Redis的字典(dict)rehash过程源码解析
分类: redis 分布式系统 2014-04-30 13:35 439人阅读 评论(0) 收藏 举报
Redis的内存存储结构是个大的字典存储,也就是我们通常说的哈希表。Redis小到可以存储几万记录的CACHE,大到可以存储几千万甚至上亿的记录(看内存而定),这充分说明Redis作为缓冲的强大。Redis的核心数据结构就是字典(dict),dict在数据量不断增大的过程中,会遇到HASH(key)碰撞的问题,如果DICT不够大,碰撞的概率增大,这样单个hash 桶存储的元素会越来愈多,查询效率就会变慢。如果数据量从几千万变成几万,不断减小的过程,DICT内存却会造成不必要的浪费。Redis的dict在设计的过程中充分考虑了dict自动扩大和收缩,实现了一个称之为rehash的过程。使dict出发rehash的条件有两个:
1)总的元素个数 除 DICT桶的个数得到每个桶平均存储的元素个数(pre_num),如果 pre_num > dict_force_resize_ratio,就会触发dict 扩大操作。dict_force_resize_ratio = 5。
2)在总元素 * 10 < 桶的个数,也就是,填充率必须<10%,DICT便会进行收缩,让total / bk_num 接近 1:1。
dict rehash扩大流程:

源代码函数调用和解析:
dictAddRaw->_dictKeyIndex->_dictExpandIfNeeded->dictExpand,这个函数调用关系是需要扩大dict的调用关系,
_dictKeyIndex函数代码:
- static int _dictKeyIndex(dict *d, const void *key)
- {
- unsigned int h, idx, table;
- dictEntry *he;
- // 如果有需要,对字典进行扩展
- if (_dictExpandIfNeeded(d) == DICT_ERR)
- return -1;
- // 计算 key 的哈希值
- h = dictHashKey(d, key);
- // 在两个哈希表中进行查找给定 key
- for (table = 0; table <= 1; table++) {
- // 根据哈希值和哈希表的 sizemask
- // 计算出 key 可能出现在 table 数组中的哪个索引
- idx = h & d->ht[table].sizemask;
- // 在节点链表里查找给定 key
- // 因为链表的元素数量通常为 1 或者是一个很小的比率
- // 所以可以将这个操作看作 O(1) 来处理
- he = d->ht[table].table[idx];
- while(he) {
- // key 已经存在
- if (dictCompareKeys(d, key, he->key))
- return -1;
- he = he->next;
- }
- // 第一次进行运行到这里时,说明已经查找完 d->ht[0] 了
- // 这时如果哈希表不在 rehash 当中,就没有必要查找 d->ht[1]
- if (!dictIsRehashing(d)) break;
- }
- return idx;
- }
- static int _dictExpandIfNeeded(dict *d)
- {
- // 已经在渐进式 rehash 当中,直接返回
- if (dictIsRehashing(d)) return DICT_OK;
- // 如果哈希表为空,那么将它扩展为初始大小
- // O(N)
- if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
- // 如果哈希表的已用节点数 >= 哈希表的大小,
- // 并且以下条件任一个为真:
- // 1) dict_can_resize 为真
- // 2) 已用节点数除以哈希表大小之比大于
- // dict_force_resize_ratio
- // 那么调用 dictExpand 对哈希表进行扩展
- // 扩展的体积至少为已使用节点数的两倍
- // O(N)
- if (d->ht[0].used >= d->ht[0].size &&
- (dict_can_resize ||
- d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
- {
- return dictExpand(d, d->ht[0].used*2);
- }
- return DICT_OK;
- }
dict rehash缩小流程:
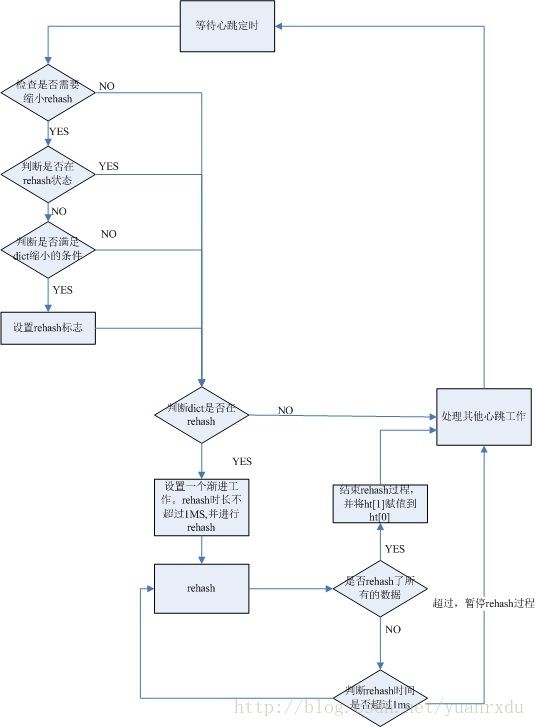
源代码函数调用和解析:
serverCron->tryResizeHashTables->dictResize->dictExpand
serverCron函数是个心跳函数,调用tryResizeHashTables段为:
- int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
- ....
- if (server.rdb_child_pid == -1 && server.aof_child_pid == -1) {
- // 将哈希表的比率维持在 1:1 附近
- tryResizeHashTables();
- if (server.activerehashing) incrementallyRehash(); //进行rehash动作
- }
- ....
- }
- void tryResizeHashTables(void) {
- int j;
- for (j = 0; j < server.dbnum; j++) {
- // 缩小键空间字典
- if (htNeedsResize(server.db[j].dict))
- dictResize(server.db[j].dict);
- // 缩小过期时间字典
- if (htNeedsResize(server.db[j].expires))
- dictResize(server.db[j].expires);
- }
- }
htNeedsResize函数是判断是否可以需要进行dict缩小的条件判断,填充率必须>10%,否则会进行缩小,具体代码如下:
- int htNeedsResize(dict *dict) {
- long long size, used;
- // 哈希表大小
- size = dictSlots(dict);
- // 哈希表已用节点数量
- used = dictSize(dict);
- // 当哈希表的大小大于 DICT_HT_INITIAL_SIZE
- // 并且字典的填充率低于 REDIS_HT_MINFILL 时
- // 返回 1
- return (size && used && size > DICT_HT_INITIAL_SIZE &&
- (used*100/size < REDIS_HT_MINFILL));
- }
- int dictResize(dict *d)
- {
- int minimal;
- // 不能在 dict_can_resize 为假
- // 或者字典正在 rehash 时调用
- if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
- minimal = d->ht[0].used;
- if (minimal < DICT_HT_INITIAL_SIZE)
- minimal = DICT_HT_INITIAL_SIZE;
- return dictExpand(d, minimal);
- }
- int dictExpand(dict *d, unsigned long size)
- {
- dictht n; /* 被转移数据的新hash table */
- // 计算哈希表的真实大小
- unsigned long realsize = _dictNextPower(size);
- if (dictIsRehashing(d) || d->ht[0].used > size || d->ht[0].size == realsize)
- return DICT_ERR;
- // 创建并初始化新哈希表
- n.size = realsize;
- n.sizemask = realsize-1;
- n.table = zcalloc(realsize*sizeof(dictEntry*));
- n.used = 0;
- // 如果 ht[0] 为空,那么这就是一次创建新哈希表行为
- // 将新哈希表设置为 ht[0] ,然后返回
- if (d->ht[0].table == NULL) {
- d->ht[0] = n;
- return DICT_OK;
- }
- /* Prepare a second hash table for incremental rehashing */
- // 如果 ht[0] 不为空,那么这就是一次扩展字典的行为
- // 将新哈希表设置为 ht[1] ,并打开 rehash 标识
- d->ht[1] = n;
- d->rehashidx = 0;
- return DICT_OK;
- }
字典dict的rehashidx被设置成0后,就表示开始rehash动作,在心跳函数执行的过程,会检查到这个标志,如果需要rehash,就行进行渐进式rehash动作。函数调用的过程为:
serverCron->incrementallyRehash->dictRehashMilliseconds->dictRehash
incrementallyRehash函数代码:
- /*
- * 在 Redis Cron 中调用,对数据库中第一个遇到的、可以进行 rehash 的哈希表
- * 进行 1 毫秒的渐进式 rehash
- */
- void incrementallyRehash(void) {
- int j;
- for (j = 0; j < server.dbnum; j++) {
- /* Keys dictionary */
- if (dictIsRehashing(server.db[j].dict)) {
- dictRehashMilliseconds(server.db[j].dict,1);
- break; /* 已经耗尽了指定的CPU毫秒数 */
- }
- ...
- }
dictRehashMilliseconds函数是按照指定的CPU运算的毫秒数,执行rehash动作,每次一个100个为单位执行。代码如下:
- /*
- * 在给定毫秒数内,以 100 步为单位,对字典进行 rehash 。
- */
- int dictRehashMilliseconds(dict *d, int ms) {
- long long start = timeInMilliseconds();
- int rehashes = 0;
- while(dictRehash(d,100)) {/*每次100步数据*/
- rehashes += 100;
- if (timeInMilliseconds()-start > ms) break; /*耗时完毕,暂停rehash*/
- }
- return rehashes;
- }
- /*
- * 执行 N 步渐进式 rehash 。
- *
- * 如果执行之后哈希表还有元素需要 rehash ,那么返回 1 。
- * 如果哈希表里面所有元素已经迁移完毕,那么返回 0 。
- *
- * 每步 rehash 都会移动哈希表数组内某个索引上的整个链表节点,
- * 所以从 ht[0] 迁移到 ht[1] 的 key 可能不止一个。
- */
- int dictRehash(dict *d, int n) {
- if (!dictIsRehashing(d)) return 0;
- while(n--) {
- dictEntry *de, *nextde;
- // 如果 ht[0] 已经为空,那么迁移完毕
- // 用 ht[1] 代替原来的 ht[0]
- if (d->ht[0].used == 0) {
- // 释放 ht[0] 的哈希表数组
- zfree(d->ht[0].table);
- // 将 ht[0] 指向 ht[1]
- d->ht[0] = d->ht[1];
- // 清空 ht[1] 的指针
- _dictReset(&d->ht[1]);
- // 关闭 rehash 标识
- d->rehashidx = -1;
- // 通知调用者, rehash 完毕
- return 0;
- }
- assert(d->ht[0].size > (unsigned)d->rehashidx);
- // 移动到数组中首个不为 NULL 链表的索引上
- while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
- // 指向链表头
- de = d->ht[0].table[d->rehashidx];
- // 将链表内的所有元素从 ht[0] 迁移到 ht[1]
- // 因为桶内的元素通常只有一个,或者不多于某个特定比率
- // 所以可以将这个操作看作 O(1)
- while(de) {
- unsigned int h;
- nextde = de->next;
- /* Get the index in the new hash table */
- // 计算元素在 ht[1] 的哈希值
- h = dictHashKey(d, de->key) & d->ht[1].sizemask;
- // 添加节点到 ht[1] ,调整指针
- de->next = d->ht[1].table[h];
- d->ht[1].table[h] = de;
- // 更新计数器
- d->ht[0].used--;
- d->ht[1].used++;
- de = nextde;
- }
- // 设置指针为 NULL ,方便下次 rehash 时跳过
- d->ht[0].table[d->rehashidx] = NULL;
- // 前进至下一索引
- d->rehashidx++;
- }
- // 通知调用者,还有元素等待 rehash
- return 1;
- }
总结,Redis的rehash动作是一个内存管理和数据管理的一个核心操作,由于Redis主要使用单线程做数据管理和消息效应,它的rehash数据迁移过程采用的是渐进式的数据迁移模式,这样做是为了防止rehash过程太长堵塞数据处理线程。并没有采用memcached的多线程迁移模式。关于memcached的rehash过程,以后再做介绍。从redis的rehash过程设计的很巧,也很优雅。在这里值得注意的是,redis在find数据的时候,是同时查找正在迁移的ht[0]和被迁移的ht[1]。防止迁移过程数据命不中的问题。