OpenCV训练分类器制作xml文档
opencv 2.1网上查的另一种资料
训练分类器成功,在此与大家分享。
参考英文资料网址: http://note.sonots.com/SciSoftware/haartraining.html#e134e74e
样本训练要求
1、杯子的背景要统一吗,因为有些背景是白色,有些是淡淡的背景色,还有些深色的背景色
答:背景色要统一
2、整个图的大小就是最外面一个框框起来那么大,
问题是:我需要在原图基础上截图吗,如:只把红框框起来的那部分截出来???
答:不用的
3、那图片是256色的还是彩色的呢?
答:灰度最佳
5、一般来说,训练分类器用的什么 图片 就用什么 图片作测试
即来源图片分别用于训练和测试
6、那正样本选择方面有没有要求,如玻璃杯
当然有要求。
最好各种形状的玻璃杯都有样本,每种玻璃杯从不同角度拍摄的样本都有
7、那网上截些有关玻璃杯的图可以吗?大小是要归一化的
可以的。网上的图像实际上也来源于生活或科研拍摄的
其实可以不是图片的归一化,还可以是特征的归一化
归一化的话可以根据缓需求,不同应用场合就有不同的归一化方法
8、那关于杯子这个正样本,我要弄大约多少张图片呀?
样本要多,当然并不是越多越好,而是每一张都有代表性,能反映一定意义
9、负样本最好含有正样本中的背景部分
训练失败的原因很多:
1、负样本数目太少,导致Adaboost算法汉有跳出死循环,
2、负样本之间重复部分过多,或正样本尺寸过大,导致训练分类器时内在溢出。
.vec文件里的东西是用二进制的形式表示的。
首先写的是样本的数量,然后是样本大小width*height,后面就是图片像素值。
在opencv下的cvsamples.cpp就能看的很清楚了。
本文现在正在做人头检测。视频中的人头尺寸,光照,角度都很不相同。
1. 请问haar训练中正样本是不是只能是在光照尺寸和角度都一致的情况下进行训练?
正樣本的光照可以是有變化的,正樣本應該保留一些樣本以外的背景,但不能過大,角度的話,人臉轉90度都還可以接受。
其實你正樣本的種類(不同角度.不同光照.不同人臉)越多,就需要更多的矩形特徵來作分類。
2.正负样本需要一样的大小么?
人臉建議使用20*20,大小要盡量統一,這樣在做Description txt file時,比較方便。人臉在圖片中的位置盡量也相同。
3.有人说正负样本数量比例最好是7:3,也有人说正负样本须一样多。这是怎么回事?
我怎麼聽說 正:負=1:3比較好。建議你可以先試試看1000:3000應該不用花太多時間訓練。
4.在训练中,本人发现了一种情况:如果正负样本差别较小,即负样本从待检测视频图像中的背景获取,并且与正样本一样大的话,训练就会在某一个节点上停下来,并且几天也过不了这个节点;而如果负样本与正样本差别很大(尺寸与取样上都差别很大)的话,训练结束比较快,但是用得到的xml文件去做检测的话,效果很不好。请问这是不是矛盾,该怎么解决?
正負樣本照理說應該不會差別不大,除非你是要偵測笑臉/非笑臉,另外可能是你負樣本太少,所以false alarm數值太高,所以haartraining 沒有正常terminate
5.参数stage一般设置多大?
我目前使用如下指令
opencv_haartraining.exe -data "d:\training0421\20s" -vec "d:\training0421\positive\positives.vec" -bg "d:\training0421\negative\negative.txt" -npos 1681 -nneg 3406 -nstages 20 -nsplits 2 -minhitrate 0.995 -maxfalsealarm 0.5 -mode ALL -mem 2000 -w 20 -h 20
使用profermance來測試原始訓練樣本(200*200p)可以有八成的hitrate,false大概幾十個。
整个过程分为两步:
1. 创建样本
2. 训练分类器
3、 利用训练好的分类器进行目标检测。
现在让我一一讲述。
1. 创建样本
◆ 样本分两种: 正样本与负样本(也有人翻译成:正例样本和反例样本),其中正样本是指待检目标样本(例如人脸,汽车,鼻子等),负样本指其它任意图片。
◆ 所有样本图片都应该有同一尺寸,如20 * 20,并放在相应文件目录下,
◆ 集合文件格式(collection file format)和描述文件格式(description file format)
集合文件格式(collection file format)就是如下形的描述文件:
[filename]
[filename]
[filename]
…
描述文件格式(description file format)就是如下形的描述文件:
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
….
(x, y) 指左上角的坐标,width和 height 分别是样本的宽和高,这里我的图片是20*20的,所以两个值都是20
◆ 负样本用集合文件格式描述,正样本用描述文件格式描述!(这点网上很多文章都搞错了!)
▼创建样本步骤:
一. 把所有正样本图片放在posdata的文件夹下,把所有负样本图片放在negdata文件夹下
(这里我以人脸图片样本为例)


(注:以上这些 20*20 的图片均来自MIT人脸库,可以在csdn下载)
二. 分别为正样本和负样本创建描述文件
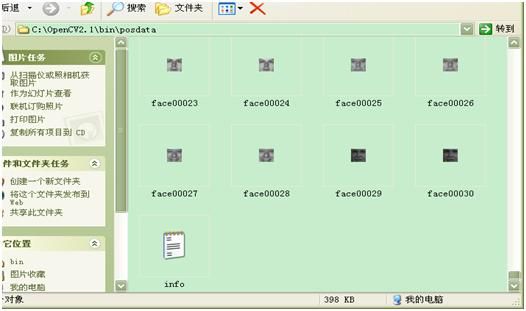
A. 为正样本创建描述文件格式文件info.txt,并且把这个文件放在与样本图片同一目录下,例如我的目录为C:/OpenCV2.1/bin/posdata
a) 在命令行下 输入以下命令: dir /b > info.txt
![]()
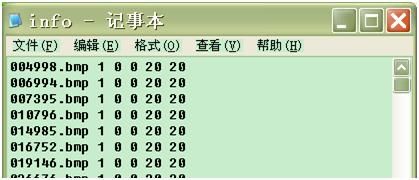
b) 打开info.txt, 按ctrl+h, 把所有的bmp 换成 bmp 1 0 0 20 20
c) 删除info.txt最后一行的 “info.txt”
d) 结果如下:(1代表一个文件,0 0 20 20表示这个文件的2个顶点位置坐标)
B. 为负样本创建集合文件格式文件bg.txt, 并且把这个文件放在与样本图片同一目录下,例如我的目录为I:/negdata
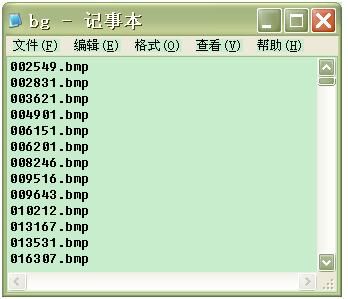
a) 在命令行下 输入以下命令: dir /b > bg.txt
b) 删除bg.txt最后一行的 “bg.txt”
c) 结果如下:
三. 创建样本。
Opencv 自带有创建样本的exe 文件,在 …/OpenCV2.1/bin 目录下, 这里我创建120个sample:
命令是: opencv_createsamples.exe -info e:\test\posdata0\info.txt -vec e:\test\posdata0\pos.vec -num 120 -w 20 -h 20
如图:
结果如图:
(关于 opencv_createsamples.exe 的参数用法,在参考英文资料网址http://note.sonots.com/SciSoftware/haartraining.html#e134e74e,里有详细介绍;
需要说明的是,我这里用的参数并没有 –bg, 因为根据那份文档,有了 –vec 和 –info 之后,就表示:Create training samples from some (从很多正样本中创建sample, 没有distortions)
经历千辛万苦,我们终于看到sample被创建成功了,接下来的工作就简单多了
▼训练分类器
还是在…/OpenCV2.1/bin目录下,输入命令:
opencv_haartraining.exe -data e:\test\data0\cascade0 -vec e:\test\posdata0\pos.vec -bg e:\test\negdata0\negdata0.txt -npos 120 -nneg 120 -nsplits 2 -mem 512 -nonsym -w 20 -h 20 -minpos 100 -nstages 4
回车
(注意:
1. 参数-vec 一定要是刚刚创建样本产生的a.vec,且把完整路径也写上去,我试过用相对路径,但总会训练失败; bg.txt 也要用绝对路径;
.vec文件里的东西是用二进制的形式表示的。
首先写的是样本的数量,然后是样本大小width*height,后面就是图片像素值。
在opencv下的cvsamples.cpp就能看的很清楚了。
2. –w 和 –h 都要写上与样本大小的一致的尺寸
3. 若遇到“内存什么不能read”的问题,很有可能是bg.txt的格式有误,回去
4. 关于 opencv_haartraining.exe 的参数用法,在参考英文资料网址http://note.sonots.com/SciSoftware/haartraining.html#e134e74e,里有详细介绍
)
结果如下:
(可能实际结果与上图有出入, 但看到最后的 ![]() ,就说明训练成功了。
,就说明训练成功了。
在E:\test\data0目录会生成一份cascade0.xml文档,这个就是我们想要的结果了!
============================================================================
OpenCV训练分类器制作xml文档之一
问题解决:
首先了解下,目标检测分为三个步骤:
1、 样本的创建
2、 训练分类器
3、 利用训练好的分类器进行目标检测。
一,样本的创建:
(1)收集训练样本:
训练样本包括正样本和负样本。正样本,通俗点说,就是图片中只有你需要的目标。而负样本的图片只要其中不含有目标就可以了。但需要说明的是,负样本也并非随便选取的。例如,你需要检测的目标是汽车,那么正样本就应该是仅仅含有汽车的图片,而负样本显然不能是一些包含天空的,海洋的,风景的图片。因为你最终训练分类器的目的是检测汽车,而汽车应该出现在马路上。也就是说,分类器最终检测的图片应该是那些包含马路,交通标志,建筑物,广告牌,汽车,摩托车,三轮车,行人,自行车等在内的图片。很明显,这里的负样本应该是包含摩托车、三轮车、自行车、行人、路面、灌木丛、花草、交通标志、广告牌等。
另外,需要提醒的是,adaboost方法也是机器学习中的一个经典算法,而机器学习算法的前提条件是,测试样本和训练样本独立同分布。所谓的独立同分布,可以简单理解为:训练样本要和最终的应用场合非常接近或者一致。否则,基于机器学习的算法并不能保证算法的有效性。此外,足够的训练样本(至少得几千张正样本、几千张负样本)也是保证训练算法有效性的一个前提条件。
训练样本分为 正例样本和反例样本,其中正例样本是指待检目标样本(例如可乐瓶,人脸等),反例样本指其它任意图片,所有的样本图片都被归一化为同样的尺寸大小(例如,20x20)。1 、负样本(反例样本)可以来自于任意的图片,但这些图片不能包含目标特征。
现在,我们来看正样本的创建步骤:
正样本由程序createsample程序来创建。该程序的源代码由OpenCV给出,并且在bin目录下包含了这个可执行的程序。
正样本可以由单个的目标图片或者一系列的事先标记好的图片来创建。
createsamples程序的命令行参数:
命令行参数:
-vec <vec_file_name>
训练好的正样本的输出文件名。
-img<image_file_name>
源目标图片(例如:一个公司图标)
-bg<background_file_name>
背景描述文件。
-num<number_of_samples>
要产生的正样本的数量,和正样本图片数目相同。 -maxidev<max_intensity_deviation>
背景色最大的偏离度。
-maxangel<max_x_rotation_angle>
-maxangle<max_y_rotation_angle>,
-maxzangle<max_x_rotation_angle>
最大旋转角度,以弧度为单位。
-show
如果指定,每个样本会被显示出来,按下"esc"会关闭这一开关,即不显示样本图片,而创建过程继续。这是个有用的debug选项。
-w<sample_width>
输出样本的宽度(以像素为单位)
-h<sample_height>
输出样本的高度,以像素为单位。
注:正样本也可以从一个预先标记好的图像集合中获取。这个集合由一个文本文件来描述,类似于背景描述文件。每一个文本行对应一个图片。每行的第一个元素是图片文件名,第二个元素是对象实体的个数。后面紧跟着的是与之匹配的矩形框(x , y ,宽度,高度)。
下面是一个创建样本的例子:
假定我们要进行人脸的检测,有18个正样本图片文件face00001.bmp,…face00100.bmp;有45个背景图片文件:B1_00001.bmp, …B1_00200.bmp,文件目录结构如下:
e:\test\negdata\
face0001.bmp
……
face0018.bmp
info.txt
e:\test\posdata
B1_001.bmp
……
B1_0045.bmp
negdata.dat
正样本描述文件info.txt的内容如下:
face00001.bmp 1 0 0 20 20
……
face00100.bmp 1 0 0 20 20
背景(负样本)描述文件negdata.txt的内容如下:
B1_00001.bmp ……
B1_00200.bmp
图片imag1.bmp包含了单个目标对象实体,矩形为(0,0,20,20)。
注意:要从图片集中创建正样本,要用-info参数而不是用-img参数。
-info <collect_file_name>
标记特征的图片集合的描述文件。在cmd窗口下来进行样本的创建:
C:\Program Files\OpenCV\bin>createsamples -info e:\test\posdata\info.txt -vec e:\test\posdata\pos.vec -num 18 -w 20 -h 20【解释下】。。。。
小贴士1:
可以采用Dos命令生成样本描述文件(一般样本图片上万幅),在Dos下进入图片目录,输入dir /b *.bmp > negdata.txt, 则会在此目录中产生一个negdata.txt,文件中包含所有当前目录下的文件名,就可以建成负样本描述文件。对于正样本描述文件,方法同负样本,只要把bmp替换成1 0 0 20 20即可。如果样本图片太多,在txt中替换会导致程序无法响应,可以先把内容拷贝到word中替换后再拷贝回来。
小贴士2:
一些处理后的人脸图片的网址
http://vasc.ri.cmu.edu/idb/html/face/frontal_images/
http://www.pascal-network.org/challenges/VOC/databases.html#VOC2005_1
三、训练分类器
样本创建之后,接下来要训练分类器,这个过程是由haartraining程序来实现的。该程序源码由OpenCV自带,且可执行程序在OpenCV安装目录的bin目录下。
Haartraining的命令行参数如下:
-data<dir_name>
存放训练好的分类器的路径名。
-vec<vec_file_name>
正样本文件名(由trainingssamples程序或者由其他的方法创建的)
-bg<background_file_name>
背景描述文件。
-npos<number_of_positive_samples>,
-nneg<number_of_negative_samples>
用来训练每一个分类器阶段的正/负样本。合理的值是:nPos = 7000;nNeg = 3000
-nstages<number_of_stages>
训练的阶段数。
-nsplits<number_of_splits>
决定用于阶段分类器的弱分类器。如果1,则一个简单的stump classifier被使用。如果是2或者更多,则带有number_of_splits个内部节点的CART分类器被使用。
-mem<memory_in_MB>
预先计算的以MB为单位的可用内存。内存越大则训练的速度越快。
-sym(default)
-nonsym
指定训练的目标对象是否垂直对称。垂直对称提高目标的训练速度。例如,正面部是垂直对称的。
-minhitrate<min_hit_rate>
每个阶段分类器需要的最小的命中率。总的命中率为min_hit_rate的number_of_stages次方。
-maxfalsealarm<max_false_alarm_rate>
没有阶段分类器的最大错误报警率。总的错误警告率为max_false_alarm_rate的number_of_stages次方。
-weighttrimming<weight_trimming>
指定是否使用权修正和使用多大的权修正。一个基本的选择是0.9
-eqw
-mode<basic(default)|core|all>
选择用来训练的haar特征集的种类。basic仅仅使用垂直特征。all使用垂直和45度角旋转特征。
-w<sample_width>
-h<sample_height>
训练样本的尺寸,(以像素为单位)。必须和训练样本创建的尺寸相同。
一个训练分类器的例子:
C:\Program Files\OpenCV\bin>haartraining -data e:\test\data\cascade -vec e:\test\posdata\pos.vec -bg e:\test\negdata\negdata.txt -npos 18 -nneg 45 -nsplits 1 -mem 512 -mode ALL -w 20 -h 20 -minhitrage 0.998 -maxfalsealarm 0.5 -nstages
训练开始,如下图,可能会一小段时间才训练完成。
(可能实际结果与上图有出入, 但看到最后的 ![]() ,就说明训练成功了。
,就说明训练成功了。
在bin目录会生成一份可爱的data.xml文档,这个就是我们想要的结果了!
训练结束后,会在目录data下生成一些子目录,即为训练好的分类器。
训练结束后,还要使用haarconv.exe生成xml文件,可以通过下列网页下载。
http://www.opencv.org.cn/forum/viewtopic.php?t=5181
重要!可能遇到的问题:
1.如果跑到某一个分类器时,几个小时也没有反应,而且显示不出训练百分比,这是因为你的负样本数量太少,或者负样本的尺寸太小,所有的负样本在这个分类器都被reject了,程序进入不了下一个循环,果断放弃吧。解决方法:负样本尽量要大一些,比如我的正样本是40*15,共300个,负样本是640*480,共500个。(我当时的错误就出现在这,把负本改大后,就成功了)
2.读取样本时报错:Negative or too large argument of CvAlloc function,网上说这个错误是因为opencv规定单幅iplimage的内存分配不能超过10000,可是我的每个负样本都不会超过这个大小,具体原因不明。后来我把负样本的数量减少,尺寸加大,这个问题就解决了。
3.训练的过程可能经常出错,耐心下来不要着急,我在训练MRI分类器的时候失败了无数次。失败的时候有两件事可以做,第一,调整正负样本的数量,再试。第二,调整负样本的大小,祝大家好运。
=============================================================================================
opencv haar训练--训练样本(4)
1.海尔训练
现在,我们使用haartraining.exe来训练我们自己的分类器。训练语句如下:
- Usage: ./haartraining
- -data <dir_name>
- -vec <vec_file_name>
- -bg <background_file_name>
- [-npos <number_of_positive_samples = 2000>]
- [-nneg <number_of_negative_samples = 2000>]
- [-nstages <number_of_stages = 14>]
- [-nsplits <number_of_splits = 1>]
- [-mem <memory_in_MB = 200>]
- [-sym (default)] [-nonsym]
- [-minhitrate <min_hit_rate = 0.995000>]
- [-maxfalsealarm <max_false_alarm_rate = 0.500000>]
- [-weighttrimming <weight_trimming = 0.950000>]
- [-eqw]
- [-mode <BASIC (default) | CORE | ALL>]
- [-w <sample_width = 24>]
- [-h <sample_height = 24>]
- [-bt <DAB | RAB | LB | GAB (default)>]
- [-err <misclass (default) | gini | entropy>]
- [-maxtreesplits <max_number_of_splits_in_tree_cascade = 0>]
- [-minpos <min_number_of_positive_samples_per_cluster = 500>]
Usage: ./haartraining -data <dir_name> -vec <vec_file_name> -bg <background_file_name> [-npos <number_of_positive_samples = 2000>] [-nneg <number_of_negative_samples = 2000>] [-nstages <number_of_stages = 14>] [-nsplits <number_of_splits = 1>] [-mem <memory_in_MB = 200>] [-sym (default)] [-nonsym] [-minhitrate <min_hit_rate = 0.995000>] [-maxfalsealarm <max_false_alarm_rate = 0.500000>] [-weighttrimming <weight_trimming = 0.950000>] [-eqw] [-mode <BASIC (default) | CORE | ALL>] [-w <sample_width = 24>] [-h <sample_height = 24>] [-bt <DAB | RAB | LB | GAB (default)>] [-err <misclass (default) | gini | entropy>] [-maxtreesplits <max_number_of_splits_in_tree_cascade = 0>] [-minpos <min_number_of_positive_samples_per_cluster = 500>]
Kuranov et. al. 指出,20*20的样本识别的正确率最高。另外,对于18*18的尺寸,四分裂节点表现最好。而对于20*20的样本,两节点显然更好。分裂节点数分别是2、3或4的弱树分类器间的差小于它们的中间节点。
此外,关于20阶训练有个说法。假设我的测试集合代表了学习任务,我可以期望一个报错率是0.5^20≈9.6e-07,识对率是0.999^20≈0.98。
所以,使用20*20的样本大小,并且Nsplit=2, Nstages=20, MINhitrate=0.9999(default: 0.995), MAXfalsealarm=0.5(default: 0.5), weighttrimming=0.95(default: 0.95)是比较优的组合。
- $ haartraining -data haarcascade -vec samples.vec -bg negatives.dat -nstages 20 -nsplits 2 -minhitrate 0.999 -maxfalsealarm 0.5 -npos 7000 -nneg 3019 -w 20 -h 20 -nonsym -mem 512 -mode ALL
$ haartraining -data haarcascade -vec samples.vec -bg negatives.dat -nstages 20 -nsplits 2 -minhitrate 0.999 -maxfalsealarm 0.5 -npos 7000 -nneg 3019 -w 20 -h 20 -nonsym -mem 512 -mode ALL
"-nonsym"选项用于没有垂直(左-右)对称的对象类。如果对象类是垂直对称的,例如正脸,则用"-sym (default)"。这样会增大运算速度,因为类海尔特征只有一半投入使用。
"-mode ALL"使用了类海尔特征的扩展集。默认只使用竖直特征,ALL除了能使用竖直特征,还能使用转角为45°的特征集合。
"-mem 512"是以MB为单位的预计算可使用的内存大小。默认是200MB。
另外还有一些选项没有用到:
- [-bt <DAB | RAB | LB | GAB (default)>]
- [-err <misclass (default) | gini | entropy>]
- [-maxtreesplits <max_number_of_splits_in_tree_cascade = 0>]
- [-minpos <min_number_of_positive_samples_per_cluster = 500>]
[-bt <DAB | RAB | LB | GAB (default)>] [-err <misclass (default) | gini | entropy>] [-maxtreesplits <max_number_of_splits_in_tree_cascade = 0>] [-minpos <min_number_of_positive_samples_per_cluster = 500>]
#你可以使用OpenMP(multi-processing).
#一次训练持续三天。
2.生成XML文件
当海尔训练过程完全结束,它将会生成一个xml文件。
如果你想要将一个中级海尔训练输出目录树转化为一个xml文件,在目录OpenCV/samples/c/convert_cascade.c下有个程序可供使用。
输入的格式为:
- $ convert_cascade --size="<sample_width>x<sampe_height>" <haartraining_ouput_dir> <ouput_file>
$ convert_cascade --size="<sample_width>x<sampe_height>" <haartraining_ouput_dir> <ouput_file>
举例:
- $ convert_cascade --size="20x20" haarcascade haarcascade.xml
$ convert_cascade --size="20x20" haarcascade haarcascade.xml