ZooKeeper 搭建
- 一 概述
- 二 单机模式 Standalone Mode
- 1 下载 ZooKeeper
- 2 解压 ZooKeeper 346
- 3 配置环境变量并使之生效
- 4 配置 zoocfg
- 5 启动本地 ZooKeeper
- 三 复制模式 Replicated Mode
- 1 规划
- 2 主机名称到IP地址映射配置
- 3 下载解压缩 ZooKeeper 并配置环境变量
- 4 修改ZooKeeper配置文件
- 5 重置 zookeeperout 的输出位置
- 6 远程复制分发安装文件
- 7 设置myid
- 8 启动ZooKeeper集群
- 9 安装验证
- 10 注意事项
- 四 标准的 Java 属性文件
一. 概述
ZooKeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以Standalone模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。
更多关于 ZooKeeper 的原理介绍请参考
- 《ZooKeeper 工作原理》:http://blog.csdn.net/u011414200/article/details/50184359
- 《 Zookeeper (Hadoop 权威指南)》:http://blog.csdn.net/u011414200/article/details/50249731
本次安装笔者搭建的是生产环境中的 ZooKeeper (即 “复制模式”),且安装的是 2014年3月的 ZooKeeper 3.4.6 版本。
二. 单机模式 (Standalone Mode)
在 hadoop5 用户下搭建
2.1 下载 ZooKeeper
从 Apache 的 ZooKeeper 发布页面 (http://zookeeper.apache.org/releases.html#download) 下载 ZooKeeper 的一个稳定版本
从笔者博客资源直接下载 ZooKeeper 3.4.6
注:将下载的 tar.gz 安装包直接放置在合适位置即可,笔者暂存放在 ~/softwares/tar_packages 目录下
2.2 解压 ZooKeeper 3.4.6
tar -zxvf ~/softwares/tar_packages/zookeeper-3.4.6.tar.gz -C ~/softwares/
2.3 配置环境变量,并使之生效
ZooKeeper 提供了几个能够运行服务并与之交互的二进制可执行文件,可以很方便地将包含这些二进制文件的目录加入命令行路径:
export ZOOKEEPER_HOME=/home/hadoop5/softwares/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin然后再使环境生效:
source ~/.bash_profile2.4 配置 zoo.cfg
先将 zoo_sample.cfg 拷贝为 zoo.cfg
cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg
vim $ZOOKEEPER_HOME/conf/zoo.cfg修改如下:
tickTime=2000
dataDir=/home/hadoop5/softwares/zookeeper-3.4.6/data
clientPort=2181这三个属性是以独立模式运行 ZooKeeper 所需的最低要求。其中 dataDir 可自定义设置,详情请参考附录中的 《标准的 Java 属性文件》 。
2.5 启动本地 ZooKeeper
- 启动服务
zkServer.sh start![]()
- 查看进程 —— jps
![]()
QuorumPeerMain 是 ZooKeeper 的主进程
- 查看状态
zkServer.sh status
- 询问状态
使用 nc(telnet 也可以)发送 ruok 命令 (Are you OK?) 到监听端口,检查 Zookeeper 是否正在运行
echo ruok | nc localhost 2181![]()
imok 是 ZooKeeper 在说 “I'm OK”。还有其他一些用于管理 ZooKeeper 的命令,都采用类似的四字母组合,如附录中的 管理 《ZooKeeper 的四字母命令》 所示。
- 客户端连接 ZooKeeper 服务器
bin/zkCli.sh -server slave52:2181 slave52是你配置 ZooKeeper 机子的主机名,如果在本地执行,则执行如下命令:
bin/zkCli.sh 三. 复制模式 (Replicated Mode)
3.1 规划
| 主机名 | 用户名 | IP 地址 | myid | 搭建路径 |
|---|---|---|---|---|
| slave51 | hadoop5 | 10.6.3.48 | 1 | /usr/local/cluster/zookeeper |
| slave52 | hadoop5 | 10.6.3.32 | 2 | /usr/local/cluster/zookeeper |
| slave53 | hadoop5 | 10.6.3.36 | 3 | /usr/local/cluster/zookeeper |
由于机子有限,笔者当时在配置时暂时采用使用了这些机子,IP 地址太混乱了,不过影响不大,各位读者将就着看吧…
3.2 主机名称到IP地址映射配置
ZooKeeper 集群中具有两个关键的角色:Leader 和 Follower。集群中所有的结点作为一个整体对分布式应用提供服务,集群中每个结点之间都互相连接,所以,在配置的ZooKeeper集群的时候,每一个结点的host到IP地址的映射都要配置上集群中其它结点的映射信息。
10.6.3.48 slave51
10.6.3.32 slave52
10.6.3.36 slave533.3 下载、解压缩 ZooKeeper 并配置环境变量
笔者考虑到已经使用了 CDH5 版本的 Hadoop ,所以为了避免将来可能出现的兼容性问题,于是就上了 CDH 官网上直接下载配套最新的 ZooKeeper 了,如下图:
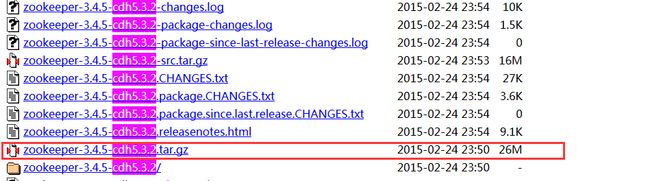
zookeeper-3.4.5-cdh5.3.2.tar.gz 下载地址: http://archive.cloudera.com/cdh5/cdh/5/
- 解压缩
笔者将下载下来的 tar 安装包先暂放在当前 hadoop5 用户下的 softwares/tar_manager:wq 路径下,然后解压
sudo mkdir -p /usr/local/cluster/zookeeper
sudo tar -zxvf zookeeper-3.4.5-cdh5.3.2.tar.gz -C /usr/local/cluster/zookeeper --strip-components 1
sudo chown -R hadoop5:hadoop5 /usr/local/cluster/- 设置环境变量
vim ~/.bash_profile添加如下:
export ZOOKEEPER_HOME=/usr/local/cluster/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin- 然后再使环境生效
source ~/.bash_profile3.4 修改ZooKeeper配置文件
1. 在其中一台机器(slave51)上,修改配置文件conf/zoo.cfg,内容如下所示:
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg编辑后如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/cluster/zookeeper/data
dataLogDir=/usr/local/cluster/zookeeper/logs
clientPort=2181
#cluster
server.1=slave51:2888:3888
server.2=slave52:2888:3888
server.3=slave53:2888:3888
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1- 在复制模式 (Replicated Mode)下,initLimit 和 syncLimit 是需要额外强制设置,两个都是 tickTime 的倍数进行度量
- 默认情况下,ZooKeeper 的事务日志和数据快照 (snapshot) 都保存在 dataDir属性所指定的目录中。但是笔者已经通过 dataLogDir 属性设置事务日志存放的目录位置,这是因为通过指定一个专用的设备,一个 ZooKeeper 服务器可以以最大速率将日志记录写到磁盘,并且写日志是顺序写,并没有寻址操作。且事务日志的命名类似于
log.100000001、log.200000001。 - ZooKeeper 服务器的集合体中,每个服务器都有一个数值型的 ID,服务器 ID 在集合体中是唯一的,并且取值范围在 1~255 之间。
- 需要将集合体中其他服务器的 ID 和网络位置告诉所有的服务器,即添加
server.n=hostname:port1:port2
server.服务器ID=服务器(IP/主机名):跟随者连接领导者的端口:被用于领导者选举的端口- 2181 端口用于客户端连接;对于领导者来说,2888端口被用于跟随者连接;3888端口被用于领导者选举阶段的其他服务器连接
- 从3.4.0开始,zookeeper 提供了自动清理 snapshot 和事务日志的功能,通过配置
- autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能
- autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个
3.5 重置 zookeeper.out 的输出位置
zookeeper的log日志输出是直接输出到当前 zookeeper.out 的文件,这是一个控制台的重定向文件。笔者强调的是 “当前”指的是以你执行 zkServer.sh start 的所在路径为准。每次重启 ZooKeeper 服务时,会覆盖当前 zookeeper.out 的文件(假设存在的话)。如果你对zookeeper.out 的输出位置无所谓,那么请忽略 3.4 步骤。
直接修改 $ZOOKEEPER_HOME/bin/zkServer.sh 文件
在 zkServer.sh 的代码中可以得出,这个zookeeper.out实际上是nohup的输出。而nohup的输出实际上是stdout,stderr的输出,所以还是zookeepe本身的日志配置的问题。
研究了下bin/zkServer.sh和conf/log4j.properties,发现zookeeper其实是有日志相关的输出的配置,只要定义相关的变量就可以了。主要是 ZOO_LOG_DIR 和 ZOO_LOG4J_PROP 这两个环境变量。
修改下bin/zkServer.sh就可以了:
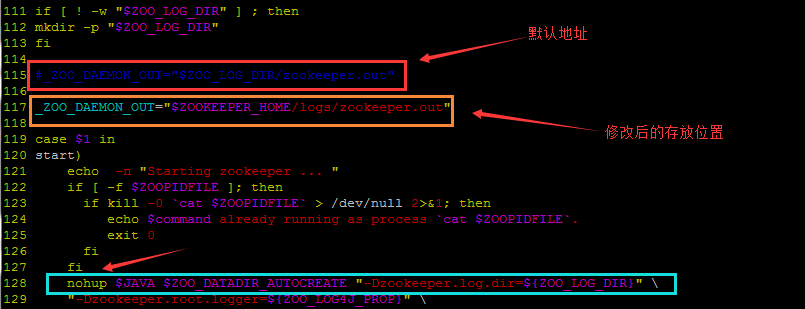
将 _ZOO_DAEMON_OUT 修改为你想要存放的路径即可,该 CDH 版本的 zookeeper 与其他版本只需修改 $ZOOKEEPER_HOME/bin/zkEnv.sh 文件有着区别。具体可看 《配置zookeeperout的位置及log4j滚动日志输出》
后记:因为该 CDH 版本下的 ZooKeeper 在执行 zkServer.sh 时并不会事先加载 “zkEnv.sh”,所以所有关于变量 ${ZOO_LOG_DIR} 和 ${ZOOKEEPER_HOME} 是不会加载的,即为空。所以事先一定要事先创建好 变量 ${ZOO_LOG_DIR} 所设置的目录。同时,为了能在其他机子上用脚本一键开启所有的 zk 服务,就需要将上述的 ${_ZOO_DAEMON_OUT} 设置为绝对路径,如下所示(这点很重要!!!):
_ZOO_DAEMON_OUT="/usr/local/cluster/zookeeper/logs/zookeeper.out"在其他机上批量启动 zk 服务的命令可以参考如下:
ssh -t slave51 "/usr/local/cluster/zookeeper/bin/zkServer.sh start"3.6 远程复制分发安装文件
在分发之前,请先登录到剩下 slave52 和 slave53 机子上,执行
sudo mkdir -p /usr/local/cluster
sudo chown -R hadoop5:hadoop5 /usr/local/cluster因为已经在一台机器 slave51上配置完成 ZooKeeper,现在可以在 slave51 的机子上将该配置好的整个 zookeeper 文件拷贝到集群中剩下结点对应的目录下:
cd /usr/local/cluster
scp -r zookeeper/ hadoop5@slave52:/usr/local/cluster
scp -r zookeeper/ hadoop5@slave53:/usr/local/cluster3.7 设置myid
在我们配置的 dataDir 指定的目录下面,创建一个 myid 纯文本文件,里面设定服务器的 ID,用来标识当前主机,conf/zoo.cfg文件中配置的 server.X 中 X 为什么数字,则 myid 文件中就输入这个数字。
- 在主机 slave51 上完成
cd /usr/local/cluster/zookeeper
mkdir -p data logs
echo "1" > data/myid- 在主机 slave52 上完成
cd /usr/local/cluster/zookeeper
mkdir -p data logs
echo "2" > data/myid - 在主机 slave53 上完成
cd /usr/local/cluster/zookeeper
mkdir -p data logs
echo "3" > data/myid 以上之所以创建 data、logs目录,是因为笔者在 zoo.cfg 中已经设置了
dataDir=/usr/local/cluster/zookeeper/data
dataLogDir=/usr/local/cluster/zookeeper/logs如果设置了变量 dataLogDir ,那么所设置的路径就需要事先创建,否则会出现如下错误
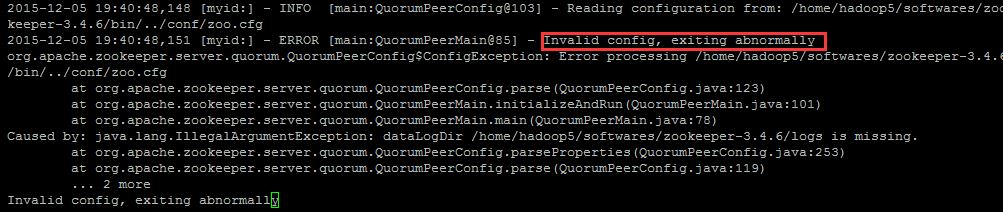
除非你在 bin/zkEnv.sh 设置了 ZOO_LOG_DIR 且和 dataLogDir 路径设置的一样,就可以不用事先创建该目录了,因为 ZooKeeper 服务启动时会创建 ZOO_LOG_DIR 目录。
当一个 ZooKeeper 服务器启动时,它会读取 myid 文件用于确定自己的服务器 ID,然后通过读取配置文件来确定应当在哪个端口进行监听,同时确定集合体中其他服务器的网络地址。
3.8 启动ZooKeeper集群
在启动之前补充一句:记得在各个 zookeeper Server 机子上(这里的 slave51、slvave52、slave53)的 ~/.bash_profile 配置文件添加 zookeeper 的环境变量,并 source ~/.bash_profile ,添加内容如下:
export ZOOKEEPER_HOME=/usr/local/cluster/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin- 分别登陆到 ZooKeeper 集群的每个节点上,执行启动 ZooKeeper 服务的脚本,就是下面这一命令:
$ZOOKEEPER_HOME/bin/zkServer.sh start Note: 启动的时候需要到每一台 ZooKeeper 机器上启动服务,同理,关闭服务也要一台台来…
启动后,可以看到
| 主机名 | Server关系 | 目录 data | 目录 log |
|---|---|---|---|
| slave51 | Follower | myid version-2 / acceptedEpoch、currentEpoch、 snapshot.100000000 zookeeper_server.pid |
version-2 zookeeper.out |
| slave52 | Leader | myid version-2 / acceptedEpoch 、 currentEpoch 、snapshot.0 zookeeper_server.pid |
version-2 zookeeper.out |
| slave53 | Follower | myid version-2 / acceptedEpoch 、currentEpoch、snapshot.0 zookeeper_server.pid |
version-2 zookeeper.out |
启动时输出日志可忽略的报错信息,请查看 《启动的日志》
启动过程中选举 leader 的过程详解请看 《选取 leader 的过程详解依据 log4j 文件查看》
3.9 安装验证
- 每台主机上可以查看到的进程
![]()
QuorumPeerMain 是 ZooKeeper 的主进程
- 在三台机子上查看各自的状态
$ZOOKEEPER_HOME/bin/zkServer.sh status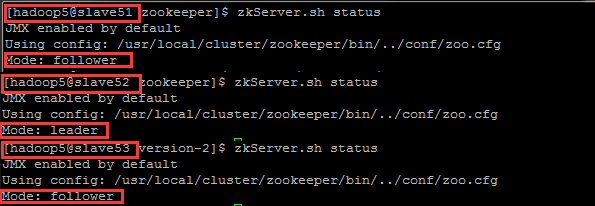
可以看出 slave52 是集群的 Leader,其余的两个结点是Follower。至于选取的过程有兴趣可以看《选取 leader 的过程详解(依据 log4j 文件查看)》
- 可以通过客户端脚本,连接到ZooKeeper集群上
对于客户端来说,ZooKeeper是一个整体(ensemble),连接到ZooKeeper集群实际上感觉在独享整个集群的服务,所以,你可以在任何一个结点上建立到服务集群的连接,例如:
先到 slave2 (leader) 上查看当前的连接数:
echo stat | nc slave52 2181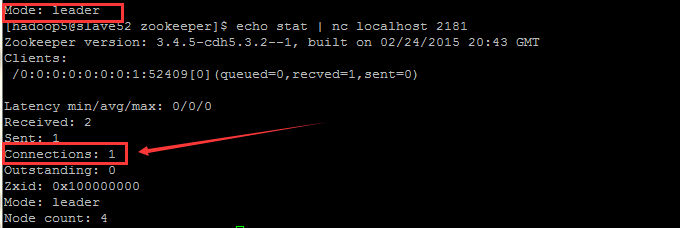
然后在任意一台机器上执行,充当 client (笔者就在 slave53 的主机上执行)
$ZOOKEEPER_HOME/bin/zkClit.sh -server slave52:2181其中 slave53 是 ZooKeeper 其中的一台 Server,2181 是该 Server 提供给客户端连接的端口。
键入 ls / 可以看到当前根路径为 /zookeeper ,更多信息请查看 《客户端连接 ZooKeeper 服务器》
这时再到slave2 (leader) 上查看当前的连接数:
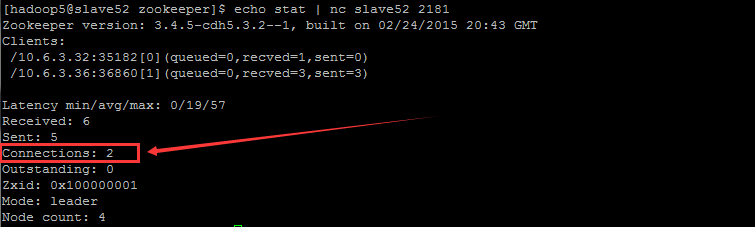
最后,在 Slave53 上直接 close 或者 quit 就能退出了,此时 Connections 就从 2 恢复为 1 了。这时看到 slave51、slave52、slave53 的 $ZOOKEEPER_HOME/logs 下都会生成 log.100000001 日志文件。
3.10 注意事项
Note:一定要谨记将logs文件夹重建,因为里面的version-2里面会保存原有记录,此记录有可能与新集群有冲突。还有dataDir也要重建,原有的节点快照都会导致新集群出现问题。
Note:zookeeper重启会自动清除zookeeper.out日志,所以如果出错要注意先备份这个文件
Note:连接到这个 ZooKeeper 集合体的客户端在 ZooKeeper 对象构造函数中应当使用 slave51:2181、slave52:2181、slave53:2181 作为主机字符串。这在搭建 Hadoop HA 模式中将会用到。
Note:你运行一个zookeeper也是可以的,但是在生产环境中,你最好部署3,5,7个节点。部署的越多,可靠性就越高,当然最好是部署奇数个,偶数个不是不可以的,但是zookeeper集群是以宕机个数过半才会让整个集群宕机的,所以奇数个集群更佳。
Note:你需要给每个zookeeper 1G左右的内存,如果可能的话,最好有独立的磁盘。 (独立磁盘可以确保zookeeper是高性能的。).如果你的集群负载很重,不要把Zookeeper和RegionServer运行在同一台机器上面
四. 标准的 Java 属性文件
| 属性 | 意义 |
|---|---|
| tickTime | 时间单元,心跳和最低会话超时时间为tickTime的两倍 |
| dataDir | 数据存放位置,存放内存快照和事务更新日志 |
| clientPort | 指定了 ZooKeeper 用于监听客户端连接的端口(通常使用 2181 端口) |
| initLimit | 设定了所有 Follower 与 Leader 进行连接并同步的时间范围。如果在设定的时间段内,半数以上的跟随者未能完成同步,Leader 便会宣布放弃领导地位,然后进行另外一次 Leader 选举。如果这种情况经常发生可以通过日志中的记录发现这种情况),则表明设定的值太小。Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 ZooKeeper 服务器还没有收到 Follower 的返回信息,那么表明这个Follower 连接失败。总的时间长度就是 5*2000=10 秒 |
| syncLimit | 这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个,如果在设定的时间段内,一个跟随者未能完成同步,会自己重启。所有关联到跟随者的客户端将连接到另一个跟随者 |
| server.id=host:port:port server.A=B:C:D |
集群结点列表: A :是一个数字,表示这个是第几号服务器; B :是这个服务器的 ip 地址或者主机名; C :表示的是这个服务器与集群中的 Leader 服务器交换信息的端口; D :表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 ZooKeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。 |