快速镜像同步(Fast Mirror Resync)
转载自:http://book.51cto.com/art/201108/288296.htm
在Oracle Database 11g以前,ASM磁盘的损坏通常都是一种灾难,即使你的ASM磁盘组是受Normal Redundancy或High Redundancy的保护。因为在Oracle 10g中,损坏的ASM磁盘会马上offline,进而这个损坏的磁盘立刻会被Oracle drop掉。以后即便你修复了这块磁盘,重新加入原先磁盘组的时候,Oracle也会做rebalance操作来完全重构这个磁盘上的数据,这个rebalance操作之前有提到──可能会极为耗时。试想如果这个损坏的磁盘仅仅是因为掉电或者仅仅损坏了几个块就需要完全重构,无疑效率是非常低的。
Oracle意识到这是个问题,于是在11g里引入了一个参数disk_repair_time,其默认值是3.6小时并且用户可以修改。其含义是当损坏的磁盘offline后,Oracle并不会马上将其drop,而是会等待参数disk_repair_time所表示的时间,在这段时间内,Oracle会记录下对损坏的磁盘上的extent所做的修改,一旦这个offline的损坏的磁盘在disk_repair_time所表示的时间内重新online,则Oracle会将之前所记录的对这个磁盘上extent所做的修改重新同步到这块盘上,从而高效地同步了数据(因为这里只同步了offline后修改的extent上的数据),避免了极为耗时的重构全部数据的rebalance过程─这就是Oracle 11g里引入的快速镜像同步(Fast Mirror Reync)。
快速镜像同步的原理可以通过图6-31来说明。
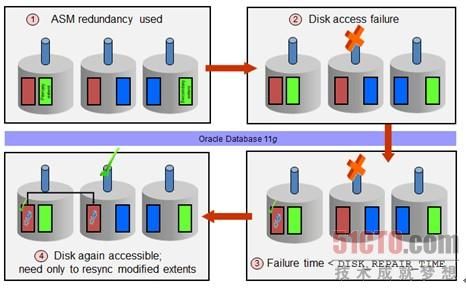 |
| 图6-31 Oracle Databaes 11g快速镜像同步示意图 |
- SQL> create diskgroup DGTEST normal redundancy
disk '/dev/raw/raw1','/dev/raw/raw2';- attribute 'compatible.rdbms'='11.1','compatible.asm'='11.1';
- Diskgroup created.
- SQL> select group_number,name from
v$asm_diskgroup where group_number=1;- GROUP_NUMBER NAME
- ------------ --------------------
- 1 DGTEST
可以从视图v$asm_attribute中查看disk_repair_time的值:
- SQL>select name,value from v$asm_attribute where group_number=1;
- NAME VALUE
- -------------------- --------------------
- disk_repair_time 3.6h
- au_size 1048576
- compatible.asm 11.1.0.0.0
- compatible.rdbms 11.1.0.0.0
现在连上数据库的实例,并创建一个测试表空间testtbs:
- SQL> create tablespace TESTTBS datafile '+DGTEST' size 20m;
- Tablespace created.
然后关闭上述数据库实例并且dismount上述磁盘组:
- SQL> alter diskgroup dgtest dismount;
- Diskgroup altered.
接着更改/dev/raw/raw1的权限以模拟磁盘损坏:
- [root@11g ~]# chown root:root /dev/raw/raw1
- [root@11g ~]# ls -ltr /dev/raw/raw1
- crw-rw---- 1 root root 162, 1 Jan 14 15:23 /dev/raw/raw1
可以看到,现在DGTEST当然是mount不起来了:
- SQL> alter diskgroup dgtest mount;
- alter diskgroup dgtest mount
- *
- ERROR at line 1:
- ORA-15032: not all alterations performed
- ORA-15040: diskgroup is incomplete
- ORA-15042: ASM disk "0" is missing
像上述这种normal redundancy的磁盘组坏了一块盘的情况,在Oracle 11g中我们可以使用force关键字强制mount:
- SQL> alter diskgroup dgtest mount force;
- Diskgroup altered.
从结果里我们可以看到/dev/raw/raw1所对应的DGTEST_0000所对应的repaire_time是12960秒,也就是缺省的3.6小时:
- SQL>select path,name,repair_timer from
v$asm_disk where group_number=1;- PATH NAME REPAIR_TIMER
- --------------- -------------------- ------------
- DGTEST_0000 12960
- /dev/raw/raw2 DGTEST_0001 0
现在我们重新连上数据库实例并对表空间testtbs添加一个数据文件,以模拟在有offline磁盘存在情况下的数据修改:
- SQL> alter tablespace testtbs add datafile '+DGTEST' size 20m;
- Tablespace altered.
接着把/dev/raw/raw1的权限改回来以模拟损坏的磁盘已经修好了(chown oracle.dba /dev/raw/raw1)。现在可以对/dev/raw/raw1所对应的DGTEST_0000执行online操作了:
- SQL> alter diskgroup dgtest online disk DGTEST_0000;
- Diskgroup altered.
等Oracle执行完快速镜像同步后,可以看到现在/dev/raw/raw1已经恢复正常:
- SQL> select path,header_status,mount_status
from v$asm_disk where group_number=1;- PATH HEADER_STATUMOUNT_S
- ----------------------------------
- /dev/raw/raw2MEMBER CACHED
- /dev/raw/raw1MEMBER CACHED