字节、字节序、内存对齐 与 跨机器、网络传输、字符操作
无符号单字节 byte ,数据上表示是0x10 ,2位。
◆ 多字节基本类型,涉及到字节序little-endian和big-endian问题。(0x 01 02 0A 或 0x 0A 02 01)
主机字节序:由CPU确定多字节类型数据在内存中的存放顺序,我们用的IntelCPU是little-endian。通常这是机器内部事物,但如果涉及到网络通信就不是了。
JAVA字节序:JAVA虚拟机中的多字节类型数据在虚拟机中的存放顺序。JAVA虚拟机存储的字节流是big-endian。
网络字节序:网络传送的数据按Internet标准是big-endian解析的。和JAVA虚拟机(注意是机器不是语言)相同,和IntelCPU相反。
- 如果是单纯的Intel PC机对Intel PC机串口通信,不用考虑字节序的转换,哪怕网络数据流在Internet标准中是反的。但在http应用和未知平台的通信,最好转为网络字节序。同样,接收平台如果是Intel PC机,也再转一次。保证传输过程中的规范统一。
- ANSI C 提供了四个转换字节序的宏:htonl htons 和 ntohs ntohl (h—host、 n—net),对32位整形和短整形进行转换。
- 运行在Intel PC机上的JAVA虚拟机与Internet通信不用考虑这一问题。
这里有一段W. Richard Stevens的代码,用于判断字节序
#include <stdio.h>
#include <stdlib.h>
/*
* return value:
* 1 big-endian
* 2 little-endian
* 3 unknow
* 4 sizeof( unsigned short int ) != 2
*/
staticintbyte_order ( void)
{
union
{
unsignedshortints;
unsignedcharc[sizeof( unsigned shortint) ];
} un;
un.s = 0x0201;
if( 2 == sizeof( unsigned shortint) )
{
if( ( 2 == un.c[0] ) && ( 1 == un.c[1] ) )
{
puts("big-endian");
return( 1 );
}
elseif( ( 1 == un.c[0] ) && ( 2 == un.c[1] ) )
{
puts("little-endian");
return( 2 );
}
else
{
puts("unknow");
return( 3 );
}
}
else
{
printf("sizeof( unsigned short int ) = %u\n", ( unsigned int)sizeof(unsignedshortint) );
return( 4 );
}
return( 3 );
}/* end of byte_order */
|
◆ 数据对齐 (因为结构体的组织)
32位机CPU的数据线为32位,因此地址线只接受4的倍数的地址。数据对齐,是指WORD类型数据总是存放在2倍数的地址,DWORD类型数据总是存放在4倍数的地址,大于32位的类型数据也总是存放在4倍数的地址。目的是存取一个类型数据,存取的次数尽量少。
值得注意的是C++里的struct结构体内部分量的对齐。(在移植程序时需要特别考虑,写网络程序也很重要):
- ANSI C保证struct内部分量按声明顺序递增,不会添加虚函数表等物,但不保证内部分量的地址是严格的= struct首地址+偏移量。存放时编译器可能会自动对齐,偏移分量,改变其地址。
- 如何对齐可以设置:project->setting->c/c++标签->code generation分类->struct member alignment中设置对齐模数1,2,4,8,16byte。
- 也可以在程序中通过伪指令#paragram pack(n)语句,改变某部分结构体的对齐设置;#pragma pack (),取消自定义字节对齐方式。
- 至于基本数据类型和整个struct结构体的对齐,VC包办了。
设置结构体字段的偏移量对齐,,如果设置的对齐模数小于最大字段的倍数,则以设置的模数为准,如设置为1,字段之间不会有任何空隙(实际上是压缩了结构体)。
当设置为为8、16时(浪费7b):

当为4时(浪费3b):

◆ 与对齐相关的一些字符串操作,memcpy、memcmp等,在asm实现的时候,把字符串的对齐部分,作为int,CPU一次存取4个byte来拷贝比较。
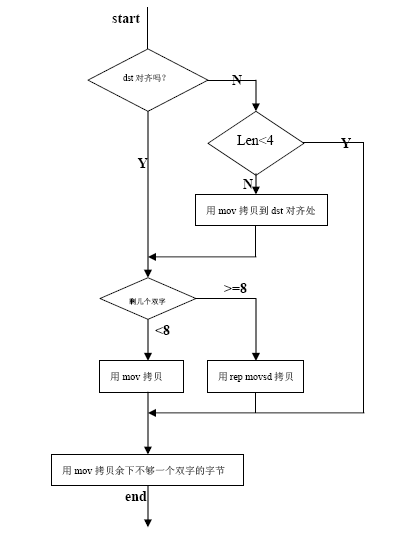
总结:
字节序与网络传输相关,为此有几个ANSI C宏;
内存对齐可以通过编译器选项和语句设置 #paragram pack(n);
即使是struct,网络传输时也不能直接“拷一堆比特”,更别提类了。