sparql 学习,理解sparql
SPARQL 的历史
SPARQL 建立在多项关键技术的基础之上,就像 HTTP 和 HTML(万维网的基础)依赖于 TCP/IP 这样的更深和更低层系统一样。在介绍 SPARQL 之前首先看看一些重要的标准,它们为什么存在,对于语义 Web 开发人员来说意味着什么。
1997 年,Tim Berners-Lee 指出 HTML 和万维网存在着局限性。其设计的目标不是动态 Web 应用程序,更不用说现在的复杂分布式系统了。HTML 和 HTTP 仅仅是迈向更远大的目标 —— 机器与机器之间的半自动通信 —— 的(重要的)一步,对于我们来说就像只有 FTP 时的 WWW 一样。实现这个目标的基础是 RDF(资源描述框架)。
RDF 可以描述任何事物,包括它自身,因此可以从很小的一层开始逐渐丰富。这种薄层方法用于建立词汇栈。图 1 显示了 W3C 定义的层。目前,RDF 之上的层包括 RDFS 和 OWL(有人认为将来的工作是在 OWL 上进行构建)。RDFS 即 RDF Schema 语言,它为 RDF 添加类和属性。OWL(Web 本体语言)扩展 RDFS,提供了一种更丰富的语言来定义类之间的关系。更丰富的语言允许使用自动化的推理引擎创建更智能的系统。
图 1. 语义 Web:W3C Web 体系结构的技术组合

下一节将介绍如何构造 RDF,以及如何使用 RDF 构建世界模型。
回页首
RDF
RDF 曾经被称为 “元描述语言”,但这种有趣的提法不过是说它用于描述事物。它描述事物的方式和人类一样,比如 “乌鸦吃玉米” 或 “Joni 爱 Chachi” 之类的句子。每个句子都有主语(乌鸦,Joni)、谓语(吃,爱)和宾语(玉米,Chachi)。在 RDF 中这种主谓宾结构称为三元组。RDF 使用三元组描述任何事物。
直观地表达这类三元组的一种方式是 RDF 图,它是 RDF 语句的一个集合。图用节点和弧线定义。 RDF 中的节点表示资源,弧线则是谓语 — 即关于主语和宾语节点之间的关系的陈述。RDF 规范的核心就是定义图,其他(如序列化格式等等)都是次要的。主语和宾语成分定义了图中的节点(也称为资源,因为它们是 URI 的目标)。每个谓语定义了三元组引用的两个节点之间的关系。
为了能够从 Web 上的其他位置访问图,需要将 RDF 文件保存到三元组库 — 即存储组成图的三元组的地方。将 RDF 图存储到三元组库并公开到 Web 上之后,其他人就可使用 SPARQL 查询了(如图 2 所示)。
图 2. RDF 图的直观表示,包含 Subject 和 Object 之间的一个谓语关系陈述
RDF 中的每个节点和谓语都用 URI 标识。RDF 也允许不使用 URI 标识的节点,称为空白节点(Blank Node)或空白节点标识符(Blank Node Identifier),作为用于本地引用的临时的、内部可见的标识符。RDF 规范指出,虽然提供了将 RDF 序列化为 XML 的一个标准,但是允许使用任何等价的结构。下面的 RDF XML 描述关于作者的一个三元组(如清单 1 所示)。
清单 1. 描述作者的三元组的 RDF XML
<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:mu="http://aabs.purl.org/music#"> <rdf:Description rdf:about="http://aabs.purl.org/music#andrew"> <mu:playsInstrument> <rdf:Description rdf:about="http://aabs.purl.org/music#guitar"/> </mu:playsInstrument> </rdf:Description> </rdf:RDF> |
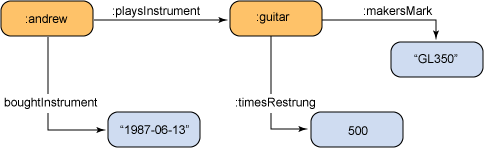
它说明的是 “Andrew 弹吉他”,或者更精确地说 “称为 Andrew 的某人弹奏称为吉他的乐器”。必须承认,传递这么少的信息,上述的 XML 太长了。下面是 Turtle 语言的描述,该语言也是由 W3C 掌控的(如清单 2 所示)。
清单 2. 和清单 1 相同的 RDF,使用 Turtle 描述
@prefix : <http://aabs.purl.org/music#> . :andrew :playsInstrument :guitar . |
好多了!这些语句的信噪比高得多,仅此一点就值得使用了。W3C 希望把 Turtle 作为人类可读和可写的 RDF 语言。SPARQL 使用 Turtle,因此后面所有的例子都将使用它。一个三元组的后面用句点(.)作为分隔符,因此空格无关紧要(如图 3 所示)。
图 3. 用一条语句声明‘Andrew’ 和 ‘guitar’ 通过 ‘playsInstrument’ 关系相关联
除了用于在 RDF 文件中嵌入 XML 的 XML Literal 类型外,RDF 没有内置类型。可以使用 XML Schema 定义的以及那些最常用的数据类型。
在 Turtle 中,文字的数据类型添加在数据后面,如清单 3 所示。
清单 3. 在 RDF 中使用 XML Schema 数据类型
@prefix xsdt: <http://www.w3.org/2001/XMLSchema#>. @prefix mu: <http://aabs.purl.org/music#>. :andrew :boughtInstrument "1987-06-13T10:30:00"^^xsdt:dateTime . |
^^ 将数据类型声明(xsdt:dataType)附加到数据的字符串表示("1987-06-13T10:30:00" 部分)上面。因此它说明的是 “Andrew bought the guitar on 13th June 1987 at ten thirty”。这一规则的例外是,不需要其类型的相关线索就能够明确解析的类型。因此像 5 这样没有任何说明的数字显然是一个整数。类似的,像 Andrew 这样没有任何说明的字符串也只能是一个字符串。布尔类型和小数类型也适用于这种情况。整数、布尔值和小数可以直接给出数字而不需要引号。语句 :guitar :timesRestrung 500 使用了整数。
字符串可以用引号引起来(按照 Tim Berners-Lee 目前最青睐的语言 Python 的一般规则),比如 :guitar :makersModel "GL350" 或者清单 4。
清单 4. 使用 Python 风格的三元组用引号引起多行
:guitar :makersModel """GL350 some more text on a new line (provided you use triple quotes)""" . |
图 4 显示了清单 2、3 和 4 对应的 RDF 图。
图 4. 关于 Andrew 和他的吉他的语句
RDF 没有定义标准数据结构。和一般的编程语言一样,语言设计者使用简单的结构进行扩展。RDF 提供了 ‘包’、‘序列’ 和 ‘替换列表’。这些结构通过三元组实现,暂时先不要管。如果想进一步研究,请阅读 RDF Primer(链接见 参考资料)。Turtle 为这些数据结构提供了原生的语法支持。列表的声明为::andrew :child (:emily :thomas)。
它相当于清单 5。
清单 5. 使用列表将一个主语和谓语用于多个宾语
:andrew :child :emily . :andrew :child :thomas . |
也可在三元组的主语中使用列表:(:thomas :emily) :parent :andrew .。
要在 RDF 中声明没有 URI 的资源,可以使用空白节点标识符 — 本地引用的临时名称。清单 6 显示了 JournalEntries 本体的一个例子:
清单 6. 使用谓语-宾语列表描述单个主语的多条语句
_:JohnConnor a u:User; u:domainLogin "someDomain/john.connor"; u:displayName "John Connor" . |
_:JohnConnor 是一个空白节点(用前导下划线表示),可在本地引用。您可能希望通过这种方式编写 RDF,而不使用 “:JohnConnor”(外部可见的),因为域登录和将资源绑定到了 LDAP(轻型目录访问协议),这可能是您的本地资源。两种选择都可以。
另一种空白节点语法使用 “[]” 表示您不愿提供本地名称的资源。仅用于当前的三元组或者谓语-宾语列表(如清单 7 所示)。
清单 7. 使用空白节点语法和谓语-宾语列表建立没有标识符的完整主语
[] a j:JournalEntry; j:date "20080205T09:00:00"^^xsdt:dateTime; j:user _:JohnConnor; j:notes """Today I learnt how to defraud ATM machines and how to field strip a machine gun blindfolded."""; j:tag "armaments"; j:tag "cash". |
如果没有名称,或者不希望用毫无意义的标识符污染应用程序名称空间,则可以采用这种形式。毕竟,使用 SPARQL,可以根据相关的数据而不仅仅是 URI 来查询资源。使用空白节点的时候,三元组库将独立地定位空白节点标识符。这种形式适用于一次性的资源,因为在资源定义后面的句点之后就无法直接链接一次性资源了。
从上面两个例子可以看到,可用分号让多个三元组共享一个主语。这称为谓语-宾语列表,经常要用到,因为它允许合并关于同一主语的多个语句。事实上,如果没有谓语-宾语列表这种表示法,上面的空白节点表示法就毫无用处。
回页首
RDFS 和 OWL
RDF 特意设计来支持用更抽象的词汇表进行分层扩展。扩展的第一种方式是使用 RDF Vocabulary Description Language(RDF 词汇表描述语言),通常被称为 RDF Schema 或 RDFS。RDFS 为 RDF 增加了类、属性和继承的特性,几乎是面向对象设计者完备的工具箱。OWL 在 RDFS 的基础上提供了及其丰富的工具箱来描述类的属性和关系。OWL 提供了大量的属性来准确描述两个类之间关系的特点。OWL 的主要动机是为本体的语义打下坚实的基础,使推理引擎能够对数据进行自由演绎。
回页首
RDF 类和属性
RDFS 定义了一个三元组谓语 rdfs:type,声明资源的类型。允许声明类资源继承自其他类。清单 8 是类型声明的一个例子。
清单 8. 使用
rdfs:type 和 rdfs:subClassOf 定义类的层次结构
:HeavenlyBody rdfs:type rdfs:Class. :Planet, :Asteroid, :Comet, :Meteor rdfs:subClassOf :HeavenlyBody. |
图 5 定义了一个小型的类层次结构。
图 5. 清单 8 创建的类的层次结构(使用 UML 表示图)
定义类的实例和类声明非常相似。RDFS 通过 rdfs:subClassOf 谓语表明主语是一个类而不是实例(如清单 9 所示),从而区分类声明三元组和成员。
清单 9. 使用
rdfs:type 定义类实例
:Mercury, :Venus, :Earth, :Mars rdfs:type :Planet. :Ceres, :Vesta rdfs:type :Asteroid # ... |
Turtle 为类型声明提供了方便的简写形式(如清单 10 所示)。
清单 10. 使用
a 作为 rdfs:type 的简写形式
:GasGiant rdfs:subClassOf :Planet. :Jupiter, :Saturn, :Uranus, :Neptune a :GasGiant. |
a 仅仅是 rdfs:type 的简写形式,没有其他意义。
RDFS 也提供类的属性。清单 11 说明了属性的声明方法。
清单 11. 为类
:HeavenlyBody 定义属性
:massKg rdfs:domain :HeavenlyBody ; rdfs:range xsdt:double . |
这里声明的属性 :massKg 从 :HeavenlyBody 映射到一个双精度数。换句话说,它表明所有的天体都能有质量。前面的实例声明可以改写为清单 12。
清单 12. 在实例中使用属性
:Earth a :Planet; :massKg "5.9742e24"^^xsdt:double. |
RDFS 提供的设施和 OWL 相比非常少。OWL 提供了大量的方法来描述两个类之间的微妙关系。现在没有足够的时间来讨论,仅通过例子了解一下 OWL(如清单 13 所示)。
清单 13. 使用 OWL 更详细地描述属性
:hasUsedSkill a owl:ObjectProperty ; rdfs:domain :User ; rdfs:range :Skill; owl:equivalentProperty :hasSkill; owl:inverseProperty :hasBeenUsedBy . |
它说明了属性 :hasUsedSkill 和 :User、:Skill 这两类对象有关。它和 :hasSkill 属性相同(表示同一件事)。此外,还断言如果一项技巧被某人 :hasBeenUsedBy,就意味着此人 :hasSkill 和 :hasUsedSkill。换句话说,OWL 允许告诉推理引擎在本体中定义的各种属性之间隐含的等价意义。OWL 非常丰富,不过现在使用 RDFS 就行了,因为本教程没有涉及推理引擎的使用。
还有一个主题本文不打算讨论,即由来已久的关于面向对象和数据建模哪种方法更好的争论。目前来看显然面向对象将统治应用程序开发世界,因此能否方便地建立本体和对象域之间的映射至关重要。LinqToRdf 之类的系统表明建立这样的映射是可能的,面临的真正问题是纳入 OWL 本体的信息太多了。这是祸中得福。
理论讲得够多了。对于 SPARQL 来说,您现在对 RDF 的了解已经够了。上面的简要介绍没有涉及 RDF 之上的层次,也没有讨论已经得到广泛应用的那些本体论,如 FOAF、SIOC 以及 Dublin Core。也没有深入探讨激动人心的推理引擎、规则标记语言或者公式,这些技术都拥有强大的功能,前途无量。也许会在其他教程中分别讨论。现在看看更加实际的问题。需要建立三元组库和 SPARQL 端点。之后就可以开发本体了。
回页首
用 OWL 定义本体
本教程开发了一个简单的程序,可以定义日志项说明您做了什么。然后开发 SPARQL 查询提出各种问题,看看这家虚构的公司中有谁做了什么。
前面曾经提到这些日志条目是一个类似 twitter 的微型博客。需要知道,本教程中所有这些例子都是为了引出后面的解释。日志系统需要 UI 来显示记录的内容。这里不再介绍,因为大多数开发人员都对这方面非常熟悉,而且 developerWorks 很多教程都有详细的介绍(链接参见 参考资料)。
本体定义后面将创建的数据的格式。这个本体论定义了带属性的类。微型博客上的记录将采用符合该本体格式的 Turtle 片段来编写。一旦数据存储到三元组库中,就可以使用 SPARQL 查询。SPARQL 查询返回的结果采用 XML 格式,封装了和查询匹配的变量。很容易提取 XML 信息并显示在 Web 上。
首先定义日志的本体(如清单 14 所示)。实际上非常简单 — 只有两个类。这定义分别称为 JournalEntry 和 User 的两个类。每个User 可以定义任意数量的日志项,每个日志项可以包含日期、对用户的引用和一组标签。
清单 14. 小而完整的日志系统本体
@prefix log: <http://www.w3.org/2000/10/swap/log#> . @prefix string: <http://www.w3.org/2000/10/swap/string#>. @prefix os: <http://www.w3.org/2000/10/swap/os#>. @prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix j: <Journal.n3#>. @prefix : <#>. #JournalEntry class :JournalEntry a owl:Class . :date rdfs:domain :JournalEntry; rdfs:range xsdt:datetime; owl:cardinality 1. :user rdfs:domain :JournalEntry; rdfs:range :User ; owl:cardinality 1. :notes rdfs:domain :JournalEntry; rdfs:range xsdt:string; owl:cardinality 1. :tag rdfs:domain :JournalEntry; rdfs:range xsdt:string . #User class :User a owl:class . :domainLogin rdfs:domain :User; rdfs:range :xsdt:string ; owl:cardinality 1. :displayName rdfs:domain :User; rdfs:range xsdt:string ; owl:maxCardinality 1 . |
下面在 JournalEntries.n3 文件中定义几个 JournalEntry 元素。首先应该定义一个 :User 实例(如清单 15 所示)。
清单 15. 描述作者的本体条目
_:AndrewMatthews a :User; :domainLogin "someDomain/andrew.matthews"; :displayName "Andrew Matthews" . |
可以看到这个条目符合 Journal.n3 中的定义。有了用户条目之后就可以定义日志条目了(如清单 16 所示)。
清单 16. 使用本体创建匿名日志条目
[] a :JournalEntry; :date "20080204"^^xsdt:datetime; :user _:AndrewMatthews; :notes """Today I wrote some more content for the great new SPARQL tutorial that I've been preparing. I used some N3 to do it in, and I defined a simple ontology for defining journal entries. This is an example of one of those entries!"""; :tag "N3"; :tag "RDF"; :tag "OWL"; :tag "tutorial". [] a :JournalEntry; :date "20080205"^^xsdt:datetime; :user _:AndrewMatthews; :notes """Today, I wrote some more content for the tutorial I wrote a section that describes how you set up Joseki.""" :tag "N3"; :tag "Java"; :tag "Joseki"; :tag "configuration"; :tag "Jena". |
这一次没有给出条目的名称,而仅仅定义了一个符合 :JournalEntry 类定义的匿名实例。教程的 源代码文件 中包含更多这样的条目,从而查询起来更有趣。
源代码 中包含支持本体定义的其他日志条目以及需要的有关文件。
- 从本教程的开始部分下载该 zip 文件
- 将 .bat 文件复制到 Joseki 目录
- 将配置文件复制到 Joseki 目录覆盖原来的配置文件 Joseki.ttl。
- 将 RunJoseki.bat 文件中的路径改为 Joseki 下载后的目录。
- 要启动三元组库和 SPARQL 服务器,只需双击 RunJoseki.bat 批处理文件即可。
显示的控制台屏幕最初应该类似于清单 17。
清单 17. Joseki 启动时生成的典型的清单
Starting Joseki 12:19:17 INFO Configuration :: ==== Configuration ==== 12:19:17 INFO Configuration :: Loading : <joseki-config.ttl> 12:19:18 INFO ServiceInitSimple :: Init: Example initializer 12:19:18 INFO Configuration :: ==== Datasets ==== 12:19:18 INFO Configuration :: New dataset: JournalDataset 12:19:18 INFO Configuration :: Default graph : Journal.n3 12:19:18 INFO Configuration :: ==== Services ==== 12:19:18 INFO Configuration :: Service reference: "sparql" 12:19:18 INFO Configuration :: Class name: org.joseki.processors.SPARQL 12:19:18 INFO SPARQL :: SPARQL processor 12:19:18 INFO SPARQL :: Locking policy: none 12:19:18 INFO SPARQL :: Dataset description: true // Web loading: true 12:19:18 INFO Configuration :: Dataset: JournalDataset 12:19:18 INFO Configuration :: ==== Bind services to the server ==== 12:19:18 INFO Configuration :: Service: <sparql> 12:19:18 INFO Configuration :: ==== Initialize datasets ==== 12:19:19 INFO Configuration :: ==== End Configuration ==== 12:19:19 INFO Dispatcher :: Loaded data source configuration: joseki-config.ttl 12:19:19 INFO log :: Logging to org.slf4j.impl.Log4jLoggerAdapter@29d65b via org.mortbay.log.Slf4jLog 12:19:19 INFO log :: jetty-6.1.4 12:19:19 INFO log :: NO JSP Support for /, did not find org.apache.jasper.servlet.JspServlet 12:19:19 INFO log :: Started [email protected]:2020 |
现在可以进行 SPARQL 查询了。Joseki 自带的 Web 服务器提供了 SPARQL 查询表单。表单的位置是 http://localhost:2020/sparql.html。运行 Joseki 之后单击该链接即可打开 SPARQL 查询表单(如图 6 所示)。
图 6. 在 Joseki 上尝试查询的 SPARQLer 网页

Joseki 是接收和响应 SPARQL 查询的 HTTP 端点。它以 Jena Semantic Web 框架为基础,后者提供了三元组库功能。Joseki 还提供了简单的 Java servlet 引擎作为 Web 端点。并利用它呈现 Web 查询表单,允许手动执行查询。真正的产品中不会使用该查询表单。将会使用 SPARQL API(Jena 框架就提供了这样的 API)通过编程来表示查询。实际上没有 Web 也能使用 SPARQL 。如果有本地三元组库,可直接使用 SPARQL 对其进行访问。SPARQL 协议定义了在 Web 上如何通信。
回页首
SPARQL 实践
我们讨论了 RDF、OWL、Turtle 以及下载安装 Joseki SPARQL 服务器的过程。现在看看如何使用 SPARQL。我们将使用 SPARQLer 查询页生成和测试查询。查询开发中最好使用 Firefox,因为在 SPARQLer 查询和结果页面之间来回切换的时候它能够保留查询。从现在开始,开发的查询都和我们的示例应用程序有关。我们将创建查询从示例日志中提取数据片段。
SPARQL 允许从 RDF 数据库(或者三元组库)中查询三元组。表面上看和从关系数据库中提取数据的结构化查询语言(SQL)非常类似。对于那些熟悉数据库的人来说这种相似性没有多少帮助,因为三元组库和关系数据库是完全不同的东西。关系数据库以表为基础,数据都存储在固定的表中,通过外键定义表行之间的关系。三元组库只存储三元组,描述事物的时候可以使用任意数量的三元组。使用关系数据库会受到数据库布局的限制。
RDF 没有外键和主键。它使用的是 URI,万维网的标准引用格式。通过 URI,一个三元组库可以直接链接到任何三元组库的其他任何数据。这就是 Web 分布式的强大所在。
由于三元组库是一个庞大无序的三元组集合,SPARQL 查询通过定义匹配三元组的模板(称为 Graph Pattern)来完成。RDF 和图一节曾经提到,三元组库中的三元组构成了描述一组资源的图。使用 SPARQL 提取三元组库数据需要定义和图中语句相匹配的模式。这将会是类似这样的问题:找出那些描述了 “plays guitar” 的语句的所有主语。清单 18 展示了一个对利用 清单 1 音乐本体定义的数据进行的查询。
清单 18. 确定 Andrew 所奏乐器的 SPARQL 查询。适用于清单 1 中定义的图
PREFIX : <http://aabs.purl.org/music#>
SELECT ?instrument
WHERE {
:andrew :playsInstrument ?instrument .
}
|
本教程中也使用 Turtle,因为 SPARQL 使用 Turtle 形式表示查询图模式。该查询说 “找到主语为 :andrew,谓语为 :playsInstrument的所有三元组,获取并返回匹配三元组中的宾语”。当然,SPARQL 不仅能做这些,不过三元组库建立并运行之后马上就可以实现该功能。您也许希望尽快获得效率,而不需要太多理论,但是没有本体就没有三元组库,没有三元组库就无法测试查询。因此首先要定义本体,运行它并进行查询。现在我们定义了本体和有关的实例数据,可以用这些数据配置 Joseki 了。
回页首
为日志数据集配置 Joseki
本教程采用 Joseki SPARQL 服务器,因为它是免费和开源的,而且是一个非常流行的平台。也可选择其他三元组库和 SPARQL 端点来存放本体和执行查询。
Joseki 和 Jena 都是用 Java 语言编写的,不过在本教程中不需要编写 Java 代码。只需要正确配置服务器,让它指向您的文件,并告诉构造什么样的图即可。Joseki 配置文件是定义资源的 Turtle 文件,这些资源描述提供的图。描述数据文件,还可以定义推理引擎来处理 RDF 中定义的规则。真正的应用程序中不会使用 SPARQLer 查询页面,而使用 API 通过编程方式向 Joseki 发出查询,并对结果进行解码,以在程序中使用(如图 7 所示)。
图 7. 典型的语义 Web 应用程序体系结构

首先定义存放服务数据的服务。称为 “JournalService”。清单 19 显示了服务配置的内容。
清单 19. 服务配置
[] rdf:type joseki:Service ; rdfs:label "SPARQL on the Professional Journal model" ; joseki:serviceRef "journal" ; joseki:dataset _:JournalDataset ; joseki:processor joseki:ProcessorSPARQL_FixedDS . |
Jena 和 Joseki(本教程中使用的工具)的配置设置都使用 Turtle。总而言之,上述片段定义了类型为 joseki:Service 的一个实体,标签为 “SPARQL on the Professional Journal model”。配置文件中的其他实体通过 joseki:serviceRef “journal” 间接引用它。它存放后面将定义的数据集 _:JournalDataset。
现在必须定义前面所提到的 _:JournalDataset 数据集。为此,定义一个 ja:RDFDataset 类型的实体,如清单 20 所示。
清单 20. 数据集配置
_:JournalDataset rdf:type ja:RDFDataset ; ja:defaultGraph _:JournalGraph ; rdfs:label "JournalDataset" ; ja:namedGraph [ ja:graphName <http://aabs.purl.org/ontologies/2007/11/journal> ; ja:graph _:JournalGraph ] ; . |
这段 RDF 定义了由 _:JournalDataset 标识的 RDFDataset,其默认图定义为 _:JournalGraph。它定义了可以访问图中数据的 URI,并提供了数据集内容的默认访问方式。最后还需要定义本体及其数据的图。前面用 _:JournalGraph 指代这个图。清单 21 显示了图的定义。
清单 21. 图的定义
_:JournalGraph rdf:type ja:MemoryModel ; rdfs:label "JournalGraph" ; ja:content [ja:externalContent <file:C:/dev/sparqlTutorial/Joseki/Journal.n3>] ; ja:content [ja:externalContent <file:C:/dev/sparqlTutorial/Joseki/JournalEntries.n3>]. |
最后一个元素定义了一个图 — Giant Global Graph 或 GGG 的一小部分,Tim Burners-Lee 最近尝试用它标记语义 Web。要记住,所有的 RDF 定义的都是图。因此毫不奇怪,三元组库的配置就是发现数据和将其放入图中,或者指定公开这些图的方式。
要记住,下载的 zip 文件解压到哪里,ja:content URI 就应该指向哪里。我们将定义一个内存模型对象 JournalGraph,链接到两个外部磁盘文件 Journal.n3 和 JournalEntries.n3。这就是下面要关注的焦点 — 它们就是定义本体的地方(这是语义 Web 的说法,程序员更愿意称之为对象或者域模型)。