3D数学之-图形渲染数学
一、图形固定管道渲染流程
// 首先设置观察场景的方式
SetupTheCamera();
// 清除深度缓存
ClearZBuffer();
// 设置环境光和雾化[如果需要]
SetGlobalLightAndFog();
//1. 世界场景级别的操作
// 得到可见物体列表
potentiallyVisibleObjectList = HighLevelVisibilityDetermination( scene );
// 2.物体三角网格级别的操作, 渲染它们
for ( all objects in
potentiallyVisibleObjectList )
{
// 使用包围盒执行低级别VSD检测
if ( !object.isBoundingVolumeVisible() ) continue;
// 提取或者渐进式生成几何体
triMesh = object.getGeometry();
// 3.三角形级别操作,裁剪和渲染面
for( each triangle in the geometry )
{
// 变换顶点到裁剪空间,执行顶点级别光照
clipSpaceTriangle = transformAndLighting( triangle );
// 三角形是背向的[现在硬件条件下很多放置到屏幕空间中根据三角形的非顺时针绕序进行剔除, 而不是裁剪空间中点击小于90度]
if ( clipSpaceTriangle.isBackFacing() ) continue;
// 对视锥裁剪三角形
clippedTriangle = clipToViewVolume( clipSpaceTriangle );
// 判断是否在视锥体内,需要用到 -w<= x <= w,-w<= y <= w, -w<= z <= w;其中w=z,都是动态的。
// 如果裁剪得到顶点少于3个(会在边界处生成裁剪顶点)那么不需要渲染, 否则需要截取顶点或者得到完整的多边形进行渲染
// 该裁剪几乎都是硬件来实现,用的是分裂三角形生成顶点的做法,必须在转换到屏幕坐标前,必须保证所有三角形都在视锥体内
if ( clippedTriangle.isEmpty() ) continue;
// 将三角形投影到屏幕空间,并且光栅化
clippedTriangle.projectToScreenSpace();
// 4.顶点级别操作
for( each pixel in the triangle )
{
// 插值颜色,z-缓存值和纹理映射坐标
// 现在硬件条件下很多在此进行背面剔除检测
// 执行zbufferinig(深度缓存检测包含了模板Stencile检测) 和 alpha检测
if( !zbufferTest() ) continue;
if ( !alphaTest() ) continue;
// 像素着色,每个像素点会根据顶点进行着色插值计算[一般是Gouraude线性插值), 启用光照情况下是否会乘以uv得到颜色?
color = shadePixel();
// 写入帧缓存区和z缓存
writePixel( color, interpolatedZ );
}
}
}
// 启用光照情况下,会将光照的得到的颜色和纹理颜色进行混合,感觉这个颜色是用纹理和光照的颜色叉乘得到的:
D3DLIGHT9 light;
::ZeroMemory(&light, sizeof(light));
light.Type = D3DLIGHT_SPOT/*D3DLIGHT_DIRECTIONAL*/;
light.Ambient = D3DXCOLOR(0.8f, 0.0f, 0.0f, 1.0f);
light.Diffuse = D3DXCOLOR(1.0f, 0.0f, 0.0f, 1.0f);
light.Specular = D3DXCOLOR(0.2f, 0.2f, 0.2f, 1.0f);
light.Direction = D3DXVECTOR3(1.0f, 1.0f, 0.0f);
light.Position = D3DXVECTOR3(10.0f, 10.0f, 0.0f);
light.Range = 1000;
light.Falloff = 1.0f;
light.Theta = 1.0f;
light.Phi = 100.0f;
Device->SetLight(0, &light);
Device->LightEnable(0, true);
Device->SetRenderState(D3DRS_NORMALIZENORMALS, true);
Device->SetRenderState(D3DRS_SPECULARENABLE, true);
HRESULT hr = D3DXCreateTextureFromFile(Device,
"crate.dds",
&Tex);
if(FAILED(hr))
{
printf("Device->CreateTexture fail.\n");
return false;
}
Device->SetSamplerState(0, D3DSAMP_MAGFILTER, D3DTEXF_LINEAR);
Device->SetSamplerState(0, D3DSAMP_MINFILTER, D3DTEXF_LINEAR);
Device->SetSamplerState(0, D3DSAMP_MIPFILTER, D3DTEXF_LINEAR);
Device->SetMaterial(&d3d::WHITE_MTRL);
Device->SetTexture(0, Tex);
// 启用光照情况下,会将光照的得到的颜色和纹理颜色进行混合,感觉这个颜色是用纹理和光照的颜色叉乘得到的:
D3DLIGHT9 light;
::ZeroMemory(&light, sizeof(light));
light.Type = D3DLIGHT_SPOT/*D3DLIGHT_DIRECTIONAL*/;
light.Ambient = D3DXCOLOR(0.8f, 0.0f, 0.0f, 1.0f);
light.Diffuse = D3DXCOLOR(1.0f, 0.0f, 0.0f, 1.0f);
light.Specular = D3DXCOLOR(0.2f, 0.2f, 0.2f, 1.0f);
light.Direction = D3DXVECTOR3(1.0f, 1.0f, 0.0f);
light.Position = D3DXVECTOR3(10.0f, 10.0f, 0.0f);
light.Range = 1000;
light.Falloff = 1.0f;
light.Theta = 1.0f;
light.Phi = 100.0f;
Device->SetLight(0, &light);
Device->LightEnable(0, true);
Device->SetRenderState(D3DRS_NORMALIZENORMALS, true);
Device->SetRenderState(D3DRS_SPECULARENABLE, true);
HRESULT hr = D3DXCreateTextureFromFile(Device,
"crate.dds",
&Tex);
if(FAILED(hr))
{
printf("Device->CreateTexture fail.\n");
return false;
}
Device->SetSamplerState(0, D3DSAMP_MAGFILTER, D3DTEXF_LINEAR);
Device->SetSamplerState(0, D3DSAMP_MINFILTER, D3DTEXF_LINEAR);
Device->SetSamplerState(0, D3DSAMP_MIPFILTER, D3DTEXF_LINEAR);
Device->SetMaterial(&d3d::WHITE_MTRL);
Device->SetTexture(0, Tex);
二、坐标空间中的视图空间、裁剪空间(透视投影)和屏幕空间
1.坐标空间、视图空间和窗口缩放
Mmodel -> MMworld
Mworld -> Mview
Mview -> Mclip
Mclip -> Mscreen
坐标空间和变换矩阵都比较清晰了,但是具体的原点在哪里,方向设定在具体引擎中还要具体分析。
窗口的像素纵横比为窗口分辨率,窗口的物理比是纵横像素的大小乘以纵横像素的分辨率。
其实单个像素的大小就是像素的密度,单个越小越细腻,单个越大越粗糙。
视图空间中的视锥,视场和缩放,计算机显示视锥的时候上下左右夹角都是标准90度的,所以如果设置的投影矩阵输入参数小于90度,那么会放大物体,如果大于90度那么会缩小物体,3D图形学中只能通过改变视锥的形状,或者拉远摄像机来实现近大远小的,而不能通过拉远z=d都投影底片位置。
因为
水平的缩放是zoomx, 垂直缩放是zoomy他们的比是等于分辨率的比的,这样才能保证物体不被拉伸或者压扁,
所以在设置投影矩阵时一般指定视锥体的一个夹角度数,而不用指定两个夹角。
2.裁剪空间和透视投影,屏幕空间
裁剪空间里面的w都是动态的,该w=z。
1).裁剪空间在进行视锥体内,三角形裁剪时候用是用硬件进行裁剪的,该裁剪是根据边分裂的方法,对三角形的顶点需要先进行判断,该判断用到了
-w<= x <= w,
-w<= y <= w, -w<= z <= w;其中w=z则顶点在视锥体内,否则在视锥体外。
2).背面剔除现在硬件条件下很多放置到屏幕空间中根据三角形的非顺时针绕序进行剔除, 而不是裁剪空间中点击小于90度。
首先裁剪空间还是摄像机空间,只是对x,y进行了缩放;对z进行了等比例的缩放,w计算为了z,并没有进行透视投影,当将他们除以w时候就实现了裁剪空间到透视投影空间的变换,变换到透视投影空间后,x属于[-1,1], y属于[-1,1], DX中z属于[0,1], OPGL中z属于[-1,1]。
裁剪矩阵也就是DIP
OPENGL中将z投影到[-1,1]中:
xScale 0 0 0 0 yScale 0 0 0 0 (f + n)/(f-n) 1 0 0 -2n*f/(f-n) 0 where: yScale = cot(fovY/2) = zoomy xScale = yScale / aspect ratio = zoomx
w = z
DX中将z投影到[0,1]中,投影矩阵为:
xScale 0 0 0 0 yScale 0 0 0 0 f/(f-n) 1 0 0 -n*f/(f-n) 0 where: yScale = cot(fovY/2) = zoomy xScale = yScale / aspect ratio = zoomx
w = z
3.用极限法消去变量法证明,得到结论w 就是等于动态变化的z。
OPENGL中向量乘以DIP的z坐标得:

DX中也同理得证。

DX中也同理得证。
裁剪空间转换到屏幕空间。
那么裁剪空间要先进行除以w=z,该w值刚好被DIP矩阵放置到了4D向量中的最后一维中,对顶点向量进行除法了以后得到新的向量:
Xproject属于[-1,1], Yproject属于[-1,1], DX中Zproject属于[0,1], OPGL中Zproject属于[-1,1]的透视投影长方体。
这个时候z值写入深度缓存, 继续将Xproject,Yproject进行投影到2D屏幕坐标空间中:
总结:这些运算都在图形API硬件上计算了,我们能够做的是理解这样的裁剪空间,透视投影,和转换到屏幕坐标。
设置好视锥体的夹角得到zoomx,zoomy对场景缩放,设置一个就可以了,另一个API会自动计算。
设置好深度距离n,f。
设置摄像机的位置也可以做到近大远小,因为透视投影的原因。
手动计算坐标位置时候,需要考虑周全,为什么要除法,什么情况下才翻转物体位置。
三、可见性检测
可见性检测分为,一是视椎体以外的不可见物体需要裁剪掉,二是背面不可见的物体需要剔除掉。无论是中级可见性检测,高级可见性检测,还是低级可见性检测都要处理这种渲染过滤的情况。因为三角形和像素级别的图形硬件已经做了处理,所以对于图形引擎重心是放在中级包围盒检测和高级空间分割上。
1.LLVSD:Lower level visibility Determination 物体包围体检测
中级的可见性检测,也就是物体包围盒级别的可见性检测。
包围盒分为:
1)AABB:比较紧密,输出为完全不可见或者可能可见(因为三角网格更加准确)
2)球形:坐标转换到裁剪空间后是椭球型,故如果需要要在世界坐标系中可见性检测。
3)三角网格:最紧密的包围盒,但是性能消耗比较大。
(1)包围体裁剪
一般使用AABB包围盒,AABB可在裁剪空间中处理,用裁剪矩阵判断是否在视锥体内,通过:
-w<= x <= w,
-w<= y <= w, -w<= z <= w,其中w=z来判断是否在裁剪矩阵内。
如果不在视锥体内那么舍弃该物体,如果可能在视锥体内那么直接提交渲染,让硬件来进行裁剪(例如裁剪空间中的三角形边分裂裁剪)。
(2)包围体剔除
一般不用裁剪空间的摄像机方向和三角形法向量点积来处理背面剔除了(也就是不用处理包围体剔除),在三角形级别硬件通过代码中
设置删除的三角形绕序来实现剔除(默认是背面,也可以指定为剔除正面保留背面); 在像素级别
用硬件的Z-Buffer深度检测来实现遮挡剔除。
2.HLVSD:High level visibility Determination
(1)八叉树BSP树实现空间分割裁剪:树裁剪思想
可以采用逻辑空间的树形层次来划分空间;也可以用几何分割如平面长方体分割3D空间。
算法的复杂度都要求在对数的时间内O(log n)。
考虑到几何静态分割难以对不同的场景得到不同的层次细节,几何分割难以处理运动物体碰撞检测问题,但是用树型结构可以解决这些问题,且在O(log n)算法复杂度 内是可以接受的。
一般在2D空间中用四叉树来划分场景(2D坐标系的4个象限),在3D空间中用八叉树来划分场景(3D坐标系中的8个象限),也可以用更加灵活的BSP树来划分场景(BSP用一个平面将空间一分为二)。
无论是在四叉树还是八叉树中,还是BSP树都是
当物体横跨两个节点时物体停止下降放入该节点中,若到达了树的深度限制(或节点内物体已经很少或节点小于一定尺寸)就将物体放入该叶子节点中。
树节点记录了该节点的场景AABB位置 大小和本节点的物体列表(该物体列表可能是二维的),还有就是输节点的四个(八个或者两个)子节点的指针。
树建好后就可以用来定位物体,
物体级别剔除渲染,碰撞检测,光线追踪的有效工具。
树能够高效处理场景剔除和碰撞检测的思想是:
如果在某一级别抛弃节点,则它所有的子节点都可以抛弃。且搜索算法比较简单直接按照需求递归遍历即可。可以通过调整树平衡和尽量将物体放置到叶子节点中来提高效率,但是将物体放置下去会导致生成更多的节点(因为横跨区域又要作为独立的区域或者用松散树它的节点可与邻居重叠),所以不将物体放置到叶子中而是在节点中也是很好的做法。
BSP树:是Binary Space Partiton二叉空间划分,树划分空间的思想都一样通过剪枝实现过滤。
BSP树主要的技巧是选择分割面,比四叉树、八叉树有更好的灵活性(四叉树八叉树是固定分割平面的); 四叉树、八叉树都有对应的BSP树。存放和四叉树一样,横跨的物体放在本节点上,若达到深度则将物体放置在叶子节点上,
节点数据也相同记录场景节点AABB位置大小和本节点的物体列表,还有子节点指针。
经典的BSP树在三角形级别分割空间,分割的算法是随机一个分割面(会迅速得到平衡的分割面),这样对于碰撞检测有利,但是对于渲染剔除需要消耗太多的性能了。
物体级别的BSP树,选择分割面的一般方法,一般是用一个平面备选列表(例如轴对称的所有平面,或者45度附近的所有平面)物体的AABB组成的平面也可以加入到备选列表中,这些平面都附加对应的法向量。
选择一个坐标空间,例如世界坐标系中物体的包围盒顶点和物体的法向量得到的d值是不变的,取点积最大和最小的d值,可以提前为备选物体计算d值。将这些基于物体包围盒的法向量和对应的d值得到平面列表,用启发分数算法(比如为最接近当前节点包围盒中点距离的d值),得到评价最高的法向量和d值,取之为根分割平面,后面的子空间间递归的应用生成和评价算法,构建BSP树
。
(2)空间级别的遮挡剔除:图论思想
PVS和Portal技术
PVS是Potentially visible sets潜在可见集,提前计算预处理计算是潜在可见集的基本思路,可通过计算八叉树或者BSP树中的节点中的每个物体,产生一个节点中的可见物体的列表,如何确定某个物体是否可见可以通过记录物体的ID然后进行渲染,扫描帧缓存,找出那些真真可见的物体,并得到可见物体的列表,这是简单的方法,但是也没有找到其它更好的方法了,因为可能有些物体比较特殊我们可能根本不会探测到那些物体的特殊点,或者是墙壁之间的空间,比较难确定,但是实际总确实可以工作的。
一般物体级别的遮挡剔除干脆由硬件处理更快。
但是室内却有一种特殊的技术可以解决,就是
Portal技术,它是用了图论的思想,在剔除室内空间中遮挡物体非常有用
。
在室内,因为有房间和门,因此刚好房间可以作为图的节点,门可以作为图的边。
整个Portal的算法步骤是
:
1)建立楼层的Portal图。
2)选择起点。
3)取得边上的门的AABB.
4) 如果门是开着的,对门AABB直接相连的节点直接渲染,间接相连的对节点相连的节点求AABB和门的AABB求交集,如果集合为空则剪掉。如果门是关着的直接不渲染。
5)对于有间接连接的门之间有交集,那么求得交集返回4)。
3.递归算法的理解
有很多复杂算法都包含了递归算法,特别是关于树形数据结构遍历的情景,所以正确深入理解递归算法是很有必要的。
递归函数机制理解:调用函数的静态和动态机制理解:调用函数和被调用函数虽然是同一个静态代码,但是运行时被函数运行的栈空间独立于调用函数的栈空间,调用点不同,函数状态栈地址也不同,所以运行时
调用函数和被调用函数在代码副本还是数据副本上都是完全不同的,只有通过返回值和调用点进行联系。
递归的调用形式:直接递归调用F1->F1,间接递归F1->F2->F1,很多情况下是直接递归调用。
递归函数优劣点:递归函数比较消耗栈资源,实现简单(内部调用逻辑却比较复杂),但是效率没有非递归版本效率高。
递归的调用形式:直接递归调用F1->F1,间接递归F1->F2->F1,很多情况下是直接递归调用。
递归函数优劣点:递归函数比较消耗栈资源,实现简单(内部调用逻辑却比较复杂),但是效率没有非递归版本效率高。
递归函数内部调用逻辑理解:
理解层次1:
1.递归函数需要一个终止条件。
2.递归函数到终止条件,会沿路出栈对称返回。
理解层次2:
理解层次1:
1.递归函数需要一个终止条件。
2.递归函数到终止条件,会沿路出栈对称返回。
理解层次2:
对于自己动态调用自己 和一个终止条件的理解:
1.递归函数就是函数调用和被调用的压栈关系(函数栈空间变量和状态是独立的,只有返回值和调用点联系),只有找到都会递归调用,所以 递归遍历都是深度遍历。
2. 递归函数的终止条件就是在不断的递归调用下最后会发生不再调用递归函数的情况,可以是if判断也可以是for/while判断。
对沿路出栈对称返回的更深刻理解:
1.递归函数就是函数调用和被调用的压栈关系(函数栈空间变量和状态是独立的,只有返回值和调用点联系),只有找到都会递归调用,所以 递归遍历都是深度遍历。
2. 递归函数的终止条件就是在不断的递归调用下最后会发生不再调用递归函数的情况,可以是if判断也可以是for/while判断。
对沿路出栈对称返回的更深刻理解:
3.一般递归是为了遍历或者查找,
如果查找条件(非终止条件)在递归遍历前面,那么不用全部遍历找到就会返回(更加高效的递归实现);如果查找条件(非终止条件)在递归遍历后面,那么需要全部遍历才会返回。
函数之所以有返回 ,是因为函数压栈后出栈需要执行完整个函数的代码段的编译原理导致的。
总结:研究Ogre的四叉树、八叉树、BSP树,理解其中的场景树的构造和渲染裁剪碰撞检测中的具体作用算法。使用Portal技术实现室内场景的划分,大幅提高室内场景的渲染效率。对树算法,图论算法,递归算法的功底来理解这些裁剪剔除算法。





一旦计算出光照的衰减系数,就可以将它乘以镜面反射分量和漫反射分量,记住环境光是没有衰减的。
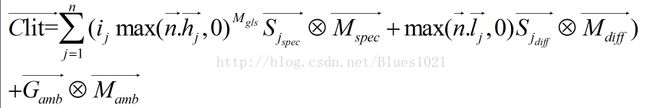

雾浓度的计算公式和光照衰弱的计算公式是一样的,只是光照衰弱程度是从[1, 0], 雾化浓度是从[0,1]。
Clit是光照和衰弱的合成颜色,见上述衰弱环节。

四、光照阴影和雾化
图形学中的光照是取"关闭光照"情况下的纹理颜色(全部高亮)进行计算,故在开始光照情况下往往计算得到的颜色比原来的纹理颜色都要暗一些。
这也是光照的作用,不仅可以单纯用来计算照明像素颜色,也可以对已有的纹理颜色进行明暗修饰,这样使得整个场景更加真实(这句是自己YY的不知道是否正确,有待验证)。
颜色可以用向量形式来表达,加减,数乘都一样,颜色的乘法用
![]() ,每个分量单独相乘即可,因为颜色在光照中被设置为[0,1]故两个小数的乘法会小于原来任何一个的值,使得亮度变暗了。
,每个分量单独相乘即可,因为颜色在光照中被设置为[0,1]故两个小数的乘法会小于原来任何一个的值,使得亮度变暗了。
光源类型:
1)点光源
2)聚光灯
3)平行光
4)环境光
反射类型:
1)镜面反射
2)漫反射
3)环境光反射
物体才是上的颜色是它反射的颜色,而不是它吸收的颜色。
物体被光照的外观相关的因素:
1)光源的类型和方向
2) 物体的表面材质属性
3)物体三角形面法向量朝向
4)观察者的方向
光照的标准方程:
Clit = Cspec + Cdiff + Camb
物体表面的光照值等于镜面反射颜色 + 漫反射颜色 + 环境光反射颜色。
1.镜面反射的光照Phone模型
2.Lambert法则计算的漫反射模型
3.环境光强度模型
因为和光源无关,所以一般只需要计算一个即可。
4.光的衰减
一旦计算出光照的衰减系数,就可以将它乘以镜面反射分量和漫反射分量,记住环境光是没有衰减的。
5.光照和衰减的合成
n是代表多光源,当n=1时是代表单一光源,注意到环境光分量是不受到n的影响的。
总结:一般光照在图形API硬件中计算,那么只需要我们做的事情:
1)开启光照开关
2)设置光源的类型,光源的位置和方向(如果是平行光则不需要位置),光源的镜面反射Sspec和漫反射的颜色Sdiff,或者全局光照的颜色Gamb.
3)设置物体顶点的光泽度Mgls,物体顶点的镜面反射颜色Mspec,物体顶点的漫反射颜色Mdiff,一般物体的Mamb =Mdiff.
4)光线衰弱的参数dmin, dmax.
6.阴影
考虑到光的衰减得到的物体外观还是有点不妥,因为没有考虑到阴影,要计算阴影必须使用其它高级技术,影子设计全局光照。
如果用静态阴影,那么对静态阴影的地方打上区域,角色或者怪物走到改位置让它们的颜色变暗即可。
7.雾化
现实世界中,当观察远方的物体的时候得到的光线是经过无数大气粒子反射和折射光线进入眼睛的,粒子的浓度越大或者物体越远,那么观察到的远方物体颜色越接近雾中粒子的颜色,这就叫做雾化。
雾化中的光线颜色随着距离会不断雾化,到达定义的最远距离后就会完全雾化,所以雾化有雾浓度计算公式:
雾浓度的计算公式和光照衰弱的计算公式是一样的,只是光照衰弱程度是从[1, 0], 雾化浓度是从[0,1]。
Clit是光照和衰弱的合成颜色,见上述衰弱环节。
总结:一般需要雾化在图形API硬件中计算,那么只需要我们做的事情:
1)开启雾化开关
2)设置雾的颜色Gfog
3)设置雾化的距离dmin和dmax
例如:D3D中的fx shader效果文件中:
// Fog States
FogVertexMode = LINEAR; // linear fog function
FogStart = 50.0f; // fog starts 50 units away from viewpoint
FogEnd = 300.0f; // fog ends 300 units away from viewpoint
FogColor = 0x00CCCCCC; // gray
FogEnable = true; // enable
除了线性雾化函数,还有EXP,EXP2函数,用这种指数类型的雾化函数时候不用指定FogStart, FogEnd,但是需要指定FogDensity,需要用到时候再详细查询下。
// Fog States
FogVertexMode = LINEAR; // linear fog function
FogStart = 50.0f; // fog starts 50 units away from viewpoint
FogEnd = 300.0f; // fog ends 300 units away from viewpoint
FogColor = 0x00CCCCCC; // gray
FogEnable = true; // enable
除了线性雾化函数,还有EXP,EXP2函数,用这种指数类型的雾化函数时候不用指定FogStart, FogEnd,但是需要指定FogDensity,需要用到时候再详细查询下。
五、着色模型
有了光照方程(可以用diffuse纹理贴图来代替光照方程),雾化方程(也应该可以用贴图来代替), 就可以在三角形网格中为物体着色或者润色了。
着色的级别分为像素级别Phong着色模型(不同于反射模型中的Phong概念),在像素级别逐个像素的进行光照和雾化计算,但是这样开销太大了,效果是可以获得清晰的计算结果,在离线方式下可以这样计算。
顶点级别的Gouraud着色模型,Gouraud模型是给每个三角形顶点进行光照和雾化计算颜色,然后将多边形的三个顶点进行线性插值得到整个多边形的颜色。这个得到比较满意的平滑效果,而且计算量也一般,不过顶点的光照和雾化的计算量也是非常巨大,而且计算的公式和比坐标转换还要巨大。如果Gouraud得到的结果不是很满意,比如高光面不清晰那么可以细化三角形来实现。
三角形级别的是Flat模型,该模型在每个三角形中计算光照和雾化,然后在整个三角形中应用一样的光照和雾化结果,因为可以清晰的看到面片轮廓所以应用价值不高。
总结:一般需要指定着色模型为Gouraud.
六、缓存
一个图形系统中有很多资源缓存包括CPU中的和AGP/GPU中的,对于渲染来说最重要的是帧缓存backbuffer和frontbuffer,和Z-buffer(Z-buffer里面包含了Stencil Buffer)。
Z-buffer保存的是裁剪空间中的z坐标,该坐标转换到屏幕坐标空间时,光栅化三角形时候,因为每个三角形只有顶点的深度,所以需要计算整个三角形各个像素的插值深度。新的深度缓存全部像素都置为1,当有更小的深度缓存同一个像素时候就将其置换掉。
帧缓存写入的是屏幕坐标系中的像素的颜色,需要背面剔除检测,深度检测和Stencil检测,alpha检测后写入的值。
帧缓存经过这些检测后直接写入即可。
总结:渲染前深度缓存要清理为1(深度值和背面剔除图形硬件都会自动计算),alpha检测需要设计好融合, Stencil模板启用时候要设计要模板值参考值比较函数等,写Pix Shader要注意这些过程。
七、纹理映射
纹理映射方式有:平面映射,球形映射,柱型映射和立方体映射,不过映射方式不重要,因为建模软件例如3dsmax会处理他们。无论如何都要为每个顶点保存uv坐标,uv在[0,1]之间,一个三角形通过三个uv来决定一个纹理的映射表面。
如果纹理映射是连续的,那么三角网格中共用一个顶点的三角形的uv坐标会一样,如果不是连续的,那么三角网格会顶点拆分,为不同uv的共用同一个顶点的三角形生成一个新的顶点,顶点的位置一样只是uv坐标不同。
要渲染三角形的每个像素,需要先对三角形平面上的每个像素进行uv纹理插值,然后从映射的纹理表面里面取得每个像素的颜色。
总结:管理好三角网格的材质系统,构造三角网格时候就尽量让顶点uv坐标和纹理贴图是对应连续的,不是连续的在构建三角形时候也要处理好,三角形网格也要根据uv来进行顶点拆分
。
八、几何体的生成和提交
在单机中几何体可用高层场景管理HLVSD,低层包围盒LLVSD检测来决定需要提交的渲染的几何体。进行提交网格的时候可用离线LOD(三角形边坍塌)渐进式生成网格(实时的计算LOD太消耗计算资源了)。有时候几何体并非由美术来创建,而是计算机生成,称为程序建模,分形地图,植物都可以创建,有时LOD也用在该类建模算法中。
单纯的网游中,经常由服务器告诉客户端同步区域,可以让客户端避免LOD计算,但服务器也得LOD对副本地图中的所有生物进行选择发送给客户端。
1.三角网格的顶点信息
1)位置,3D向量或有Z-buffer顶点2D屏幕坐标,另外骨骼动画中使用的是Skinning顶点坐标,该顶点位置由“骨头”给出。
2 ) uv坐标,一般从美术文件读入或程序计算生成。
3)顶点法向量,光照计算需要用到。
预定义的三角顶点光照颜色有unsigned spec, unsigned argb颜色值;如需要硬件雾化顶点中要有Gfog雾化强度值。
2.顶点的计算
1)新的顶点位置,其中三角网格中的顶点位置需要进行坐标转换,最终到达屏幕坐标位置。
2)uv坐标一般不用变换,最多不连续的uv顶点需要进行三角网格拆分下,如果有阶段性生成纹理坐标的那么也要生成。
3)光照雾化计算得到的三角顶点颜色,光照来自新的顶点法向量,因为三角网格的顶点位置变了,所以需要重新进行计算,否则就是失效的。
(光照可以在世界坐标系,模型坐标系,或者摄像机坐标系中计算。一般不选择,图形API会自动选择。需要将光源坐标和物体坐标放置在同一个坐标空间中才能进行正确的光照计算,一般模型坐标系中转换下光源坐标比世界坐标系更快点,摄像机坐标系中都转换到了摄像机再计算效果会更好。)
有光照需要得到动态光照的每个三角顶点颜色,用预定义的光照不需要计算颜色直接用即可。
有雾化,那么需要得到每个三角顶点的雾浓度,预定义了雾化浓度则不需要计算。
但最终光照、光照衰减和雾化需要计算得到三角顶点的颜色值。
( 如果光照开启了,实际光照计算中,因为基本没有定义物体三角网格中的Mamb环境光照颜色,所以一般用Mamb = Mdiff。
这样代入多光源光照方程(考虑了衰减),根据设置的参数进行计算即可。
如果雾化开启了那么再将光照得到的结果,代入雾化方程,即可计算出光照雾化后的三角顶点颜色。
每个顶点都要进行这样的计算,然后对三角形中的每个像素进行插值计算得到三角形中每个像素的光照颜色,或者光照雾化后的颜色。
)
只是,UV得到的顶点纹理颜色,和光照雾化颜色值不知道是相互独立的,还是可以进行叉乘因为光照而暗化纹理颜色的像素值?
总结:三角网格的位置,uv信息要处理好;程序中要设计要光照相关设置和雾化相关设置;写Vertex Shader时候要处理好这些顶点的计算,是纹理着色插值还是光照着色插值,还是处理每个像素的alpha融合和Stencil检测,那么就需要交给像素着色器来处理了。
九、光栅化
裁剪空间->透视投影->屏幕空间后
1.浮点位置转换为正数的位置,确保三角形中的每个像素只渲染一次,幸运的是图形硬件保证了一切。
2.着色,根据光照雾化得到的颜色进行着色插值得到每个像素的颜色,或者UV纹理插值得到像素颜色。
只是,UV得到的顶点纹理颜色,和光照雾化颜色值不知道是相互独立的,还是可以进行叉乘因为光照而暗化纹理颜色的像素值?
3.测试写入:
背面剔除测试根据设置的绕序(一般是顺时针保留,逆时针剔除,也可以设置顺时针剔除,逆时针保留)。
深度测试,Z-buffer根据裁剪空间得到z值,近的代替掉远的。
Stencil模板测试,过滤掉某些颜色的写入。
Alpha测试,看颜色是否要进行融合。
得到最终的backbuffer后台缓存的颜色值。
新的深度缓存,因为测试了一遍得到的深度缓存都是最近的,所以深度缓存直接写入就可以了。
新的帧缓存,也通过深度检测,模板检测和Alpha检测,后如果需要融合那么根据alpha融合,写入新的帧缓存即可。
总结:光栅化过程中,因为位置和纹理光照雾化都设置好了(光照和纹理得到的颜色之间不知道要做什么处理),如果需要设置好Alpha融合,Stencil模板设置;写Pixel Shader要处理好这些像素级别设置,包括光栅化的插值计算算法设置。