我所认识的EXT2(二)
Ø EXT2中块组的划分
块组是非常重要的概念,首先请朋友们弄清楚分区和块组是完全不同的概念,分区至多只能有4个(3个主分区和1个扩展分区,如果4个分区不够用,只能用逻辑分区),分区的作用就是对磁盘进行分割,分区之后才能用文件系统对分区进行格式化;块组是基于文件系统的概念,EXT2在分区的基础上格式化后会形成至少1个以上的块组。
那么在EXT2中是用什么规则来划分块组的呢?由于EXT2规定,块位图能且只能占一个逻辑块,因此块位图事实上成为了块组划分的一个标准(或者说是限制)。举个例子:
用EXT2格式化一个1G大小的分区,逻辑块的大小为4096字节,求此分区被格式化后有多少个块组?
一个逻辑块的位图大小为:4096 * 8 = 32768,也就说一个块组最多只能有32768个逻辑块(因为块位图只能管32768个逻辑块)
32768个逻辑块的大小为:32768 * 4096 = 134217728 Bytes = 131072K Bytes = 128M Bytes
1024M Bytes / 128M Bytes = 8
因此被格式化后有8个块组,每个块组的大小为128M Bytes,编号从0开始。当然利用格式化工具,如mke2fs是可以指定块组的个数的。
Ø Inode是什么
终于要讨论Inode了,在之前都是一笔带过,实际上正是Inode的存在才使得EXT2能实现高速存储和读取。
首先Inode是在EXT2中指向数据块的“指针”,然后Inode保存着文件的属性;在EXT2中,文件的数据和属性是分开保存的,文件的属性保存在Inode表中,文件的数据保存在数据块中。以下是Inode的结构体定义:
| struct ext2_inode { __le16 i_mode; /* File mode 文件模式:普通文件、目录、字符设备等等*/ __le16 i_uid; /* Low 16 bits of Owner Uid 拥有者ID*/ __le32 i_size; /* Size in bytes 文件大小*/ __le32 i_atime; /* Access time 最近访问时间*/ __le32 i_ctime; /* Creation time 创建时间*/ __le32 i_mtime; /* Modification time 修改时间*/ __le32 i_dtime; /* Deletion Time 删除时间*/ __le16 i_gid; /* Low 16 bits of Group Id 用户组ID*/ __le16 i_links_count; /* Links count 连接数*/ __le32 i_blocks; /* Blocks count 物理块的数量*/ __le32 i_flags; /* File flags */ union { struct { __le32 l_i_reserved1; } linux1; struct { __le32 h_i_translator; } hurd1; struct { __le32 m_i_reserved1; } masix1; } osd1; /* OS dependent 1 所属操作系统*/ __le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks 至多可以有15个“指针” 指向真正存放文件数据的地方*/ __le32 i_generation; /* File version (for NFS) 文件版本 */ __le32 i_file_acl; /* File ACL 文件访问权限*/ __le32 i_dir_acl; /* Directory ACL 目录访问权限*/ __le32 i_faddr; /* Fragment address 片地址*/ union { struct { __u8 l_i_frag; /* Fragment number */ __u8 l_i_fsize; /* Fragment size */ __u16 i_pad1; __le16 l_i_uid_high; /* these 2 fields */ __le16 l_i_gid_high; /* were reserved2[0] */ __u32 l_i_reserved2; } linux2; struct { __u8 h_i_frag; /* Fragment number */ __u8 h_i_fsize; /* Fragment size */ __le16 h_i_mode_high; __le16 h_i_uid_high; __le16 h_i_gid_high; __le32 h_i_author; } hurd2; struct { __u8 m_i_frag; /* Fragment number */ __u8 m_i_fsize; /* Fragment size */ __u16 m_pad1; __u32 m_i_reserved2[2]; } masix2; } osd2; /* OS dependent 2 */ }; |
用sizeof(ext2_inode)查看这里的结构体ext2_inode大小为120,可是N多文章里面均提到Inode size的默认值为128,究竟谁才是正确的呢?打开ext2_fs.h这个文件可以发现,这里有这么句话:
| #define EXT2_GOOD_OLD_INODE_SIZE 128 |
首先,先明显一个概念,Inode size不一定为128,因为可以通过格式化工具mke2fs显示指定Inode size(具体请查看man 8 mke2fs)。;然后查看格式化工具mke2fs的源代码(下载地址:http://e2fsprogs.sourceforge.net/)打开e2fsprogs-1.39/misc/mke2fs.c,可以注意到
| while ((c = getopt (argc, argv, "b:cf:g:i:jl:m:no:qr:s:tvE:FI:J:L:M:N:O:R:ST:V")) != EOF) { switch (c) { ... case 'I': inode_size = strtoul(optarg, &tmp, 0); /**-I 可以显示的改变Inode的大小*/ ... if (inode_size) { /**如果用户定义的Inode size小于128*/ if (inode_size < EXT2_GOOD_OLD_INODE_SIZE || /** 或者如果用户定义的Inode size大于逻辑块的大小 # define EXT2_BLOCK_SIZE(s) ((s)->s_blocksize)*/ inode_size > EXT2_BLOCK_SIZE(&fs_param) || /** 或者如果用户定义的Inode size不是128的倍数*/ inode_size & (inode_size - 1)) { com_err(program_name, 0, _(”invalid inode size %d (min %d/max %d)”), inode_size, EXT2_GOOD_OLD_INODE_SIZE, blocksize); exit(1); } if (inode_size != EXT2_GOOD_OLD_INODE_SIZE) fprintf(stderr, _(”Warning: %d-byte inodes not usable ” “on most systemsn”), inode_size); fs_param.s_inode_size = inode_size; } |
OK,通过源码我们可以清楚地发现就算用户可以通过-I选项自定义Inode size,但是必须遵循以下三个条件:
1.必须大于等于128;
2.必须小于逻辑块的大小;
3.必须是128的倍数;
笔者认为真正的默认值是在mke2fs.conf中定义的:
| [defaults] base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr blocksize = 4096 inode_size = 256 /**通过查看源代码,发现256才是真正的默认值*/ inode_ratio = 16384 |
明确了一个Inode自身所占空间以后,我们来看这么个问题:在一个块组中有Inode的数量是如何规划的呢?EXT2的默认规则是每16K空间分配一个Inode(关于此参数请查看上表,其实在程序中还有一个参数就是8K不过是要当读取mke2fs.conf文件失败时才启用。这里先以inode_ratio = 16384为默认值)
让我们用这种规则计算下Inode的数量(1G磁盘空间,逻辑块为4096Bytes):
Inode的个数:128M Bytes / 16K Bytes = 8192
Inode所占空间:8192 * 256bytes = 2048K Bytes
当然如果我们打算只在这1G的空间里放一些电影或者照片等比较大的文件,那么每16K空间分配一个Inode的这种策略也是浪费空间的,因此格式化工具mke2fs允许用户通过-i(小写)自定义每N空间分配一个Inode,
| ….. case 'i': inode_ratio = strtoul(optarg, &tmp, 0); /**如果inode的个数小于1024*/ if (inode_ratio < EXT2_MIN_BLOCK_SIZE || /**或者如果inode的个数大于4096*1024*/ inode_ratio > EXT2_MAX_BLOCK_SIZE * 1024 || /**或者用户输入出错*/ *tmp) { com_err(program_name, 0, _("invalid inode ratio %s (min %d/max %d)"), optarg, EXT2_MIN_BLOCK_SIZE, EXT2_MAX_BLOCK_SIZE); exit(1); } break; |
在用户输入有效数字的基础上,遵循以下两个条件:
1.必须大于等于EXT2_MIN_BLOCK_SIZE;
2.必须小于等于EXT2_MAX_BLOCK_SIZE * 1024;
设定最小值的含义是:每1024个字节就需要一个Inode,也就是说在这个磁盘空间里用户预计放的是很多小于1K的文件。
设定最大值的含义是:每EXT2_MAX_BLOCK_SIZE * 1024个字节 (= 4M)才需要一个Inode,也就是说在这个磁盘空间里用户预计放的是大于等于4M的文件。
Ø 直接寻址和间接寻址
前文说过Inode的作用有两个,一是数据的“指针”,二是保存文件的属性。关于这两个作用,是通过在Inode这个结构体中保存各种文件属性(或数据指针)的值实现的。查看Inode的结构体和ext2_fs.h文件,可以发现一个Inode至多可以保存15个指针,如下:。
| __le32 i_block[EXT2_N_BLOCKS]; /* Pointers to blocks 至多可以有15个“指针” 指向真正存放文件数据的地方*/
|
| /* * Constants relative to the data blocks */ #define EXT2_NDIR_BLOCKS 12 #define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS #define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) #define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) #define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) |
不难看出,对于一个Inode来说,其指针数组结构如下:
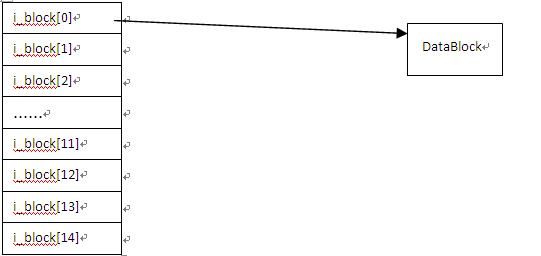
如果15个指针都是直接指向(直接寻址)数据块,而每个数据块的大小而4K,那么一个Inode最大能指向的数据仅为14
*5 = 60K,很显然这种直接寻址的方案是不可用的,因此在EXT2规定0-11的指针采用直接寻址的方式,而12-14的指针采用间接寻址的方式,12号指针采用一级间接寻址,13号指针采用二级间接寻址,14号指针采用三级间接寻址,示意图如下:

一个逻辑块最多可以保存BlockSize/4个指针,如BlockSize为4096,就一级间接寻址而言,可表示的最大空间为:( (4096 / 4) + 12 )*4K = 4144K Bytes;就二级间接寻址而言,可表示的最大空间为:( (4096 / 4)2 +(4096 / 4) + 12 )* 4K = 1049648K Bytes = 1025.04M Bytes ;就三级间接寻址而言,可表示的最大空间为:
( (4096 / 4)3+(4096 / 4)2 +(4096 / 4) + 12 )* 4K = 4299165744 K Bytes = 4198404.046M Bytes = 4100G Bytes = 4T Bytes
通过这种方式,就算是读取大文件的次数也只需4次操作(三级寻址),因此存取性能是很好的。
心细的朋友一定发现了,这里是用EXT2最大允许的BlockSize来计算Inode最能表示的最大单个文件,计算的结果约等于是4T,那是不是就是说EXT2允许最大单文件的大小为4T呢?答案是否定的,关于这点,还是通过查看源代码的方式比较清晰,打开../fs/ext2/super.c
,可以看到:
| /* * Maximal file size. There is a direct, and {,double-,triple-}indirect * block limit, and also a limit of (2^32 - 1) 512-byte sectors in i_blocks. * We need to be 1 filesystem block less than the 2^32 sector limit. */ static loff_t ext2_max_size(int bits) { loff_t res = EXT2_NDIR_BLOCKS; int meta_blocks; loff_t upper_limit;
/* This is calculated to be the largest file size for a * dense, file such that the total number of * sectors in the file, including data and all indirect blocks, * does not exceed 2^32 -1 * __u32 i_blocks representing the total number of * 512 bytes blocks of the file */ upper_limit = (1LL << 32) - 1;
/* total blocks in file system block size */ upper_limit >>= (bits - 9);
/* indirect blocks */ meta_blocks = 1; /* double indirect blocks */ meta_blocks += 1 + (1LL << (bits-2)); /* tripple indirect blocks */ meta_blocks += 1 + (1LL << (bits-2)) + (1LL << (2*(bits-2)));
upper_limit -= meta_blocks; upper_limit <<= bits;
res += 1LL << (bits-2); res += 1LL << (2*(bits-2)); res += 1LL << (3*(bits-2)); res <<= bits; if (res > upper_limit) res = upper_limit;
if (res > MAX_LFS_FILESIZE) res = MAX_LFS_FILESIZE;
return res; } |
可见,函数ext2_max_size的计算结果受两个条件的限制:
1. 小于等于 (1LL << 32) – 1
2. 小于等于 MAX_LFS_FILESIZE
Ø 文件读取与Inode
简单地说,Inode是找到文件的“钥匙”,一个文件对一个Inode。那么利用Inode到底是如何找到我们需要的文件数据的呢?这里设定一个场景:假设有用户在shell中输入more /usr/test.txt后,内核的运作步骤如下:
1. 找到块组描述表的第一个块组描述符,并获得Inode表的起始块号;
2. 找到Inode表所在的这个块,根据预先定义的Inode size偏移到第二个Inode结构体的首地址,EXT2规定第二个Inode才属于根目录的;
3. 根据根目录的Inode所标志的数据块号进行地址偏移,获得根目录的数据(EXT2规定,目录才是特殊的文件,只不过其在数据块中保存的是目录下文件和Inode的信息。)找到目录etc的Inode号;
4. 通过Inode表找到目录usr的Inode结构体的首地址;
5. 通过目录usr的Inode所标志的数据块号进行地址偏移,获得目录usr的数据块,并获得目录usr的数据,找到目录samba的Inode号;
6. 通过Inode表找到文件test.txt的Inode结构体的首地址;
通过文件test.txt的Inode所标志的数据块号进行地址偏移,获得数据块。
另外为了进一步地提高IO性能,EXT2还通过缓冲区高速缓存等手段来提高IO性能。
参考资料:
[ULK] 深入理解Linux内核第三版. DanielP. BovetMarcoCesati
Linux 编程一站式学习
[UNIX] The Art of UNIX Programming. EricRaymond