ChainMapper/ChainReducer 的实现原理

图1 ChainMapper/ChainReducer 应用实例
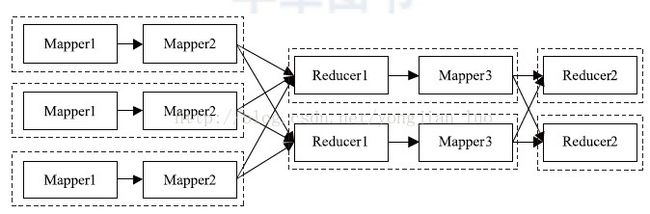
图2 一个ChainMapper/ChainReducer 不适用的场景
一个实例:
conf.setJobName("chain");
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
JobConf mapper1Conf = new JobConf(false);
JobConf mapper2Conf = new JobConf(false);
JobConf reduce1Conf = new JobConf(false);
JobConf mapper3Conf = new JobConf(false);
…
ChainMapper.addMapper(conf, Mapper1.class, LongWritable.class, Text.class,Text.
class, Text.class, true, mapper1Conf);
ChainMapper.addMapper(conf, Mapper2.class, Text.class, Text.class,
LongWritable.class, Text.class, false, mapper2Conf);
ChainReducer.setReducer(conf, Reducer.class, LongWritable.class, Text.class,Text.
class, Text.class, true, reduce1Conf);
ChainReducer.addMapper(conf, Mapper3.class, Text.class, Text.class,
LongWritable.class, Text.class, false, null);
JobClient.runJob(conf);
用户通过addMapper 在Map/Reduce 阶段添加多个Mapper。该函数带有8 个输入参数,分别是作业的配置、Mapper 类、Mapper 的输入key 类型、输入value 类型、输出key
类型、输出value 类型、key/value 是否按值传递和Mapper 的配置。其中,第7 个参数需要解释一下:Hadoop MapReduce 有一个约定,函数OutputCollector.collect(key, value) 执行期间不应改变key 和value 的值。这主要是因为函数Mapper.map() 调用完OutputCollector.collect(key, value) 之后,可能会再次使用key 和value 值,如果被改变,可能会造成潜在的错误。为了防止OutputCollector 直接对key/value 修改,ChainMapper 允许用户指定key/value 传递方式。如果用户确定key/value 不会被修改,则可选用按引用传递,否则按值传递。需要注意的是,引用传递可避免对象拷贝,提高处理效率,但需要确保key/value 不会被修改。
原文引自《Hadoop技术内幕-深入解析Mapreduce框架设计与实现原理》