C++基础学习教程(四)
2.9字符专题
2.9.1类型同义词
也就是typedef声明,这个东西就是相当于起绰号,为了方便记忆和简化而生。相信在学习其他语言的时候一定有所了解,在此不再赘述。
再次示例一个之前写过的用typedef改写的程序:
/*************************************************************************
> File Name: char_count.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月24日 星期六 21时15分10秒
************************************************************************/
#include <iomanip>
#include <ios>
#include<iostream>
#include<string>
#include <map>
using namespace std;
//Counting Words, Restricting Words to Letters and Letter-like Characters
int main()
{
typedef map<string, int> count_map;
typedef count_map::iterator count_iter;
typedef string::size_type str_size;
count_map counts;
string word;
// Read words from the standard input and count the number of times
// each word occurs.
string okay("ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789-_");
while (cin >> word)
{
// Make a copy of word, keeping only the characters that appear in okay.
string copy;
for (string::iterator w(word.begin()); w != word.end(); ++w)
if (okay.find(*w) != string::npos)
copy.push_back(*w);
// The "word" might be all punctuation, so the copy would be empty.
// Don't count empty strings.
if (not copy.empty())
++counts[copy];
}
// Determine the longest word.
str_size longest(0);
for (count_iter iter(counts.begin()); iter != counts.end(); ++iter)
if (iter->first.size() > longest)
longest = iter->first.size();
// For each word/count pair...
const int count_size(10); // Number of places for printing the count
for (count_iter iter(counts.begin()); iter != counts.end(); ++iter)
// Print the word, count, newline. Keep the columns neatly aligned.
cout << setw(longest) << left << iter->first <<
setw(count_size) << right << iter->second << '\n';
return 0;
}
2.9.2字符
字符I/O
get函数一次读取一个字符,且不会对空白字符做特殊处理。也可以使用标准输入操作符实现同样的效果,但是必须同时使用std::skipws操作子。恢复默认行为的时候使用std::skipws操作子。
程序示例:
/*************************************************************************
> File Name: char_io.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月24日 星期六 16时29分46秒
************************************************************************/
#include<ios>
#include<iostream>
#include<string>
using namespace std;
// 下面代码中的get函数和noskipws操作子具体作用请自行查阅资料吧。
// 其实就是为了处理空白字符。
int main()
{
// cin >> noskipws;
char ch;
while(cin.get(ch))
cout << ch;
return 0;
}
结果如下:

现在进行一个小练习,假设程序需要读入一系列的点。分别用x,y坐标定义,并以逗号隔开。在每个数字前面、后面以及逗号周围允许有空白。将点分别读入保存x值的向量和保存y的向量,如果点后面没有正确的逗号则结束输入循环。打印向量的内容,每行一个点。
示例代码:
/*************************************************************************
> File Name: char_exc.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月24日 星期六 16时41分56秒
************************************************************************/
#include <algorithm>
#include<iostream>
#include<string>
#include <limits>
#include <vector>
using namespace std;
int main()
{
typedef vector<int> intvec;
typedef intvec::iterator iterator;
intvec xs, ys; // store the xs and ys
{
// local block to keep I/O variables local
int x(0), y(0); // variables for I/O
char sep(' ');
// Loop while the input stream has an integer (x), a character (sep),
// and another integer (y); then test that the separator is a comma.
// 当读入的分隔符不是逗号的时候,结束输入,开始输出
while (cin >> x >> sep and sep == ',' and cin >> y)
{
xs.push_back(x);
ys.push_back(y);
}
}
cout << "The data you input are: " << endl;
for (iterator x(xs.begin()), y(ys.begin()); x != xs.end(); ++x, ++y)
std::cout << *x << ',' << *y << '\n';
return 0;
}
结果如下:

转义字符
再次仅仅贴一下几个常用的转义字符,具体转义字符用法什么的,请自行查阅资料吧,这个真真的是最基础的编程语言知识。

字符本地化
说到字符我们必然想到不同的国家的字符不同,英语有26个字母,但是德国法国等国家还有其他的一些字符,比如下面图的那些字符,我们要如何处理呢,好在C++提供了一个函数,可以告知我们那些字符是一个字母,:
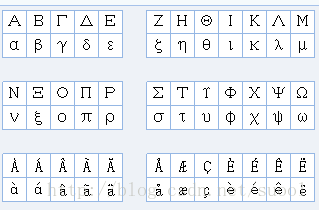
下面示例一个程序,使用isalnum来替代调用find函数:
/*************************************************************************
> File Name: char_isalnum.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月26日 星期日 10时13分27秒
************************************************************************/
/** Testing a Character by Calling isalnum */
#include <iostream>
#include <istream>
#include <locale>
#include <map>
#include <ostream>
#include <string>
int main()
{
using namespace std;
typedef map<string, int> count_map;
typedef count_map::iterator count_iter;
count_map counts;
string word;
// Read words from the standard input and count the number of times
// each word occurs.
while (cin >> word)
{
// Make a copy of word, keeping only alphabetic characters.
string copy;
for (string::iterator w(word.begin()); w != word.end(); ++w)
if (isalnum(*w, locale("")))
copy.push_back(*w);
// The "word" might be all punctuation, so the copy would be empty.
// Don't count empty strings.
if (not copy.empty())
++counts[copy];
}
// For each word/count pair, print the word & count on one line.
for (count_iter iter(counts.begin()); iter != counts.end(); ++iter)
cout << iter->first << '\t' << iter->second << '\n';
return 0;
}
注意上面的isalnum函数里面的第二个参数locale():isalnum使用该参数指定的区域设置确定测试字符使用的字符集。字符集根据字符的数值确定它的标识。当程序运行时候,用户可以改变字符集,因此程序必须跟踪用户实际的字符集,而不能依赖编译程序运行时的有效字符集。
在C++中,区域设置(locale)是关于文化、地域、和语言信息的集合。区域设置包含的信息如下:
- l 格式化数字、货币、日期、时间
- l 分类字符
- l 字符大小写转换
- l 文本排序
- l 消息目录(用于翻译程序所使用的字符串)
每个C++程序都以最小的、标准区域设置开始,成为经典(classic)区域设置或者C语言设置。函数std::locale::classic()返回经典区域设置。未命名的区域设置(std::locale(“”)注意分号)是C++从操作系统获得的用户首选项。使用空字符串参数的区域设置成为本地区域设置。
经典区域设置的优点是他的行为已知并且是确定的,如果你的程序必须以固定格式读取数据,那么你就不想受用户首选项的影响。相反,本地区域设置格式的优点是由于某种原因设置首选项,并且想让程序以首选项的格式输出。习惯指定日期格式的某地的用户不想被指定为另外地区的格式。
因此,经典格式经常用于读写数据文件,本地格式用于翻译用户输入,并且将输出直接呈献给用户。
每个I/O流都有自己的locale对象,要改变流的locale,可以调用他的imbue函数,将locale对象作为唯一的参数传入。
换言之,在C++启动的时候,他会用经典区域设置初始化每个流,如:
std::cin.imbue(std::locale::classic()); std::cout.imbue(std::locale::classic());
加入要改变输出流使其采用用户的本地区域设置,可以在程序的开始使用下面的语句:
std::cout.imbue(std::locale(""));
当使用本地区域设置时,推荐定义一个类型为std::locale的变量,用于存储本地区域设置。可以将该变量传给isalnum、imbue或者其他的函数。通过创建此变量并分发他的副本,程序只需要向操作系统查询一次用户首选项,而非每次都需要查询。
改写的程序如下:
/** Creating and sharing a single locale object. */
#include <iostream>
#include <istream>
#include <locale>
#include <map>
#include <ostream>
#include <string>
int main()
{
using namespace std;
typedef map<string, int> count_map;
typedef count_map::iterator count_iter;
locale native(""); // get the native locale
cin.imbue(native); // interpret the input and output according to
cout.imbue(native); // the native locale
count_map counts;
string word;
// Read words from the standard input and count the number of times
// each word occurs.
while (cin >> word)
{
// Make a copy of word, keeping only alphabetic characters.
string copy;
for (string::iterator w(word.begin()); w != word.end(); ++w)
if (isalnum(*w, native))
copy.push_back(*w);
// The "word" might be all punctuation, so the copy would be empty.
// Don't count empty strings.
if (not copy.empty())
++counts[copy];
}
// For each word/count pair, print the word & count on one line.
for (count_iter iter(counts.begin()); iter != counts.end(); ++iter)
cout << iter->first << '\t' << iter->second << '\n';
return 0;
}
大小写转换
简单的大小写转换
任务:改写单词计数程序,将大写转换为小写并计算所有单词出现的次数。
示例代码如下:
/** Folding Uppercase to Lowercase Prior to Counting Words */
#include <iostream>
#include <istream>
#include <locale>
#include <map>
#include <ostream>
#include <string>
int main()
{
using namespace std;
typedef map<string, int> count_map;
typedef count_map::iterator count_iter;
locale native(""); // get the native locale
cin.imbue(native); // interpret the input and output according to
cout.imbue(native); // the native locale
count_map counts;
string word;
// Read words from the standard input and count the number of times
// each word occurs.
while (cin >> word)
{
// Make a copy of word, keeping only alphabetic characters.
string copy;
for (string::iterator w(word.begin()); w != word.end(); ++w)
if (isalnum(*w, native))
copy.push_back(tolower(*w, native));
// The "word" might be all punctuation, so the copy would be empty.
// Don't count empty strings.
if (not copy.empty())
++counts[copy];
}
// For each word/count pair, print the word & count on one line.
for (count_iter iter(counts.begin()); iter != counts.end(); ++iter)
cout << iter->first << '\t' << iter->second << '\n';
return 0;
}
稍微复杂的大小写转换
一提到复杂就会想到涉及到了地域字符集的转换,这一部分先不说吧,确实有点复杂。
3.0函数专题
1、关于函数
关于什么是函数,函数的定义和声明什么的和C语言的差不多,再次不再细细的说了。

2、再练单词计数
使用函数改写的程序如下:
/*************************************************************************
> File Name: char_count_founction.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月25日 星期日 20时13分27秒
************************************************************************/
#include<iomanip>
#include<ios>
#include<iostream>
#include<locale>
#include<map>
#include<string>
using namespace std;
// Using Functions to Clarify the Word-Counting Program
typedef map<std::string, int> count_map; ///< Map words to counts
typedef count_map::iterator count_iter; ///< Iterate over a @c count_map
typedef string::size_type str_size; ///< String size type
/** Initialize the I/O streams by imbuing them with
* the given locale. Use this function to imbue the streams
* with the native locale. C++ initially imbues streams with
* the classic locale.
* @param locale the native locale
*/
void initialize_streams(std::locale locale)
{
cin.imbue(locale);
cout.imbue(locale);
}
/** Find the longest key in a map.
* @param map the map to search
* @returns the size of the longest key in @p map
*/
str_size get_longest_key(count_map map)
{
str_size result(0);
for (count_iter iter(map.begin()); iter != map.end(); ++iter)
if (iter->first.size() > result)
result = iter->first.size();
return result;
}
/** Print the word, count, newline. Keep the columns neatly aligned.
* Rather than the tedious operation of measuring the magnitude of all
* the counts and then determining the necessary number of columns, just
* use a sufficiently large value for the counts column.
* @param iter an iterator that points to the word/count pair
* @param longest the size of the longest key; pad all keys to this size
*/
void print_pair(count_iter iter, str_size longest)
{
const int count_size(10); // Number of places for printing the count
cout << setw(longest) << left << iter->first <<
setw(count_size) << right << iter->second << '\n';
}
/** Print the results in neat columns.
* @param counts the map of all the counts
*/
void print_counts(count_map counts)
{
str_size longest(get_longest_key(counts));
// For each word/count pair...
for (count_iter iter(counts.begin()); iter != counts.end(); ++iter)
print_pair(iter, longest);
}
/** Sanitize a string by keeping only alphabetic characters.
* @param str the original string
* @param loc the locale used to test the characters
* @return a santized copy of the string
*/
string sanitize(string str, locale loc)
{
string result;
for (string::iterator s(str.begin()); s != str.end(); ++s)
if (isalnum(*s, loc))
result.push_back(tolower(*s, loc));
return result;
}
/** Main program to count unique words in the standard input. */
int main()
{
locale native(""); // get the native locale
initialize_streams(native);
count_map counts;
string word;
// Read words from the standard input and count the number of times
// each word occurs.
while (std::cin >> word)
{
string copy(sanitize(word, native));
// The "word" might be all punctuation, so the copy would be empty.
// Don't count empty strings.
if (not copy.empty())
++counts[copy];
}
print_counts(counts);
return 0;
}
注释文档使用的格式是Doxygen.
3.函数参数
函数实参
有三种传递方式:按值传递,按引用传递、实参传递,
关于这三种传递的特性,不再赘述。
首先实参传递的示例:
/*************************************************************************
> File Name: list2001_argument_parameter.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月27日 星期二 10时25分48秒
************************************************************************/
#include<algorithm>
#include<iostream>
#include<iterator>
#include<string>
#include<vector>
using namespace std;
// function
void modify(int x)
{
x =10;
}
int triple(int x)
{
return 3*x;
}
void print_vector(vector<int> v)
{
cout << "{" ;
copy (v.begin(), v.end(), ostream_iterator<int>(cout," "));
cout << "}\n";
}
void add(vector<int> v, int a)
{
for(vector<int>::iterator iter(v.begin()); iter!=v.end(); ++iter)
{
*iter = *iter *a ;
}
}
int main()
{
int a(42);
modify(a);
cout << "a" << a << endl;
vector<int> data;
data.push_back(10);
data.push_back(20);
data.push_back(30);
data.push_back(40);
print_vector(data);
add(data, 30);
print_vector(data);
return 0;
}
结果如下:
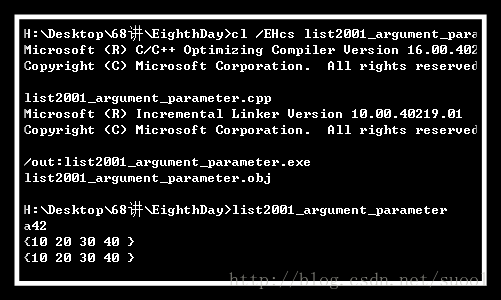
按引用传递
/*************************************************************************
> File Name: list2002_reference.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月27日 星期二 10时46分28秒
************************************************************************/
#include<algorithm>
#include<iostream>
#include<iterator>
#include<string>
#include<vector>
using namespace std;
// function
void modify(int& x)
{
x =10;
}
/**当triple的参数为引用时候,不可以直接调用triple(14).
*一言以蔽之,不能给数字赋值,只能给变量赋值.
*在C++术语中,粗略的讲,变量出现在赋值的左侧时称为左值.仅能出现在赋值的右侧的称为右值.
*整数字面量是一个很好的右值的例子.
*/
int triple(int x)
{
return 3*x;
}
/**按引用传递值,并且阻止函数改变参数.
*@const& v 声明参数v为不可变类型
*参数从右往左读,首先是参数v,然后他是一个引用,引用的是一个const对象
*/
void print_vector(vector<int> const& v)
{
cout << "{" ;
// copy (v.begin(), v.end(), ostream_iterator<int>(cout," "));
string separator("");
// 取代上面的ostream_iterator, 使用const_iterator,可以防止向量的内容被改变,
// 同时有可以实现迭代.
for(vector<int>const_iterator i(v.begin()); i!=v.end(); i++ )
{
cout << *i << separator ;
separator = ", ";
}
cout << "}\n";
}
void add(vector<int>& v, int a)
{
for(vector<int>::iterator iter(v.begin()); iter!=v.end(); ++iter)
{
*iter = *iter *a ;
}
}
int main()
{
int a(42);
modify(a);
cout << "a" << a << endl;
vector<int> data;
data.push_back(10);
data.push_back(20);
data.push_back(30);
data.push_back(40);
print_vector(data);
add(data, 30);
print_vector(data);
return 0;
}
结果如下:
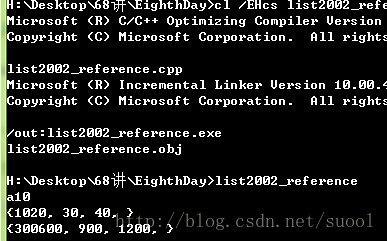
3.1.函数重载
在讲解重载之前,需要讲一下有关简单的C++其他标准算法。
现在我们使用算法重写单词计数程序,使用transform将字符转换为小写,使用remove_if算法除去字符串中的非字母字符,remove_if算法对于序列中的每个元素调用一个函数,如果函数返回trueremove_if从序列中删除该元素(其实比没有删除)。不过C++中迭代器的的工作原理的有一个副作用,就是这个函数并没有真正的删除该元素,而是重新组织了这个序列,返回了超出需要保存的元素的末端的下一个位置。
原理如下图:
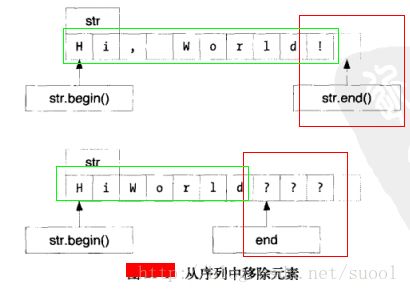
具体部分代码如下:
/** Sanitizing a String by Transforming It */
/** Test for non-letter.
* @param ch the character to test
* @return true if @p ch is not a character that makes up a word
*/
bool non_letter(char ch)
{
return not isalnum(ch, std::locale());
}
/** Convert to lowercase.
* Use a canonical form by converting to uppercase first,
* and then to lowercase.
* @param ch the character to test
* @return the character converted to lowercase
*/
char lowercase(char ch)
{
return std::tolower(ch, std::locale());
}
/** Sanitize a string by keeping only alphabetic characters.
* @param str the original string
* @return a santized copy of the string
*/
std::string sanitize(std::string str)
{
// Remove all non-letters from the string, and then erase them.
str.erase(std::remove_if(str.begin(), str.end(), non_letter),
str.end());
// Convert the remnants of the string to lowercase.
std::transform(str.begin(), str.end(), str.begin(), lowercase);
return str;
}
关于谓词:
首先上面的那个的bool non_letter(char ch)函数是一个谓词的例子,谓词是一个返回bool结果的函数。具体的请参阅相关资料,不再深入探讨。
其他的算法:
回文测试我们应该很熟悉,下面用C++实现。
代码如下:
/*************************************************************************
> File Name: word_pal.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年05月30日 星期五 20时26分41秒
************************************************************************/
#include<algorithm>
#include<iostream>
#include<iterator>
#include<locale>
#include<string>
using namespace std;
/** 测试非字母
* @param ch 带测试的字符
* @return 如果@p ch 不是字母返回true
*/
bool non_letter(char ch)
{
return not isalpha(ch, locale());
}
/** 转换为小写
* 使用规范形式,先转换为大写,后转换为小写.
* @param ch 待测试的字符
* @return 转换后的字符
*/
char lowercase(char ch)
{
return tolower(ch, locale());
}
/** 比较两个字符,不考虑大小写 */
bool same_char(char a, char b)
{
return lowercase(a) == lowercase(b);
}
/** 确定@p str 是否包含回文
* 只测试字母,不包括空格和标点
* 空字符串不是回文
* @param str 带测试的回文
* @return 当@p str 顺读和倒读都一样的时候返回true
*/
bool is_palindrome(string str)
{
string::iterator end(remove_if(str.begin(), str.end(), non_letter));
string rev(str.begin(), end);
reverse(rev.begin(), rev.end());
return not rev.empty() and equal(str.begin(), end, rev.begin(), same_char);
}
int main()
{
locale::global(locale(""));
cin.imbue(locale());
cout.imbue(locale());
string line ;
while(getline(cin, line))
{
if(is_palindrome(line))
{
cout << "这是一个回文: " << line << endl;
}
}
return 0;
}
重载
关于函数的重载和其他的高级语言一样样的。所以,我们会在以后的程序中再讲。。。。哈哈哈哈。
3.2回到数字
3.2.1长整型&短整型
使用number_limits获取整数的位数。
代码如下:
/*************************************************************************
> File Name: list2301_int.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年06月03日 星期二 15时38分25秒
************************************************************************/
/** Discovering the Number of Bits in an Integer */
#include<iostream>
#include <limits>
#include<string>
using namespace std;
// numeric_limits获得整数的位数,并有一个返回值is_signed,即当数字有符号时返回true
int main()
{
cout << "bits per int = ";
if (numeric_limits<int>::is_signed) // 如果有符号,加一,加上符号位
cout << numeric_limits<int>::digits + 1 << '\n';
else // 否则直接输出
cout << numeric_limits<int>::digits << '\n';
cout << "bits per bool = ";
if (numeric_limits<bool>::is_signed)
cout << numeric_limits<bool>::digits + 1 << '\n';
else
cout << numeric_limits<bool>::digits << '\n';
return 0;
}
下面的代码可以显示短整型和长整型的所占的位数:
/*************************************************************************
> File Name: list2302_long.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年06月03日 星期二 15时44分42秒
************************************************************************/
/** Revealing the Number of Bits in Short and Long Integers */
#include<iostream>
#include <limits>
#include<string>
using namespace std;
int main()
{
cout << "bits per int = ";
if (numeric_limits<int>::is_signed)
cout << numeric_limits<int>::digits + 1 << '\n';
else
cout << numeric_limits<int>::digits << '\n';
cout << "bits per bool = ";
if (numeric_limits<bool>::is_signed)
cout << numeric_limits<bool>::digits + 1 << '\n';
else
cout << numeric_limits<bool>::digits << '\n';
cout << "bits per short int = ";
if (numeric_limits<short>::is_signed)
cout << numeric_limits<short>::digits + 1 << '\n';
else
cout << numeric_limits<short>::digits << '\n';
cout << "bits per long int = ";
if (numeric_limits<long>::is_signed)
cout << numeric_limits<long>::digits + 1 << '\n';
else
cout << numeric_limits<long>::digits << '\n';
cout << "bits per long long int = ";
if (numeric_limits<long long>::is_signed)
cout << numeric_limits<long long>::digits + 1 << '\n';
else
cout << numeric_limits<long long>::digits << '\n';
return 0;
}
下面我们就可以演示一下重载了,顺便说明一下类型转换。
代码如下:
/*************************************************************************
> File Name: list2303_print_overide.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年06月03日 星期二 16时08分45秒
************************************************************************/
/** Using Type Casts */
// 重载print函数,输出不同的数值类型
#include<iostream>
#include <locale>
#include<string>
using namespace std;
typedef signed char byte;
void print(byte b)
{
// 操作符<<将signed char 当作变异的char,并尝试打印一个字符
// 为了将该值打印为一个整数,必须将其转换为整数类型
// static_cast() 表达式称为类型转换
cout << "byte=" << static_cast<int>(b) << '\n';
}
void print(short s)
{
cout << "short=" << s << '\n';
}
void print(int i)
{
cout << "int=" << i << '\n';
}
void print(long l)
{
cout << "long=" << l << '\n';
}
int main()
{
cout.imbue(locale(""));
print(0);
print(0L);
print(static_cast<short>(0));
print(static_cast<byte>(0));
print(static_cast<byte>(255)); // -1
print(static_cast<short>(65535)); // -1
print(32768);
print(32768L);
print(-32768);
print(2147483647);
print(-2147483647);
// The following lines might work on your system.
// If you are feeling adventuresome, uncomment the next 3 lines:
print(2147483648); // long类型
print(9223372036854775807);
print(-9223372036854775807);
return 0;
}
下面一个程序再次演示重载函数,同时演示类型转换和类型提升的区别。
代码如下:
/*************************************************************************
> File Name: list2303_typePromotion.cpp
> Author: suool
> Mail: [email protected]
> Created Time: 2014年06月03日 星期二 16时17分39秒
************************************************************************/
/** Overloading Prefers Type Promotion over Type Conversion */
/** 类型转换
* 类型转换分为两步.
* 当使用signed char和short类型时,编译器总是将他们转换为int,然后执行运算.这被称为类型提升.
* 但是,对于一组重载函数且编译器需要知道调用哪个时,编译器首先做的事情是找一个精确的匹配,
* 如果找不到,就会考虑类型提升之后的匹配,仅当这种匹配也失败的时候,才会搜索类型转换后能够匹配上的.
* 因此,编译器优先考虑基于类型提升的匹配.
*/
// 具体如下面的程序.
#include<iostream>
#include<string>
using namespace std;
// print is overloaded for signed char, short, int and long
void print(signed char b)
{
cout << "print(signed char = " << static_cast<int>(b) << ")\n";
}
void print(short s)
{
cout << "print(short = " << s << ")\n";
}
void print(int i)
{
cout << "print(int = " << i << ")\n";
}
void print(long l)
{
cout << "print(long = " << l << ")\n";
}
// guess is overloaded for bool, int, and long
void guess(bool b)
{
cout << "guess(bool = " << b << ")\n";
}
void guess(int i)
{
cout << "guess(int = " << i << ")\n";
}
void guess(long l)
{
cout << "guess(long = " << l << ")\n";
}
// error is overloaded for bool and long
void error(bool b)
{
cout << "error(bool = " << b << ")\n";
}
void error(long l)
{
cout << "error(long = " << l << ")\n";
}
int main()
{
signed char byte(10);
short shrt(20);
int i(30);
long lng(40);
// 精确匹配各个类型
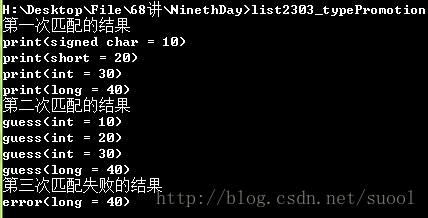
cout << "第一次匹配的结果" << endl;
print(byte);
print(shrt);
print(i);
print(lng);
// 前三个都自动提升为int类型
// 因为guess函数没有相应的类型参数,所以无法精确匹配,需要提升类型
cout << "第二次匹配的结果" << endl;
guess(byte);
guess(shrt);
guess(i);
guess(lng);
// 由于error参数没有相应的类型,所以需要类型提升,先将signed char和short
// 提升为int类型,但是guess没有int类型的参数,需要进行类型转换,此时guess函数中
// 参数有long和bool两种,而类型转换,编译器认为所有转换的优先级相同,所以,此时编译器不知道
// 该转换为long还是bool,即是不知道该调用那一个guess函数,因此会出现错误.
// 要避免错误,只需要添加一个guess函数,参数为int即可.
cout << "第三次匹配失败的结果" << endl;
// error(byte); // expected error
// error(shrt); // expected error
// error(i); // expected error
error(lng);
return 0;
}
结果如下:
3.2.1浮点数&定点数
首先用下面的代码演示浮点数的一些特性:
/************************************************************************* > File Name: list2401_float.cpp > Author: suool > Mail: [email protected] > Created Time: 2014年06月03日 星期二 17时14分59秒 ************************************************************************/ /** Floating-Point Numbers Do Not Always Behave as You Expect */ #include<iostream> #include<string> #include <cassert> using namespace std; // 浮点数的比较!显示出浮点数在精度上的注意事项. int main() { float a(0.03f); float b(10.0f); float c(0.3f); cout << "a*b = " << a*b << endl; cout << "c = " << c << endl; assert(1 == 1); return 0; }
结果如下:

下面演示三种浮点数格式的输出:
/************************************************************************* > File Name: list2401_float_print.cpp > Author: suool > Mail: [email protected] > Created Time: 2014年06月03日 星期二 17时29分32秒 ************************************************************************/ /** Demonstrating Floating-Point Output */ // 浮点数输出示例,三种格式的浮点数输出. #include <ios> #include<iostream> #include<string> using namespace std; /// Print a floating-point number in three different formats. /// @param precision the precision to use when printing @p value /// @param value the floating-point number to print void print(int precision, float value) { cout.precision(precision); cout << "科学计数法格式输出" << endl; cout << scientific << value << '\n'; cout << "定点数格式输出" << endl; cout << fixed << value << '\n'; // Set the format to general. cout.unsetf(ios_base::floatfield); cout << "一般格式输出"<< endl; cout << value << '\n'; } /// Main program. int main() { print(6, 123456.789f); print(4, 1.23456789f); print(2, 123456789.f); print(5, -1234.5678e9f); return 0; } /* 三种格式的浮点数输出说明 首先是precision(int)的说明: 关于setprecision(int),MSDN上的解释为: 即当输出的数据类型为浮点型时,setprecision(int)表示设置输出数的有效位数, 当输出的是定点数或用科学计数法表示的数时,setprecison(int)表示设置输出数小数点后的位数。 故通常控制浮点数输出时小数点后的位数的做法为:先将要输出的数设置为定点数,然后使用setprecision(int). 然后关于科学格式: 指数被打印为e或者E,随后是基数为10的指数.且指数有符号,即使指数为0,也至少有两位数字 关于定点格式: 不打印指数,小数点前有多少位打印多少位,小数点总是被打印,精度取决与小数点后的数字的位数. 关于默认格式: 如果指数小于或者等于-4,或者说大于精度,数字会以科学格式打印. 否则,以无指数格式打印,但是不像传统的定点输出,小数点后的0会被移除. 需要时,值会以四舍五入的来适应分配的精度. */
结果如下:

Over, 第一部分C++基础!
第三部分预计会推迟几天,,要复习,快考试了。。