Oracle学习之路(二):oracle多表查询+分组查询+子查询讲解与案例分析+经典练习题
1.笛卡尔集和叉集
笛卡尔集会在下面条件下产生:省略连接条件、连接条件无效、所有表中的所有行互相连接。
为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件。在实际运行环境下,应避免使用全笛卡尔集。
使用CROSS JOIN 子句使连接的表产生叉集。叉集和笛卡尔集是相同的。
2.Oracle连接类型:
Equijoin:等值连接
Non-equijoin:不等值连接
Outer join:外连接
Self join:自连接
使用表名前缀在多个表中区分相同的列。在不同表中具有相同列名的列可以用表的别名加以区分。
使用别名可以简化查询。使用表名前缀可以提高执行效率。如果使用了表的别名,则不能再使用表的真名
连接 n个表,至少需要 n-1个连接条件。 例如:连接三个表,至少需要两个连接条件。
3.内连接和外连接
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行。
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行,这种连接称为左(或右) 外联接。没有匹配的行时, 结果表中相应的列为空(NULL). 外连接的 WHERE 子句条件类似于内部链接, 但连接条件中没有匹配行的表的列后面要加外连接运算符, 即用圆括号括起来的加号(+).
在SQL:内连接只返回满足连接条件的数据;两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行,这种连接称为左(右) 外联接。
两个表在连接过程中除了返回满足连接条件的行以外还返回两个表中不满足条件的行 ,这种连接称为满外联接。
自然连接:NATURAL JOIN 子句,会以两个表中具有相同名字的列为条件创建等值连接。
在表中查询满足等值条件的数据。
如果只是列名相同而数据类型不同,则会产生错误。
使用 USING 子句创建连接
在NATURAL JOIN 子句创建等值连接时,可以使用 USING 子句指定等值连接中需要用到的列。使用 USING 可以在有多个列满足条件时进行选择。不要给选中的列中加上表名前缀或别名。NATURAL JOIN 和 USING 子句经常同时使用。
使用ON 子句创建连接
自然连接中是以具有相同名字的列为连接条件的;可以使用 ON 子句指定额外的连接条件。这个连接条件是与其它条件分开的。ON 子句使语句具有更高的易读性。
4.分组函数
分组函数就是:作用于一组数据,并对一组数据返回一个值。
组函数类型(组函数忽略空值,NVL函数使分组函数无法忽略空值。)
AVG 、COUNT 、MAX 、MIN 、STDDEV(标准方差)、SUM、COUNT(expr) 返回 expr不为空的记录总数、COUNT(DISTINCT expr) 返回 expr非空且不重复的记录总数。
可以使用GROUP BY 子句将表中的数据分成若干组;在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中。
包含在 GROUP BY子句中的列不必包含在SELECT 列表中
非法使用组函数:
所用包含于SELECT 列表中,而未包含于组函数中的列都必须包含于 GROUP BY 子句中。不能在 WHERE子句中使用组函数(注意)。
可以在 HAVING子句中使用组函数。
过滤分组: HAVING 子句;使用 HAVING 过滤分组:
1). 行已经被分组。
2). 使用了组函数。
3). 满足HAVING 子句中条件的分组将被显示。
例子:
SQL> select count(deptno)from emp;
COUNT(DEPTNO)
-------------
14
SQL> select count(distinct deptno)from emp;
COUNT(DISTINCTDEPTNO)
---------------------
3
SQL> select avg(nvl(comm,0)) from emp;
AVG(NVL(COMM,0))
----------------
157.142857
SQL> select avg(comm) from emp;
AVG(COMM)
----------
550
SQL> select deptno,job,sum(sal) from emp group by deptno,job order by deptno asc,sum(sal) asc;
DEPTNO JOB SUM(SAL)
---------- --------- ----------
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
20 CLERK 1900
20 MANAGER 2975
20 ANALYST 6000
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
5.子查询
子查询 (内查询) 在主查询之前一次执行完成。子查询的结果被主查询使用 (外查询)。子查询要包含在括号内。 将子查询放在比较条件的右侧。
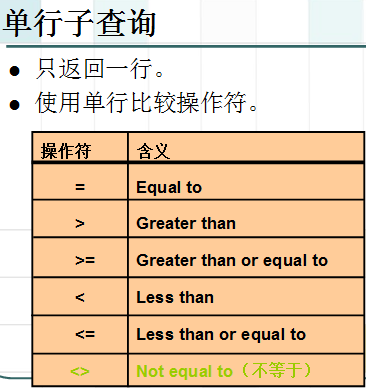
单行操作符对应单行子查询,多行操作符对应多行子查询。
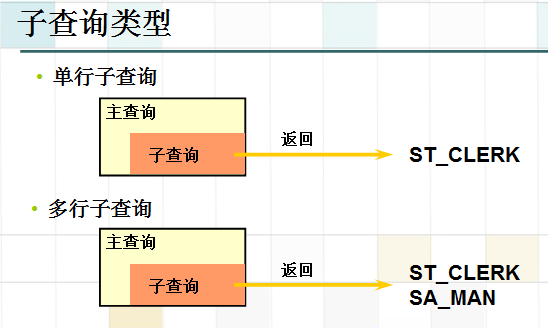
首先执行子查询。向主查询中的HAVING 子句返回结果
非法使用子查询:多行子查询使用单行比较符;子查询中的空值问题:子查询不返回任何行

6.案例分析(用户在hr/hr下面操作)
查询和Zlotkey相同部门的员工姓名和雇用日期
select initcap(concat(last_name,first_name)) as "姓名",hire_date from employees where department_id = (Select department_id from employees where last_name = 'Zlotkey');
查询工资比公司平均工资高的员工的员工号,姓名和工资。
select employee_id,initcap(concat(last_name,first_name)) as "姓名",salary from employees where salary >( select avg(salary) from employees) ;
查询各部门工资比本部门平均工资高的员工的员工号,姓名和工资
select employee_id,initcap(concat(last_name,first_name)) as "姓名",salary from (select department_id,avg(salary) avgsalary from employees group by department_id) s join employees e on e.department_id=s.department_id and e.salary>s.avgsalary;
查询和姓名中包含字母u的员工在相同部门的员工的员工号和姓名
select e.employee_id, initcap(concat(last_name,first_name)) as "姓名" from(select employee_id, initcap(concat(last_name,first_name)) as "姓名" from employees where initcap(concat(last_name,first_name)) like '%u%') s join employees e on e.employee_id=s.employee_id;
查询在部门的location_id为1700的部门工作的员工的员工号
写法一:
select employee_id from employees e,departments d,locations l where e.department_id = d.department_id and d.location_id = l.location_id and l.location_id = 1700;
写法二:
select employee_id from employees e join departments d on e.department_id = d.department_id
join locations l on d.location_id = l.location_id and l.location_id = 1700;
查询管理者是King的员工姓名和工资
select initcap(concat(e.last_name,e.first_name)) as "姓名",e.salary,e.manager_id from employees e,employees m where e.manager_id=m.manager_id and m.last_name='King';
7.切换到scott表做练习:
找到员工表中工资最高的前三名,如下格式:
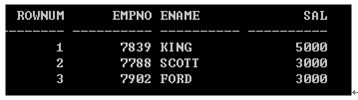
select rownum,d.* from (select empno,ename,sal from emp order by sal desc )d where rownum<=3;
统计每年入职的员工个数,效果如下格式

方法一:
select
(select count(*) from emp) total,
(select count(*) from emp where to_char(hiredate, 'yyyy')='1980')"1980",
(select count(*) from emp where to_char(hiredate, 'yyyy')='1981')"1981",
(select count(*) from emp where to_char(hiredate, 'yyyy')='1982')"1982",
(select count(*) from emp where to_char(hiredate, 'yyyy')='1987')"1987",
(select count(*) from emp where to_char(hiredate, 'yyyy')='1990') "1990"
from emp where rownum=1;
方法二:
select count(*) total,
sum(Decode(to_char(hiredate, 'yyyy'), '1980', 1, 0)) "1980",
sum(Decode(to_char(hiredate, 'yyyy'), '1981', 1, 0)) "1981",
sum(Decode(to_char(hiredate, 'yyyy'), '1982', 1, 0)) "1982",
sum(Decode(to_char(hiredate, 'yyyy'), '1987', 1, 0)) "1987",
sum(Decode(to_char(hiredate, 'yyyy'), '1990', 1, 0)) "1990"
from emp;