御膳房:构建大数据的美食厨房
转自 http://m.csdn.net/article/a/2014-09-27/15820226
早在2008年,阿里巴巴即确定了云计算、大数据为中心的DT战略,并在云计算底层平台的搭建上取得了令业界瞩目的成就。同时,金币的另一面,大数据的业务尤其是基于淘宝、天猫等电子商务平台的数据业务也是风生水起,领行业之先。
早期“淘宝指数”、“数据魔方”不但让用户有了耳目一新的体验,更为店铺卖家提供了运营管理的数据工具。有了云计算稳定可靠、高弹性、大计算能力之后,阿里内部的大数据应用迎来了井喷式的发展。
这里我们再分享另一个基于飞天的ODPS的应用模型——“御膳房”(clouddata.taobao.com),如何将数据转化为生产资料,来激活生产力。作为阿里巴巴的数据引擎业务,御膳房就是专注于为ISV、商家、非电商用户提供开放式大数据服务平台。2013年3月上线以来,一年多的时间,与御膳房深度合作的第三方服务商已经超过300个,提供了包含流量推广、商品管理、数据分析、CRM、ERP、广告精准投放等多个支撑工具,覆盖了180万天猫、淘宝商家。
目前,御膳房已经开放了商品、商家、客服绩效、品牌、行业五大主题数据,并提供了额外的数据仓库,其中有良好组织的各种数据供开发者来加工和使用。通过御膳房,专注数据的商家及相关服务商可以选择自己所需要的数据主题并完成定制化的数据开发工作,相关数据聚合结果以API接口的形式发布使用。谈到命名之初,阿里数据平台事业部商家数据业务部高级技术专家王贲表示:“御膳房,实际上是数据厨房的形象比喻。我们就像一个厨房,提供了最优质的原材料、最锋利的工具,让开发者、服务商这样的大厨能够快速实现大数据应用的各种idea。”
御膳房:电子商务生态系发展的必然
御膳房的出现,是基于淘宝的电商生态系统发展到一定阶段的必然需求。王贲表示:“淘宝上不断涌现的大卖家和品牌商,以及服务于众多电商的ISV(独立软件开发商),发展到一定阶段都会面临的问题:如何实现全链路数据的计算、存储、交换和分析。事实上,在淘宝平台、CRM、库存甚至其他各类第三方系统中,那些已经沉淀下来的数据往往都是彼此独立而分散的,如果这些数据能够在统一平台上实现聚合,将释放出更加强大的能量。”而这些大量的数据,光靠ISV自己的机器是无法完成计算的,需要有更强大的计算能力。
御膳房应运而生,成为对外可以提供包含大数据计算、存储、挖掘、分析在内的一站式大数据服务的平台(图1)。具体来看,御膳房能够为开发者提供:
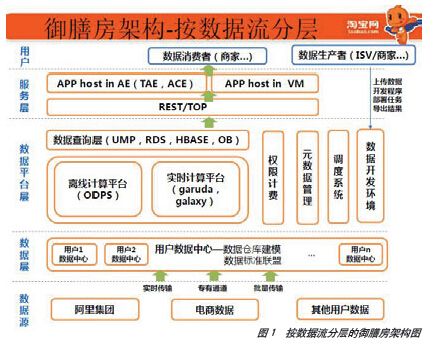
■ 完善准确的基础指标定义,计算口径,检验工具等,确保数据标准、唯一可靠;
■ 云数据中心(仓库)解决方案,离线分布式计算平台及强大的算法环境,自主提交计算任务,自主开发模型挖掘数据价值,大数据计算快速响应;
■ 支持隔离的数据存储、独立的数据任务部署,确保御膳房内的数据交易与数据开发安全;
■ 根据需求灵活定制API,数据输出符合TOP API规范;
■ R、Python、Xlab在内的主流大数据挖掘工具,支持模型研究与快速迭代试验,提升数据价值;
■ 在商品、商家、客服绩效、品牌、行业等主题之外,还将继续开放行业、竞品等数据,同时开发者也可以将个人数据上传使用。在王贲看来,“我们是基于云平台实现数据服务的PaaS平台,提供的是Data platform as a Service、Data warehouse as aService和Data center as a Service。自2013年3月采用邀请制的御膳房0.1上线到现在,御膳房发展非常迅猛。有开发能力的商家和ISV希望能够完整地使用御膳房的服务,还有很多非电商行业,比如气象局、交通局、高校科研机构等,也在进行深度合作的沟通。”
应对内外技术挑战
御膳房曾在技术上面临着巨大的挑战。御膳房原型验证阶段基于Hadoop集群,面对Hadoop在部署、Fix Bug、升级、资源隔离、保证用户数据访问安全和BI应用程序安全等方面缺乏充分的底层支持,团队需要投入很大精力来进行开发。
王贲表示,当时的主要困难有以下四个方面。
■ Hadoop不支持多租户,没有类似ODPS的project的机制,并且基于project进行资源管理,这就导致御膳房作为PaaS层平台,要考虑和解决这些本该在IaaS层平台直接解决的问题。比如最简单的难题是命名空间不能区分不同用户。为了帮助用区分命名,团队做了表名的前缀,但这却为后续开发维护带来了不小的烦恼。
■ Hadoop资源隔离和Quota限制不完善,而御膳房作为大数据公有云,对这一部分要求很高。
■ Hadoop对数据的权限管理很薄弱,御膳房为了提供对外服务,需要很强的底层权限模型支持。御膳房在迁移到ODPS之前,为了做权限管理,自己解析Hive SQL,做了自己的鉴权系统,对任意一个SQL语句,都要做鉴权。
■ 数据安全和系统安全,对御膳房这样的公有云大数据平台而言,特别重要,而Hadoop是按照私有云理念设计的,对这些方面考虑不太多。
而随着飞天5K成功与ODPS内测,团队看到了完美解决上述问题、大幅提高效率的希望。在详细评测飞天平台和ODPS之后,御膳房毅然停止Hadoop集群的开发,采用飞天和ODPS为底层计算和数据分析平台。仅仅1个月的时间,技术团队就完成了从Hive到ODPS,从MySQL到UMP(Unified MySQL Platform)的底层云化迁移。而后,M/R开发环境上线,算法环境上线,新算法环境上线,御膳房正式成为阿里统一的对外数据平台服务,服务商家和ISV。
当然,这一过程也并非一帆风顺。在王贲看来,因为御膳房“对外开放大数据平台+数据”的模式比较超前,在世界上并没有可直接学习的对象,所以来自内外的挑战都非常多。
首先是来自产品设计本身的挑战。作为原创模式的平台级产品,对产品经理的要求极高。为了解决不同环节中遇到的问题,整个团队进行了大量的探索。比如产品经理和架构师经常是在一起设计产品的,不仅要求产品经理必须掌握大数据相关技术,也要求架构师能够理解产品设计理念。
其次是对技术团队的挑战。要在架构上需要对云计算、大数据平台、数据挖掘、数据分析等相关领域技术都有深刻的理解;系统的复杂度很考验技术团队的设计和编码能力;对测试团队的要求也很高,举个例子,测试算法环境,就需要测试同事能理解和使用算法开发工具。
最后是开放和安全既是一对矛盾,又相辅相成。但本质来看,没有安全保障,是不可能做好开放的大数据平台的。所以御膳房为了保障安全,做了大量工作:比如集群隔离,代码自动安全审核,数据安全等级定级,继承并完善阿里集团数据安全标准,开发环境与线上环境隔离,数据授权安全审核等,同时还从需求出发,推动ODPS进行了系列改进,如进程级沙箱,支持大量Project,强化Quota支持,支持Quota Group等。
挑战是过程,快乐是结果。王贲说:“御膳房是第一个基于飞天+ODPS对外提供服务的应用,我们切实体会到了飞天与ODPS在稳定性、海量数据平台化管理、安全性等方面的优势。”而在此基础上,技术团队还进一步提供了数据开发、算法开发、调度体系(Octopus)、监控报警等服务。
比如在数据开发方面,御膳房不仅提供了Eclipse开发插件来辅助MapReduce开发与调试,还提供了Eclipse开发插件来辅助UDF(User Defined Function)开发与调试。而算法分析上,御膳房更是提供了从Hive/UDF、MapReduce、Python、R、Xlab/Xlib(XLib是ODPS的分布式算法库,支持分类预测、回归、聚类、关联分析、矩阵计算等)的“工具链”。“作为一站式数据挖掘平台,工具可自由选择,两两之间,都可协同工作。”随着V0.8.1版本正式上线,御膳房还提供了对接RDS数据库数据上传、新建表复制表字段、补历史数据等功能。
聚合数据,走向更加开放的数据平台
随着业务的爆发式增长,数据正在成倍增加,汇集成海。而要数据产生更高的价值,不同数据之间的交换和分享必不可少。御膳房目前已经提供包含商品数据、店铺数据、行业数据、品牌数据、聚划算数据、广告数据、气象数据、用户标签数据在内的多种数据类型,以及销量预测、复购分析、购买预测、IDmapping用户匹配、人群透视、用户行为等多种算法模型。
未来,御膳房要更加开放。王贲表示:“御膳房会进一步强化多租户理念和架构,还将联合更多如MSTR、Cognos、数云和Tableau等第三方伙伴建立起用户(租户)数据中心和其上的App生态,并希望在电商以外,联合更多如气象、交通、物流、制造等传统企业,实现数据进一步交换和分享,为打造大数据生态而努力。”