项目总结——hashtable排序问题
前言:
对于Hashtable在我的上篇博客中有提到,是用在了事务处理中,向sqlhelper传递参数,这个用的很巧妙不知道大家有没有进一步的研究,但是为什么现在需要用到Hashtable的排序呢。大家跟着我想这样的一个场景,现在需要注册一个新用户,注册用户的时候需要有如下的业务逻辑:每个用户拥有或多张卡,注册用户的时候需要对卡进行一定金额的充值。
一、业务表分析:
对于这个业务逻辑我们建立的关系表需要有三张,1.用户信息表,用于保存用户的基本信息;2.卡信息表,用于保存卡的基本信息;3.充值记录表,用于保存充值记录信息。当然考虑数据库建立的三范式,我们还需要保证这三张表具有主外键的关系。用一张数据库关系图来表示:

二、与事务机制的联系:
三、为什么要对Hashtable排序:
要实现这样的需求,还需要满足的操作要求:三张表的插入顺序是:用户表——卡表——充值表。
对于Hashtable有一定了解的人都知道Hashtable的一个重要的特点就是排序无序的。
对于这个无序的说明有这样的一个例子:
public static void Main()
{
Hashtable ht = new Hashtable();
ht.Add("key1", "value1");
ht.Add("key2", "value2");
ht.Add("key3", "value3");
ht.Add("key4", "value4");
ht.Add("key5", "value5");
foreach (string str in ht.Keys)
{
Console.WriteLine(str + ":" + ht[str]);
}
}
运行的结果:
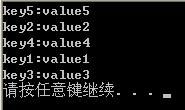
通过这个小例子就可以理解了哈希表的无序性。那我们怎么保证程序按照我们想要的顺序在sqlhelper中逐个的执行呢。(这个执行的代码看上篇博客)我们就需要Hashtable进行排序了。
四、排序的方法:
这里我主要给大家介绍3种方法:
1.我按什么顺序加进去就按什么顺序输出:
public class NoSortHashTable : Hashtable
{
private ArrayList list = new ArrayList();
public override void Add(object key, object value)
{
base.Add(key, value);
list.Add(key);
}
public override void Clear()
{
base.Clear();
list.Clear();
}
public override void Remove(object key)
{
base.Remove(key);
list.Remove(key);
}
public override ICollection Keys
{
get
{
return list;
}
}
}
这里注意:ArrayList是不排序的(添加的顺序就是输出的顺序)。让它和hashtable结合不就实现这种功能的吗?这样继承了Hashtable具有Hashtable的丰富功能,又满足ArrayList不排序的功能。满足我们的要求。
public static void Main()
{
NoSortHashTable ht = new NoSortHashTable();
ht.Add("key1", "value1");
ht.Add("key2", "value2");
ht.Add("key3", "value3");
ht.Add("key4", "value4");
ht.Add("key5", "value5");
foreach (string str in ht.Keys)
{
Console.WriteLine(str + ":" + ht[str]);
}
}
这样一运行就满足我的要求了:

成功了!
2.我按Hashtable中键的大小顺序进行排序
实际上是按照每一个字符的ASCII的值就行排序的。从左到右比较每个字符的Ascii的值,直到满足两个字符的ASCII的值不同即停止比较
public static void Main()
{
Hashtable ht = new Hashtable();
ht.Add("ee", "value1");
ht.Add("dd", "value2");
ht.Add("cc", "value3");
ht.Add("bb", "value4");
ht.Add("aa", "value5");
ArrayList list = new ArrayList(ht.Keys);
list.Sort();
foreach (string str in list)
{
Console.WriteLine(str+":"+ht[str]);
}
}
运行效果:
成功了!
3.我按Hashtable中的值得大小就行排序
原理同上:实际上是按照每一个字符的ASCII的值就行排序的。从左到右比较每个字符的Ascii的值,直到满足两个字符的ASCII的值不同即停止比较
public static void Main()
{
Hashtable ht = new Hashtable();
ht.Add("a", "3");
ht.Add("b", "4");
ht.Add("c", "2");
ht.Add("d", "1");
ArrayList list = new ArrayList(ht.Values);
list.Sort();
foreach (string svalue in list)
{
IDictionaryEnumerator ide = ht.GetEnumerator();
while (ide.MoveNext())
{
if (ide.Value.ToString() == svalue)
{
Console.WriteLine(ide.Key + ":" + svalue);
}
}
}
}
运行效果:
成功了!
五、总结:
针对第二,第三,我们可以看出来了通过下面的这个方法把Hashtable的键(keys)或值(values)转换成Arraylist.
ArrayList list = new ArrayList(ht.Values);
ArrayList list= new ArrayList(ht.Keys);
这样就可以把Hashtable的排序转换成ArrayList的排序了!
另外ArrayList提供的很多方法排序:
ArrayList.Sort()-------------------按字符的Ascii的值排序
ArrayList.Reverse()---------------反转数组
等还多ArrayList方法。如果都不满足你要的排序功能的话,那就自己针对ArrayList这个数组写算法就能对ArrayList排序,ArrayList排序也就完成了Hashtable的排序。
六、重点说明:
另外,需要说明一点,上面的排序是不严谨的,有值相等时会有重复输出 。
例如:
public static void Main()
{
Hashtable hs = new Hashtable();
hs.Add(5, 40);
hs.Add(4, 20);
hs.Add(3, 20);
hs.Add(2, 15);
hs.Add(1, 5);
ArrayList als = new ArrayList(hs.Values);
als.Sort();
foreach (object ob in als)
{
IDictionaryEnumerator ide = hs.GetEnumerator();
while (ide.MoveNext())
{
if (ide.Value.ToString() == ob.ToString())
Console.WriteLine(ide.Key.ToString() + ":" + ob.ToString());
}
}
}
运行结果为:
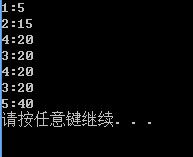
引起这个问题主要是那hashtable中允许有重复的值引起的。如果要想解决这个问题的话,在转换成ArrayList时候需要把重复的value去掉。(key不允许重复就不会出现)
可以将程序改为:public static void Main()
{
Hashtable ht = new Hashtable();
ht.Add(5, 40);
ht.Add(4, 20);
ht.Add(3, 20);
ht.Add(2, 15);
ht.Add(1, 5);
ArrayList listTemp = new ArrayList(ht.Values);
ArrayList list = new ArrayList();
foreach (object value in listTemp)
{
if (!list.Contains(value))
{
list.Add(value);
}
}
list.Sort();
foreach (object obj in list)
{
IDictionaryEnumerator ide = ht.GetEnumerator();
while (ide.MoveNext())
{
if (ide.Value.ToString() == obj.ToString())
{
Console.WriteLine(ide.Key.ToString() + ":" + obj.ToString());
}
}
}
}
运行结果为:

成功了!