Spark机器学习3
3. Spark上数据的获取、处理与准备
3.1 获取公开数据集
MovieLens数据集:包含表示多个用户对多部电影的10万次评级数据,也包含电影元数据和用户属性信息。
- 下载数据集,解压
unzip ml-100k.zip- 会创建一个名为ml-100k的文件夹,进入文件夹
cd ml-100k其中重要的文件有u.user(用户属性文件)、u.item(电影元数据)和u.data(用户对电影的评级)
- u.user文件包含user.id(用户ID)、age(年龄)、gender(性别)、occupation(职业)、和ZIP code(邮政编码)这些属性。
head -5 u.user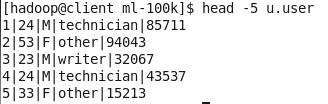
- u.item文件则包含movie id、title、release date、IMDB link和电影分类相关属性。
head -5 u.item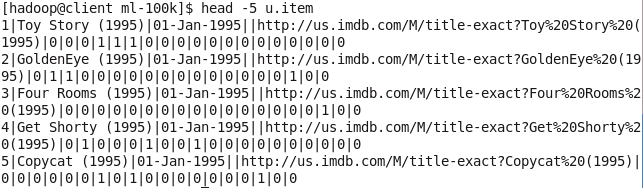
- u.data文件包含user id、movie id、rating(从1到5)和timestamp属性。
head -5 u.data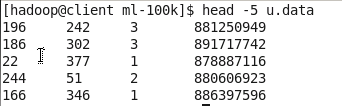
3.2 探索与可视化数据
通过IPython交互式终端和matplotlib库来对数据进行处理和可视化。需要安装Anaconda,选择python 2.7。
在启动PySpark终端是,我们可以使用IPython而非标准的Python shell。启动时向IPython传入其他参数,让它在启动时也启用pylab功能。
IPYTHON=1 IPYTHON_OPTS="--pylab" ./bin/pyspark
3.2.1 探索用户数据
user_data = sc.textFile("PATH/ml-100k/u.user")
user_data.first()其输出如下:
![]()
统计用户、性别、职业和邮编的数目
user_fields = user_data.map(lambda line: line.split("|"))
num_users = user_fields.map(lambda fields: fields[0]).count()
num_genders = user_fields.map(lambda fields: fields[2]).distinct().count()
num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count()
num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count()
print "Users: %d, genders: %d, occupations: %d, ZIP codes: %d" % (num_users, num_genders, num_occupations, num_zipcodes)输出如下:
![]()
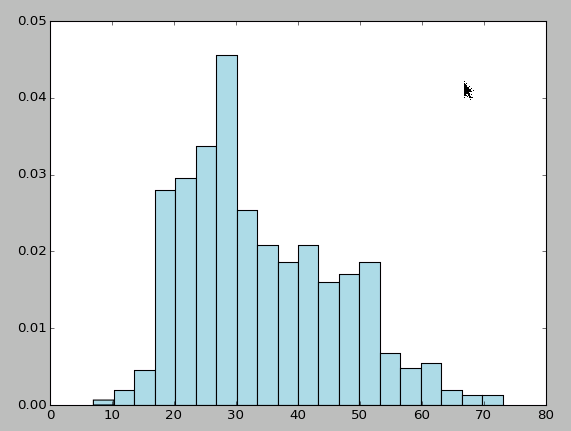
接着用matplotlib的hist函数创建一个直方图,以分析用户年龄的分布情况:
ages = user_fields.map(lambda x: int(x[1])).collect()
hist(ages, bins=20, color='lightblue', normed=True) fig = matplotlib.pyplot.gcf() fig.set_size_inches(16, 10)如下图所示:
数据中对职业的描述用的是文本,所以需要对其稍作处理以便bar函数使用:
count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect()
x_axis1 = np.array([c[0] for c in count_by_occupation])
y_axis1 = np.array([c[1] for c in count_by_occupation])
x_axis = x_axis1[np.argsort(y_axis1)]
y_axis = y_axis1[np.argsort(y_axis1)]
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(x_axis)
plt.bar(pos, y_axis, width, color='lightblue')
plt.xticks(rotation=30)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)3.2.2 探索电影数据
movie_data = sc.textFile("PATH/ml-100k/u.item")
print movie_data.first()![]()
num_movies = movie_data.count()
print "Movies: %d" % num_movies![]()
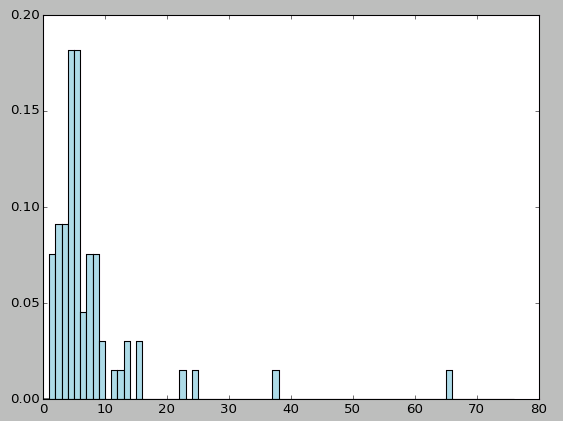
电影数据中有些数据不完整,故需要一个函数来处理解析release date时可能出现的解析错误,命名该函数为convert_year:
def convert_year(x):
try:
return int(x[-4:])
except:
return 1900movie_fields = movie_data.map(lambda lines: lines.split("|"))
years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x))
years_filtered = years.filter(lambda x: x != 1900)
movie_ages = years_filtered.map(lambda yr: 1998-yr).countByValue()
values = movie_ages.values()
bins = movie_ages.keys()
hist(values, bins=bins, color='lightblue', normed=True)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16,10)如下图所示:
3.2.3 探索评级数据
rating_data_raw = sc.textFile("PATH/ml-100k/u.data")
print rating_data_raw.first()![]()
num_ratings = rating_data_raw.count()
print "Ratings: %d" % num_ratings![]()
评级次数共有10万。
rating_data = rating_data_raw.map(lambda line: line.split("\t"))
ratings = rating_data.map(lambda fields: int(fields[2]))
max_rating = ratings.reduce(lambda x, y: max(x, y))
min_rating = ratings.reduce(lambda x, y: min(x, y))
mean_rating = ratings.reduce(lambda x, y: x + y) / float(num_ratings)
median_rating = np.median(ratings.collect())
ratings_per_user = num_ratings / num_users
ratings_per_movie = num_ratings / num_movies
print "Min rating: %d" % min_rating
print "Max rating: %d" % max_rating
print "Average rating: %2.2f" % mean_rating
print "Median rating: %d" % median_rating
print "Average # of ratings per user: %2.2f" % ratings_per_user
print "Average # of ratings per movie: %2.2f" % ratings_per_movie![]()
![]()
![]()
![]()
![]()
![]()
Spark对RDD也提供一个名为states的函数,该函数包含一个数值变量用于做类似的统计:
ratings.stats()如下图所示:
![]()
count_by_rating = ratings.countByValue()
x_axis = np.array(count_by_rating.keys())
y_axis = np.array([float(c) for c in count_by_rating.values()])
# we normalize the y-axis here to percentages
y_axis_normed = y_axis / y_axis.sum()
pos = np.arange(len(x_axis))
width = 1.0
ax = plt.axes()
ax.set_xticks(pos + (width / 2))
ax.set_xticklabels(x_axis)
plt.bar(pos, y_axis_normed, width, color='lightblue')
plt.xticks(rotation=30)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(16, 10)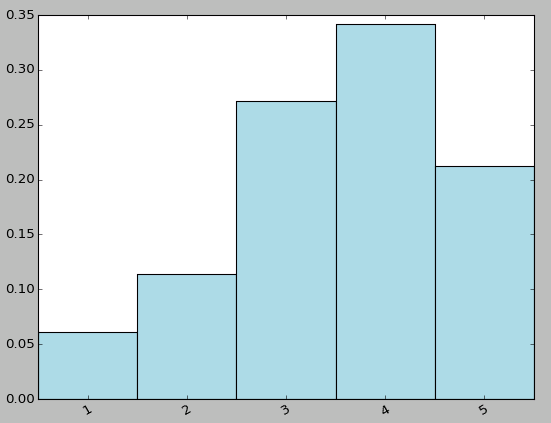
user_ratings_grouped = rating_data.map(lambda fields: (int(fields[0]), int(fields[2]))).groupByKey()
user_ratings_byuser = user_ratings_grouped.map(lambda (k, v): (k, len(v)))
user_ratings_byuser.take(5)
![]()
user_ratings_byuser_local = user_ratings_byuser.map(lambda (k, v): v).collect()
hist(user_ratings_byuser_local, bins=200, color='lightblue', normed=True) fig = matplotlib.pyplot.gcf() fig.set_size_inches(16,10) 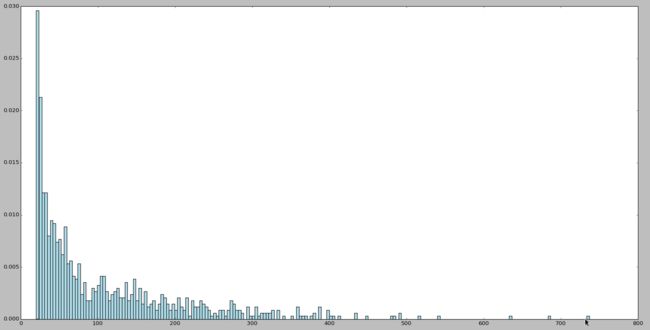
3.3 处理与转换数据
- 为了让原始数据可用于机器学习算法,需要先对其进行清理,并可能需要将其进行各种转换,之后才能从转换后的数据里提取有用的特征。
- 现实中的数据会存在信息不规整、数据点缺失和异常值问题,理想情况下,我们会修复非规整数据,但很多数据集都源于一些难以重现的收集过程。大致处理方法如下:
- 过滤掉或删除非规整或有值缺失的数据
- 填充非规整或缺失的数据
- 用零值、全局期望或中值来填充
- 根据相邻或类似的数据点来做插值
- 对异常值做鲁棒处理
- 对可能的异常值进行转换
3.4 从数据中提取有用特征
- 特征:用于模型训练的变量。几乎所有机器学习模型都是与用向量表示的数值特征打交道。因此,我们需要将原始数据转换为数值。
- 特征可以概括地分为:数值特征、类别特征、文本特征和其他特征。
3.4.1 类别特征
- 名义变量:类别特征各个可能取值之间没有顺序关系
- 有序变量:类别特征各个可能取值之间有顺序关系,如评级,从定义上说评级5会高于或是好于评级1。
将类别特征表示为数字形式,常可借助k之1(1-of-k)方法进行。
- 将名义变量表示为可用于机器学习任务的形式,会需要借助如k之1编码这样的方法。
- 有序变量的原始值可能就能直接使用,但也常会经过和名义变量一样的编码处理。
k之1编码:假设变量可取的值有k个,如果对这些值用1到k编序,则可以用长度为k的二元向量来表示一个变量的取值,在这个向量里,该取值对应的序号所在的元素为1,其他元素都为0.