创建一列来记录顺序。宿管在一楼门口发号码,进来一同学,发一个号码,上面标注几号房间几号床位。这样所有入住的同学都是有序的。
SQL> create table t 2 (a int, 3 b varchar2(4000) default rpad('*',4000,'*'), 4 c varchar2(3000) default rpad('*',3000,'*')); //创建一个表 Table created. SQL> insert into t(a) values(1); 1 row created. SQL> insert into t(a) values(2); 1 row created. SQL> insert into t(a) values(3); //插入若干条记录 1 row created. ......... SQL> select a from t; A ---------- 3 1 4 5 2 //上面查询插入的结果是无序的,如何变成的有序的呢? 加上 order by SQL> select a from t order by a; A ---------- 1 2 3 4 5
我们可以在表中添加一列用来记录行号,每添加一条数据自动加1。这样就有效保证插入有数据是有序列的。
表的字段类型划分
oracle表类型结构图:
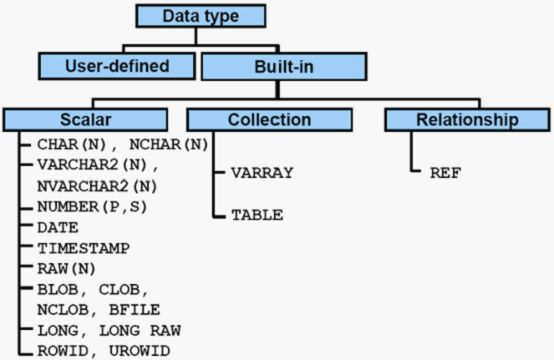
Oracle数据类型分用户自定义类型(user-defined)和内嵌类型(built-in),但我们大多时候都用内嵌类型,在极特别情况下才会用到自定义类型。
内嵌类型可以用为三大类,scalar翻译成标量,可以理解成单一的数据类型,collection 收集,这里可以理解为复合的类型,relationship 关系类型,类似于指针引用。而我们一般最常用的也就是scalar数据类型。
Scalar又可以分为四类:
字符串型char(n)、nchar(n)、varchar2(n)、nvarchar2(n)、、
数值型number(p,s)、
日期型data、timestamp
二进制类型raw(n)、blog、clob、nclob、bfile、long、long raw、
记录编号rowid、urowid
CHAR & VARCHAR2类型存储比较
char(n) n=1 to 2000字节 定长字符串,n字节长,如果不指定长度,缺省为1个字节长(一个汉字为2字节)。
varchar2(n) n=1 to 4000字节 可变长的字符串,具体定义时指最大长度n,这种数据类型可以放数字、字母以及ASCII码字符集(或者EBCDIC等数据库系统接受的字符集标准)中的所有符号。如果数据长度没有达到最大值n,Oracle 8i/9i/10g会根据数据大小自动调节字段长度,如果你的数据前后有空格,Oracle 8i会自动将其删去。VARCHAR2是最常用的数据类型。
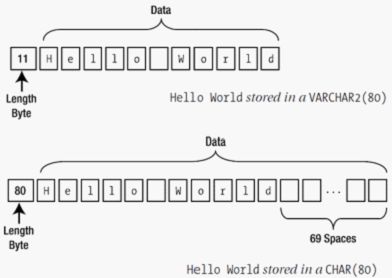
Varchar2 相比于char 在大数据的存储中就有效果的节约了很多空间。
Nchar、Nvarchar2分别是 char 与varchar2的国际版。
Rowid 字段类型
Rowid 是一行数据的一个唯一标识。
下面来做个例子,来帮助我们认识它:
SQL> sreate table f(id int,name char(10)); //创建一个表 Table created. SQL> insert into f values(0,'boobooke'); //插入几条相同人数据 1 row created. SQL> select * from f; //查看表内容 ID NAME ---------- -------------------- 0 boobooke 0 boobooke 0 boobooke SQL> select rowid,id,name from f; //查看rowid隐藏列 ROWID ID NAME ------------------ ---------- ----------------------------------------- AAAMiXAABAAAOjKAAA 0 boobooke AAAMiXAABAAAOjKAAB 0 boobooke AAAMiXAABAAAOjKAAC 0 boobooke
Rowid是一个隐藏的字段,每一张表都存在,默认查看一张数据的时候不会出现。只有特意加上rowid字段才会出现。
Rowid的结构:
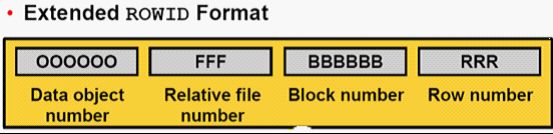
需要声明一下的是,现在的格式是9i 及以后版本的格式。
前6位(OOOOOO)为数据对象ID,一张表、一个所引都是一个数据对象,oracle都会分配给他们一个唯一的数据对象。
紧跟的3位(FFF)为相对的文件ID,我们知道表空间是由不同的文件组成,对象存储的某个文件里,每个文件会对应一个ID号
再接着的6位(BBBBBB)为块ID ,文件是由块组成的,每个块也有一个唯一的ID编号。
最后3位(RRR)为行ID ,每个块又可划分成行,每个行也有一个ID号。
其他类型介绍
1 number(m,n) m=1 to 38,n=-84 to 127 可变长的数值列,允许0、正值及负值,m是所有有效数字的位数,n是小数点以后的位数。如:number(5,2),则这个字段的最大值是99999,如果数值超出了位数 限制就会被截取多余的位数。如:number(5,2),但在一行数据中的这个字段输入575.316,则真正保存到字段中的数值是575.32。如:number(3,0),输入575.316,真正保存的数据是575。
2 date 无 从公元前4712年1月1日到公元4712年12月31日的所有合法日期,Oracle 8i/9i/10g其实在内部是按7个字节来保存日期数据,在定义中还包括小时、分、秒。缺省格式为DD-MON-YY,如07-11月-00 表示 2000年11月7日。
3 Long:可变长字符列,最大长度限制是2GB,用于不需要作字符串搜索的长串数据,如果要进行字符搜索就要用varchar2类型。
long是一种较老的数据类型,将来会逐渐被BLOB、CLOB、NCLOB等大的对象数据类型所取代。
4 raw(n) n=1 to 2000 可变长二进制数据,在具体定义字段的时候必须指明最大长度n,Oracle 8/9i用这种格式来保存较小的图形文件或带格式的文本文件,如Miceosoft Word文档, 以及音频、视频等非文本文件。
raw是一种较老的数据类型,将来会逐渐被BLOB、NCLOB等大的对象数据类型所取代。
5 long raw 可变长二进制数据,最大长度是2GB。Oracle 8i/9i用这种格式来保存较大的图形文件或带格式的文本文件,如Miceosoft Word文档,以及音频、视频等非文本文件。
在同一张表中不能同时有long类型和long raw类型,long raw也是一种较老的数据类型,将来会逐渐被BLOB、NCLOB等大的对象数据类型所取代。
6 blob clob nclob
三种大型对象(LOB),用来保存较大的图形文件或带格式的文本文件,如Miceosoft Word文档,以及音频、视频等非文本文件,最大长度是4GB。LOB有几种类型,取决于你使用的字段的类型,Oracle 9i/10g实实在在地将这些数据存储在数据库内部保存。可以执行读取、存储、写入等特殊操作。
7 bfile 无 在数据库外部保存的大型二进制对象文件,最大长度是4GB。这种外部的LOB类型,通过数据库记录变化情况,但是数据的具体保存是在数据库外部进行的。Oracle 8i/9i/10g可以读取、查询BFILE,但是不能写入。大小由操作系统决定。
8 LONG型:此数据类型用来存储可变长度的字符数据,最多能存储2GB。但是有一些限制:一个表中只有一列可以为LONG型,LONG列不能定义为主键或唯一约束,不能建立索引,过程或存储过程不能接受LONG数据类型的参数。
9 LOB数据类型
● LOB又称为“大对象”数据类型:主要有CLOB,BLOB(NBLOB),BFILE,三种子类型。
● CLOB代表(CHARACTER LOB),它能够存储大量字符数据,可以存储非结构化的XML文档。
● BLOB代表(BINARY LOB),它可以存储较大的二进制对象;如图形,音视频剪辑。
关于表的一些信息
Oracle规定一张表最多可以有1000列,但一般在我们设计表的时候根本不需这么多列,如果你真这么干了,很有可能你的设计不合理,要么就是极其特别的情况下需要这么做。对一个表的列数设计的越少,oracle 对表的操作性能越高。如果表的列数超过254列的时候,oracle在存放的时候分多个行片(row pieces),当你在读的时候,oracle将这些生片重新组装产生一个完整的列。
Oracle对一张表存储的行数没有限制,理论上是无限的。但我们会受到其它的限制,如磁盘空间、内存等。例如,一个表这空间最多可以包含1022个文件(当然,oracle10g中有一个BIGFILE 表空间使文件的数量大大增加,超过了1022的限制)假设你的每个文件是32GB,那一个表空间可以放32*1022=32704GB ,这将是2143289344个数据块,假设第个块16KB,一个块可以放160条记录,一行80到100个字节,那么一个表空间可存放342926295040行数据。Oracle还提供了分区表的功能,一个表可以拆分成1024个分区表,那么最大值是1024*342926295040行数据。这只是个理论最大值。
索引是依附于表的,索引就是把不同列组合起来。在一张表中创建所引的个数理论上是无限的。
那么一个数据库可以放多少张表?这个理论上也是无限,但一个数据库中不可能有上百万张表,这样对于创建与维护几乎是不可能的。但对于大型数据库来说有几千张表是完全可能。
一列数据在数据块中的存储:
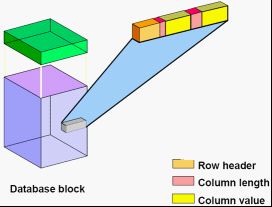
Row header :存储一行中有多少行的信息,链接信息和 行锁的信息。
Column length : 用来存储列的长度。
Column value : 用来存储列的值。
需要说明一点的是,此处讲表,更多的是一些概念与管理,至于创建的参数细节更多与业务有关。
创建表
创建一个表,create table 命令说简单将非常简单,说复杂巨复杂,在实际的生产中,并不像我们前面创建一个表那简单的指定两个个字段就OK了。而且我们前面介绍的那么多种表的类型也是这一条命令稿定的。
创建自动管理与手动管理两个表空间:
创建个一个自动管理的表空间: SQL> create tablespace assm datafile 2 '/ora10/product/oradata/ora10/assm_1.dbf' size 100M 3 extent management local uniform size 128k segment space management auto ; 创建一个手动管理的表空间: SQL> create tablespace mssm datafile 2 '/ora10/product/oradata/ora10/mssm_1.dbf' size 100M 3 extent management local uniform size 128k segment space management manual ; 查看创建的表空间: SQL> !ls -l /ora10/product/oradata/ora10 总计 1189996 -rw-r----- 1 ora10 dba 104865792 09-24 21:54 assm_1.dbf -rw-r----- 1 ora10 dba 104865792 09-24 22:01 mssm_1.dbf .............................
创建两个用户:
用户名密码都为:as1 SQL> create user as1 identified by as1 default tablespace assm; User created. 用户名密码都为:ms1 SQL> create user ms1 identified by ms1 default tablespace mssm; User created. 为两个用户赋予权限: SQL> grant connect,resource to as1; Grant succeeded. SQL> grant connect,resource to ms1; Grant succeeded.
用创建的用户登录:
登录: SQL> conn as1/as1 Connected. 查看当前用户: SQL> show user USER is "AS1" create table tt(id int,name char(10)) storage(initial 128k next 128k pctincrease 0 minextents 1 maxextents 5) tablespace assm;
创建一个表:
创建一个表,加一些参数限定: SQL> create table tt(id int,name char(10)) 2 storage(initial 128k next 128k pctincrease 0 minextents 1 maxextents 5) tablespace assm; SQL> select segment_name,segment_type from user_segments; SEGMENT_NAME SEGMENT_TYPE -------------------------------------------------------------------------------- TT TABLE
添加这些参数的指定值会影响数据库的性能。
Initial 当前的extents 大小为128KB
Next 随着表数据的增加会申请新extents ,申请的下一个extents 的大小。
Pctincrease 增长的百分比,这个参数一般默认情况下为0 。
Minextents 表示这个表最少只能有1个extents
Maxextents 表示最多可以有5个extents
tablespace assm 指定当前表所属的表空间为 assm ,其实默认不指定也是assm表空间,因为当前的用户权限范围已经指定为assm表空间。
其实,对于assm(自动管理)表空间来说,修改上面的参数是无效的,。但对于mssm(手动管理)的表空间就会起作用,在非常了解数据库的情况下,调整参数会提高数据库的性能。
创建表的原则
* 把表放在不同的表空间里
* 减少磁盘空间碎片(定期整理碎片,不同对象整理方式也不同)
* 尽量少使用几种标准的extents 盘区,用于减少磁盘空间。
* 使用临时表
临时表
什么是临时表,用户做一个操作查询出几百几千条数据,我们可以把数据放在内存中。当有很多用户都这样做,内存空间不足,这个时候就需要把数据保存在磁盘上。对于oracle就提供了一种临时表用于存放这些数据。
创建临时表:
创建 SQL> create global temporary table hr.employees_temp ; 查看 SQL>select * from hr.employees_temp ; 也可以把上面两句合并 SQL> create global temporary table hr.employees_temp as select * from hr.employees_temp ;
一个session 可以包含多个事务。那么临时表的生命周期只作用于一个事务或一个session (会话)。 事务临时表与会话临时表级别不同,也会有一些差异。
对于临时表不用加DML锁,相对速度会比普通表快。
临时表你可以创建索引、视图和触发器。
这里我们需要理解:当我们创建一个普通的表时,系统会给我们分配存储空间,我们创建临时表的时候不会分配空间,更像是创建的一种规则,当用户使用时会生成临时表,他们放不同的临时表空间中 ,所以每个用户的临时表只有自己可看到。
临时表也会产生undo 和redo信息,但它产生的redo信息要远远小于普通表。
下面演示创建一个事务级别与会话级别的两个临时表,(这个演示有点啰嗦,但完全可以根据下面的步骤,操作验证。)
SQL> conn as1/as1 登录用户 Connected. SQL> desc tt; 查看tt表结构 Name Null? Type ----------------------------------------- -------- ---------------------------- ID NUMBER(38) NAME CHAR(10) 创建sessione级别的临时表 SQL> create global temporary table tmp_session on commit preserve rows as select * from tt where 1=0; Table created. on commit preserve rows 表示创建的表是session 级别,只要用户不退出,临时表一直有效。 select * from tt where 1=0; 将tt表的结构拷贝过来使用
创建事务级别的临时表
SQL> create global temporary table tmp_transaction on commit delete rows as select * from tt where 1=0; Table created. on commit delete rows 表示创建的表是事务级别,这个临时表的作用范围只在一个事务内有效。
验证两种临时表的作用范围:
SQL> select * from tt; no rows selected //查看tt表为空 向表中插入两条数据: SQL> insert into tt values(0,'chongshi'); 1 row created. SQL> insert into tt values(1,'chongshi'); 1 row created. SQL> commit; //提交事务 Commit complete. SQL> select * from tt; //查看表中插入的数据 ID NAME ---------- -------------------- 0 chongshi 1 chongshi ---------------------------------------------------------------------------------------------------------------------------------------- //把tt表信息放到session级别临时表中 SQL> insert into tmp_session select * from tt; 2 rows created. //把tt表信息放到事务级别临时表中 SQL> insert into tmp_transaction select * from tt; 2 rows created. //查看两张表信息: SQL> select count(*) from tmp_session; COUNT(*) ---------- 2 SQL> select count(*) from tmp_transaction; COUNT(*) ---------- 2 //我们可以看到session临时表与事务临时表都是有数据的。 SQL> commit; //提交事务 Commit complete. //再来查看两张临时表信息: SQL> select count(*) from tmp_session; COUNT(*) ---------- 2 //session级别的临时表依然有数据 SQL> select count(*) from tmp_transaction; COUNT(*) ---------- 0 //事务级别的临时表数据消失了。 SQL> quit 退出 Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production With the Partitioning, OLAP and Data Mining options [ora10@localhost /]$ sqlplus as1/as1 重新登录 SQL*Plus: Release 10.2.0.1.0 - Production on Sat Oct 6 12:20:08 2012 Copyright (c) 1982, 2005, Oracle. All rights reserved. Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production With the Partitioning, OLAP and Data Mining options SQL> select count(*) from tmp_session; COUNT(*) ---------- 0 再来查看session 级别的临时表也变为空了。
行迁移与链接
Row Migration
在前面的学习中有介绍到数据块的概念,块中存放着一条一条的数据,每个数据块都会预留的有剩余的空间用一条数据的扩展。
当剩余的空间不够一条数据的扩展时,那么这条数据就需要迁移,迁移到可存放这条数据的数据块中。那么怎样找到新数据的位置呢,就需要在原来存放数据的位置放一个指针,用于指向新的数据。迁移数据带来的后果就是oracle的性能下降。
Row Chaining
如果一条记录的某列内容非常长了,任何一个块都放不下。Oracle会把他们分成不同的部分,每一部分被称为行片(row pieces)。每一个块中都会有指针帮助oracle组装成一条完整的记录。造成row chaining的根本原因是因为数据块设置的太小了。Row chaining同样会造成oracle的性能下降。
如果减少row chaining一种方法是可以甚至增加块的大小,加一个种方法是将表拆分成多个小表。
表操作
修改表的参数
SQL> alter table hr.employees Ppctfree 30 pctused 50 Storage(next 500k minextents 2 maxextents 100);
需要注意的是此设置不会对已经存在的数据造成影响,只会规定到新创建的数据。
手动的为一个表分配盘区
SQL> alter table hr.employees Allocate extent(size 500k datafile '/disk3/data01.dbf');
extent(size 500k datafile '/disk3/data01.dbf') 用于指这在哪个数据文件中指定盘区以及大小。
表的改编
一张表可能由于我们初始设置不当,或者由于后期业务发生改变,表的机构需要调整与重新组织。
重新组织命令:
SQL> alter table hr.employees move tablespace data1;
演示:此命令只对普通的表有用,或分区表中的一个表有用。
SQL> show user; USER is "AS1" //查看当前用户下的表 SQL> select table_name from user_tables; TABLE_NAME TABLESPACE_NAME -------------------------------------------------------------------------------------- TT ASSM TMP_SESSION TMP_TRANSACTION SQL> select * from tt; //查看表结构 ID NAME ---------- -------------------- 0 chongshi 1 chongshi 将表移动另一个表空间 SQL> alter table tt move tablespace mssm; Table altered. /*在本章的开始,我们创建了两个表空间,自动管理表空间(ASSM)与手动管理表空间(MSSM)*/ //再来查看当用户下的表: SQL> select table_name from user_tables; TABLE_NAME TABLESPACE_NAME -------------------------------------------------------------------------------------- TMP_SESSION TMP_TRANSACTION TT MSSM
那么对表的改编有很多方法,一种就是导出、导入。一种创建一个新表,将数据一列一列的移动到新表中。
清空表
Truncating a table 相当把表中的内容全部清空,但表及其结构依然存在,像刚创建的一个新表。
SQL> truncate table hr.employees;
清空表不会产生undo信息,也就是执行些操作无法进行回滚,只能通过其它办法恢复数据。
表的索引也会被一并清掉。
如果一个表被外界引用,那么它就不能被truncate。
删除表
Dropping a table
SQL> drop table hr.employees cascade constraints;
如果这个表被删除掉,那么它占用的空间也会被释放。
如果要删除的表与其它表有关联,则需要加上cascade constraints 命令
删除一列数据
Dropping a column 的操作使用不是很频繁,但也需要知道如何操作。
SQL> alter table hr.employees drop column comments cascade constraints checkpoint 1000;
删除列操作会产undo信息,如果数据量过大可能会把undo表空间撑满,checkpoint 1000 会每执行1000条数据发起一个检查点,发起检查点就是会把操作的数据写到磁盘的数据文件中。