PPAS命令行迁移工具
1
从其它数据库迁移到PPAS时可迁移的数据库对象间下表
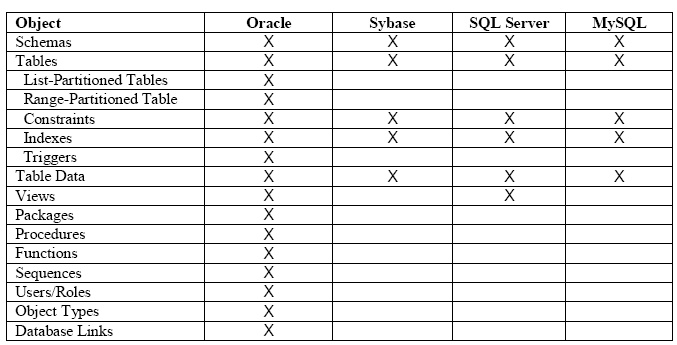
2
安装ppas时会有安装migreation toolkit的选项,可以选择安装,也可以到www.enterprisedb.com下载安装
3
编辑/opt/PostgresPlus/9.2AS/etc/toolkit.properties
linux-np3p:/opt/PostgresPlus/9.2AS # cat -netc/toolkit.properties
SRC_DB_URL=jdbc:oracle:thin:@192.168.1.127:1521:orcl
SRC_DB_USER=testuser
SRC_DB_PASSWORD=testuserpw
TARGET_DB_URL=jdbc:edb://localhost:5444/testdb1
TARGET_DB_USER=testuser
TARGET_DB_PASSWORD=123456
linux-np3p:/opt/PostgresPlus/9.2AS #
4
拷贝oracle的jdbc接口驱动到/opt/PortgresPlus/9.2AS/jre/lib/ext里面
注意要拷贝和jre版本对应的驱动程序
5
迁移
linux-np3p:/opt/PostgresPlus/9.2AS/bin #./runMTK.sh testuser
源数据库连接信息...
连接=jdbc:oracle:thin:@192.168.1.127:1521:orcl
用户 =TESTUSER
密码=******
目标数据库连接信息...
连接=jdbc:edb://localhost:5444/testdb2
用户 =testuser
密码=******
正在连接源Oracle数据库服务器...
正在连接目标EnterpriseDB数据库服务器...
正在导入 Redwood 架构 testuser...
正在创建架构...testuser
正在创建表...
正在创建表: TEST1
已创建 1 个表。
正在以 8 MB 批次大小加载表数据...
正在加载表: TEST1...
[TEST1] 已迁移 2 行。
[TEST1] 表数据加载摘要: 时间总计 (秒): 0.375 行数总计: 2
数据加载摘要: 时间总计 (秒): 1.111 行数总计: 2 大小总计 (MB): 0.0
已成功导入架构testuser。
正在创建用户:TESTUSER
创建用户 TESTUSER 时发生错误
在迁移进程中有一至多个架构对象无法导入。有关更多详细信息,请参阅迁移输出信息。
迁移日志已保存到/root/.enterprisedb/migration-toolkit/logs
******************** 迁移摘要 ********************
Tables: 1 来自 1
Users: 0 来自 1
全部对象: 2
成功计数: 1
失败计数: 1
失败对象列表
======================
Users
--------------------
1. TESTUSER
*************************************************************
6
查询迁移结果
linux-np3p:/opt/PostgresPlus/9.2AS/bin #./psql -U testuser testdb1
用户 testuser 的口令:
psql (9.2.0.1)
输入"help" 来获取帮助信息.
testdb2=# select * from test1;
id| xname
----+--------------
1 |test / gaga
2 |test / gaga
(2 行记录)
testdb2=#
7
下面是runMTK.sh的内容,可以看到调用了工具edb-migrationtoolkit.jar
# ----------------------------------------------------------------------------
# --
# -- Copyright (c) 2004-2012 - EnterpriseDBCorporation. All Rights Reserved.
# --
#----------------------------------------------------------------------------
/opt/PostgresPlus/9.2AS/jre/bin/java -Dprop=../etc/toolkit.properties-jar edb-migrationtoolkit.jar "$@"
8
下面是migreationtoolkit的帮助信息,列出了可选参数
linux-np3p:/opt/PostgresPlus/9.2AS #jre/bin/java -jar bin/edb-migrationtoolkit.jar -help
EnterpriseDB Migration Toolkit (Build 46)
用法: runMTK [-选项] SCHEMA
若未指定任何选项,则将导入完整的架构。
其中,选项包括:
-help 显示应用程序的命令行用法。
-version 显示应用程序版本信息。
-verbose [on|off] 以标准输出显示应用程序日志消息 (默认值: on)。
-schemaOnly 只导入架构对象定义。
-dataOnly 只导入表数据。若指定了 -tables,则只导入所选表的数据。注意: 如果对目标表定义了任何外键约束,则此选项需与 -truncLoad 选项一起使用。
-sourcedbtype db_type The -sourcedbtypeoption specifies the source database type. db_type may be one of the followingvalues: mysql, oracle, sqlserver, sybase, postgresql, enterprisedb. db_type iscase-insensitive. By default, db_type is oracle.
-targetdbtype db_type The -targetdbtypeoption specifies the target database type. db_type may be one of the followingvalues: oracle, sqlserver, postgresql, enterprisedb. db_type iscase-insensitive. By default, db_type is enterprisedb.
-allTables 导入所有表。
-tables LIST 导入以逗号分隔的表列表。
-constraints 导入表约束。
-indexes 导入表索引。
-triggers 导入表触发器。
-allViews 导入所有视图。
-views LIST 导入以逗号分隔的视图列表。
-allProcs 导入所有存储过程。
-procs LIST 导入以逗号分隔的存储过程列表。
-allFuncs 导入所有函数。
-funcs LIST 导入以逗号分隔的函数列表。
-allPackages 导入所有包。
-packages LIST 导入以逗号分隔的包列表。
-allSequences 导入所有序列。
-sequences LIST 导入以逗号分隔的序列列表。
-targetSchema NAME 目标架构的名称 (默认: 目标架构以源架构命名)。
-allDBLinks 导入所有数据库链接。
-allSynonyms It enables the migration of all public and private synonyms from anOracle database to an Advanced Server database. If a synonym with the same name already exists in the target database,the existing synonym will be replaced with the migrated version.
-allPublicSynonyms It enables the migration of all public synonyms from an Oracledatabase to an Advanced Server database. If a synonym with the same name already exists in the target database,the existing synonym will be replaced with the migrated version.
-allPrivateSynonyms It enables the migration of all private synonyms from an Oracledatabase to an Advanced Server database. If a synonym with the same name already exists in the target database,the existing synonym will be replaced with the migrated version.
-dropSchema [true|false] 若架构已存在于目标数据库中,则删除此架构 (默认值: false)。
-truncLoad 此选项对目标表禁用任何约束,并且在导入新数据之前先截断表中的数据。此选项只能与 -dataOnly 一起使用。
-safeMode 使用纯 SQL 语句,以安全模式传输数据。
-copyDelimiter 在加载表数据时,指定一个字符作为复制命令中的分隔符。默认值为 \t
-batchSize 指定“批量插入”要使用的“批次大小”。有效值为 1-1000,默认批次大小为 1000,如果出现“内存不足”异常,则可以降低此值
-cpBatchSize 指定复制命令要使用的“批次大小”,以 MB 为单位。有效值大于 0,默认批次大小为 8 MB
-fetchSize 指定提取大小 (每次应从结果集中提取的行数)。当数据表含有数百万个行,而您想避免发生内存不足错误时,可以使用此选项。
-filterProp 包含表 where 子句的属性文件。
-skipFKConst 跳过外键约束的迁移。
-skipCKConst 跳过检查约束条件的迁移。
-ignoreCheckConstFilter 在缺省的情况下MTK不从Sybase中迁移检查约束和缺省子句,使用这个选项可以关闭这个过滤功能。
-fastCopy 略过 WAL 日志记录,以优化方式执行 COPY 操作,默认情况下禁用。
-customColTypeMapping LIST 使用以分号分隔的列表表示的自定义类型映射,其中每个条目都使用 COL_NAME_REG_EXPR=TYPE 对来指定,例如 .*ID=INTEGER
-customColTypeMappingFile PROP_FILE 由属性文件表示的自定义类型映射,其中每个条目都使用 COL_NAME_REG_EXPR=TYPE 对来指定,例如 .*ID=INTEGER
-offlineMigration [DDL_PATH] 这将执行脱机迁移并将 DDL 脚本保存在文件中供以后执行。默认情况下,如果要求后跟-offlineMigration 选项以及自定义路径,则脚本文件将保存在用户主文件夹下。
-logDir LOG_PATH 指定用于保存日志文件的自定义路径。默认情况下,日志文件保存在工作目录中的“logs”文件夹下。
-copyViaDBLinkOra 此选项可用来通过使用 dblink_ora COPY 命令复制数据。此选项仅限用在从 Oracle 到 EnterpriseDB 迁移模式中。
-singleDataFile Use single SQL file for offline data storage for all tables.This option cannot be used in COPY format.
-allUsers 从源数据库导入所有用户和角色。
-users LIST 从源数据库导入选定用户/角色。LIST 是一个用逗号分隔的用户/角色名称列表,如 -users MTK,SAMPLE
-allRules 从源数据库导入所有规则。
-rules LIST 从源数据库导入选定规则。 LIST 是一个用逗号分隔的名称列表,如 -rules high_sal_emp,low_sal_emp
-allGroups 从源数据库导入所有组。
-groups LIST 从源数据库导入选定组。 LIST 是一个用逗号分隔的组名称列表,如 -groups acct_emp,mkt_emp
-allDomains 从源数据库导入所有域、枚举和复合类型。
-domains LIST 从源数据库导入所选域、枚举和复合类型。 LIST 是一个用逗号分隔的域名称列表,如 -domainsd_email,d_dob, mood
-objecttypes 导入用户定义的对象类型。
-replaceNullChar <CHAR> 如果空字符是列值得一部分,那么通过JDBC协议迁移数据就会失败.这个选项可以使用用户指定的字符来替代空字符串。
-importPartitionAsTable [LIST] 通过使用这个选项能够将Oracle中的分区表以常规表的形式导入到EnterpriseDB中。为了在所选择表集合上的应用规则,在选项后面应跟随以逗号分隔的表名列表。
-enableConstBeforeDataLoad 通过使用这个选项可以在数据导入前重新启用约束(和触发器).当要迁移的表在EnterpriseDB中对应的是一张分区表时,使用这个选项是非常有用的。
-checkFunctionBodies [true|false] 设置为 false 时,将禁用创建函数过程中的函数体验证,从而避免在函数包含向前参考时发生错误。 目标数据库为 Postgres/EnterpriseDB 时适用,默认值为 true。
-retryCount VALUE 指定 MTK 迁移由于跨架构相关性而失败的对象的重试次数。 VALUE 参数应该大于 0,默认值为 2。
-analyze 它将对目标 Postgres 或 Postgres Plus Advanced Server 数据库调用 ANALYZE 操作。 ANALYZE 收集用于有效查询计划的迁移表的统计信息。
-vacuumAnalyze 它将对目标 Postgres或 PostgresPlus Advanced Server 数据库调用 VACUUM 和 ANALYZE 操作。 VACUUM 回收非活动元组存储,ANALYZE 收集用于有效查询计划的迁移表的统计信息。
-loaderCount VALUE 指定并行执行数据加载的作业(线程)数目。 VALUE 参数应该大于 0,默认值为 1。
数据库连接信息:
应用程序将从文件toolkit.properties中读取源和目标数据库服务器的连接信息.
更多的信息参见MTK的自述文档.
linux-np3p:/opt/PostgresPlus/9.2AS #
9
如果看中午帮助信息有歧义就看下面的英文帮助信息吧
[email protected]]# jre/bin/java -jar bin/edb-migrationtoolkit.jar -help
EnterpriseDBMigration Toolkit (Build 46)
Usage: runMTK[-options] SCHEMA
If no option isspecified, the complete schema will be imported.
where optionsinclude:
-help Display the application command-lineusage.
-version Display the application versioninformation.
-verbose[on|off] Display application log messages on standard output (default: on).
-schemaOnly Import the schema object definitions only.
-dataOnly Import the table data only. When -tables is inplace, it imports data only for the selected tables. Note: If there are any FKconstraints defined on target tables, use -truncLoad option along with thisoption.
-sourcedbtypedb_type The -sourcedbtype option specifies the source database type. db_typemay be one of the following values: mysql, oracle, sqlserver, sybase,postgresql, enterprisedb. db_type is case-insensitive. By default, db_type isoracle.
-targetdbtypedb_type The -targetdbtype option specifies the target database type. db_typemay be one of the following values: oracle, sqlserver, postgresql,enterprisedb. db_type is case-insensitive. By default, db_type is enterprisedb.
-allTables Import all tables.
-tables LIST Import comma-separated list of tables.
-constraints Import the table constraints.
-indexes Import the table indexes.
-triggers Import the table triggers.
-allViews Import all Views.
-views LIST Import comma-separated list of Views.
-allProcs Import all stored procedures.
-procs LIST Import comma-separated list of storedprocedures.
-allFuncs Import all functions.
-funcs LIST Import comma-separated list of functions.
-allPackages Import all packages.
-packages LISTImport comma-separated list of packages.
-allSequences Import all sequences.
-sequences LISTImport comma-separated list of sequences.
-targetSchemaNAME Name of the target schema (default: target schema is named after sourceschema).
-allDBLinks Import all Database Links.
-allSynonyms It enables the migration of all public andprivate synonyms from an Oracle database to an Advanced Server database. If a synonym with the same name alreadyexists in the target database, the existing synonym will be replaced with themigrated version.
-allPublicSynonyms It enables the migration of all publicsynonyms from an Oracle database to an Advanced Server database. If a synonym with the same name alreadyexists in the target database, the existing synonym will be replaced with themigrated version.
-allPrivateSynonyms It enables the migration of all privatesynonyms from an Oracle database to an Advanced Server database. If a synonym with the same name alreadyexists in the target database, the existing synonym will be replaced with themigrated version.
-dropSchema[true|false] Drop the schema if it already exists in the target database(default: false).
-truncLoad It disables any constraints on target table andtruncates the data from the table before importing new data. This option canonly be used with -dataOnly.
-safeMode Transfer data in safe mode using plain SQLstatements.
-copyDelimiter Specify a single character to be used asdelimiter in copy command when loading table data. Default is \t
-batchSize Specify the Batch Size to be used by the bulkinserts. Valid values are 1-1000,default batch size is 1000, reduce if you run into Out of Memory exception
-cpBatchSize Specify the Batch Size in MB, to be usedin the Copy Command. Valid value is > 0, default batch size is 8 MB
-fetchSize Specify fetch size in terms of number of rowsshould be fetched in result set at a time. This option can be used when tablescontain millions of rows and you want to avoid out of memory errors.
-filterProp The properties file that contains table whereclause.
-skipFKConst Skip migration of FK constraints.
-skipCKConst Skip migration of Check constraints.
-ignoreCheckConstFilter By default MTK does not migrate Checkconstraints and Default clauses from Sybase, use this option to turn off thisfilter.
-fastCopy Bypass WAL logging to perform the COPYoperation in an optimized way, default disabled.
-customColTypeMappingLIST Use custom type mapping representedby a semi-colon separated list, where each entry is specified usingCOL_NAME_REG_EXPR=TYPE pair. e.g. .*ID=INTEGER
-customColTypeMappingFilePROP_FILE The custom type mappingrepresented by a properties file, where each entry is specified usingCOL_NAME_REG_EXPR=TYPE pair. e.g. .*ID=INTEGER
-offlineMigration[PATH] This performs offline migration and saves the DDL/DML scripts in filesfor a later execution. By default the script files will be saved under userhome folder, if required follow -offlineMigration option with a custom path.
-logDirLOG_PATH Specify a custom path to save the log file. By default, on Linux thelogs will be saved under folder $HOME/.enterprisedb/migration-toolkit/logs. Incase of Windows logs will be saved under folder%HOMEDRIVE%%HOMEPATH%\.enterprisedb\migration-toolkit\logs.
-copyViaDBLinkOraThis option can be used to copy data using dblink_ora COPY commad. This optioncan only be used in Oracle to EnterpriseDB migration mode.
-singleDataFile Use single SQL file for offline data storagefor all tables. This option cannot be used in COPY format.
-allUsersImport all users and roles from the source database.
-users LISTImport the selected users/roles from the source database. LIST is acomma-separated list of user/role names e.g. -users MTK,SAMPLE
-allRulesImport all rules from the source database.
-rules LISTImport the selected rules from the source database. LIST is a comma-separatedlist of rule names e.g. -rules high_sal_emp,low_sal_emp
-allGroupsImport all groups from the source database.
-groups LISTImport the selected groups from the source database. LIST is a comma-separated listof group names e.g. -groups acct_emp,mkt_emp
-allDomainsImport all domain, enumeration and composite types from the source database.
-domains LISTImport the selected domain, enumeration and composite types from the sourcedatabase. LIST is a comma-separated list of domain names e.g. -domainsd_email,d_dob, mood
-objecttypes Import the user-defined object types.
-replaceNullChar<CHAR> If null character is part of a column value, the data migrationfails over JDBC protocol. This option can be used to replace null characterwith a user-specified character.
-importPartitionAsTable[LIST] Use this option to import Oracle Partitioned table as a normal table inEnterpriseDB. To apply the rule on a selected set of tables, follow the optionby a comma-separated list of table names.
-enableConstBeforeDataLoadUse this option to re-enable constraints (and triggers) before data load. Thisis useful in the scenario when the migrated table is mapped to a partitiontable in EnterpriseDB.
-checkFunctionBodies[true|false] When set to false, it disables validation of the function bodyduring function creation, this is to avoid errors if function contains forwardreferences. Applicable when target database is Postgres/EnterpriseDB, defaultis true.
-retryCountVALUE Specify the number of re-attemptsperformed by MTK to migrate objects that failed due to cross-schemadependencies. The VALUE parameter should be greater than 0, default is 2.
-analyze It invokes ANALYZE operation against a targetPostgres or Postgres Plus Advanced Server database. The ANALYZE collectsstatistics for the migrated tables that are utilized for efficient query plans.
-vacuumAnalyze It invokes VACUUM and ANALYZE operationsagainst a target Postgres or Postgres Plus Advanced Server database. The VACUUMreclaims dead tuple storage whereas ANALYZE collects statistics for themigrated tables that are utilized for efficient query plans.
-loaderCountVALUE Specify the number of jobs(threads) to perform data load in parallel. The VALUE parameter should begreater than 0, default is 1.
DatabaseConnection Information:
The applicationwill read the connectivity information for the source and target databaseservers from toolkit.properties file.
Refer to MTKreadme document for more information.