HA 模式下的 Hadoop+ZooKeeper+HBase 启动关闭管理脚本
HA 集群启动与关闭的顺序请参考:http://blog.csdn.net/u011414200/article/details/50437356
- 一 集群介绍
- 1 集群规划
- 2 正确的启动顺序
- 二 集群管理脚本
- 1 Slaves 配置文件
- 2 ZooKeeper 管理脚本
- 3 JournalNode 管理脚本
- 4 Hadoop 管理脚本
- 5 HBase 管理脚本
- 7 整个集群管理脚本
- 8 配置文件统一分发管理脚本
- 三 验证
- 1 同步集群配置文件
- 2 启动整个大集群
一. 集群介绍
1.1 集群规划
1.2 正确的启动顺序
1. ZooKeeper -> Hadoop -> HBase
2. ZooKeeper -> JournalNode (Hadoop) -> NameNode (Hadoop) -> DataNode (Hadoop) -> 主 ResourceManager/NodeManager (Hadoop) -> 备份 ResourceManager (Hadoop) -> ZKFC (Hadoop) -> MapReduce JobHistory (Hadoop) -> 主 Hmaster/HRegionServer (HBase) ->备份 Hmaster (HBase)
关闭集群的顺序则相反
二. 集群管理脚本
笔者的脚本部署在下面的路径下
/usr/local/cluster/cluster-manager2.1 Slaves 配置文件
1. 文件名:slaves
2. 功能:记录运行 datanode 、nodemanager、HRegionServer、QuorumPeerMain、JournalNode 的节点 IP 地址或主机名
3. 内容
slave51
slave52
slave532.2 ZooKeeper 管理脚本
1. 文件名:zk-manager.sh
2. 功能:启动、关闭与重启 ZooKeeper 集群,并可查看运行 ZK 服务的的模式(leader or follower?)
3. 内容
#!/bin/bash
SLAVES=$(cat slaves)
start_time=`date +%s`
for slave in $SLAVES
do
case $1 in
start) ssh -t $slave "source ~/.bash_profile;zkServer.sh start" 1>/dev/null;;
stop) ssh -t $slave "source ~/.bash_profile;zkServer.sh stop" 1>/dev/null ;;
status) ssh -t $slave "source ~/.bash_profile;zkServer.sh status" ;;
restart)ssh -t $slave "source ~/.bash_profile;zkServer.sh restart" 1>/dev/null;;
*) echo -e "Usage: sh zk-manager.sh {start|stop|restart} ^_^\n" && exit ;;
esac
done
end_time=`date +%s`
elapse_time=$((${end_time}-${start_time}))
echo -e "\n$1 ZooKeeper Server takes ${elapse_time} seconds\n"2.3 JournalNode 管理脚本
1. 文件名:journal-manager.sh
2. 功能:启动、关闭运行在各个 slaves 上的 JournalNode 进程
3. 内容
#!/bin/bash
start_time=`date +%s`
SLAVES=$(cat slaves)
for slave in $SLAVES
do
case $1 in
start) ssh -t $slave "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh start journalnode" ;;
stop) ssh -t $slave "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh stop journalnode" ;;
*) echo -e "Usage: sh journal-manager.sh {start|stop} ^_^\n" && exit ;;
esac
done
end_time=`date +%s`
elapse_time=$((${end_time}-${start_time}))
echo -e "\n$1 JournalNode Server takes ${elapse_time} seconds\n"2.4 Hadoop 管理脚本
1. 文件名:hadoop-manager.sh
2. 功能:管理 hadoop 的启动与关闭
3. 内容
# which machine to be active NameNode
NameNode_1=master5
# which machine to be standy NameNode
NameNode_2=master52
# which machine to be active ResourceManager
ResourceManager_1=master5
# which machine to be standby ResourceManager
ResourceManager_2=master52
# which machine to be JobHistoryServer
HistoryServer=master5
# make sure which namenode is active and which resourcemanager is active
function getServiceState () {
hdfs haadmin -getServiceState ${NameNode_1} | grep 'active' >> /dev/null && NameNode_Active=${NameNode_1} && NameNode_Standby=${NameNode_2}
hdfs haadmin -getServiceState ${NameNode_2} | grep 'active' >> /dev/null && NameNode_Active=${NameNode_2} && NameNode_Standby=${NameNode_1}
yarn rmadmin -getServiceState rm1 | grep 'active' >> /dev/null && ResourceManager_Active=${ResourceManager_1} && ResourceManager_Standby=${ResourceManager_2}
yarn rmadmin -getServiceState rm2 | grep 'active' >> /dev/null && ResourceManager_Active=${ResourceManager_2} && ResourceManager_Standby=${ResourceManager_1}
}
case $1 in
start) ssh -t ${NameNode_1} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh start namenode" ;
ssh -t ${NameNode_1} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh start zkfc" ;
ssh -t ${NameNode_2} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh start namenode" ;
ssh -t ${NameNode_2} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh start zkfc" ;
ssh -t ${NameNode_1} "/usr/local/cluster/hadoop/sbin/hadoop-daemons.sh start datanode" ;
ssh -t ${ResourceManager_1} "/usr/local/cluster/hadoop/sbin/start-yarn.sh" ;
ssh -t ${ResourceManager_2} "/usr/local/cluster/hadoop/sbin/yarn-daemon.sh start resourcemanager" ;
ssh -t ${HistoryServer} "/usr/local/cluster/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver" ;
;;
stop) getServiceState
ssh -t ${HistoryServer} "/usr/local/cluster/hadoop/sbin/mr-jobhistory-daemon.sh stop historyserver" ;
ssh -t ${ResourceManager_Standby} "/usr/local/cluster/hadoop/sbin/yarn-daemon.sh stop resourcemanager" ;
ssh -t ${ResourceManager_Active} "/usr/local/cluster/hadoop/sbin/stop-yarn.sh" ;
ssh -t ${NameNode_Active} "/usr/local/cluster/hadoop/sbin/hadoop-daemons.sh stop datanode" ;
ssh -t ${NameNode_Standby} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh stop namenode" ;
ssh -t ${NameNode_Active} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh stop namenode" ;
ssh -t ${NameNode_Standby} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh stop zkfc" ;
ssh -t ${NameNode_Active} "/usr/local/cluster/hadoop/sbin/hadoop-daemon.sh stop zkfc" ;
;;
* ) echo -e "Usage: hadoop-manager.sh {start|stop} ^_^\n" && exit ;
;;
esac
end_time=`date +%s`
elapse_time=$((${end_time}-${start_time}))
echo -e "$1 Hadoop Server takes ${elapse_time} seconds\n"4. 注意事项
- NameNode_1、NameNode_2、ResourceManager_1、ResourceManager_2、HistoryServer 按实际填写,比如想让 master5 称为 active 则将其赋值给 NameNode_1
- 上述的启动顺序也许和 HA 集群启动与关闭的顺序 略微有点不同,这是因为笔者要在故障自动切换下实现特意选择其中一台作为 active
2.5 HBase 管理脚本
1. 文件名:hbase-manager.sh
2. 功能:启动、关闭 HBase 集群
3. 内容
#!/bin/bash
HMaster_1=master5
HMaster_2=master52
start_time=`date +%s`
SLAVES=$(cat slaves)
function HRegionServer (){
for slave in $SLAVES
do
ssh -t $slave "/usr/local/cluster/hbase/bin/hbase-daemon.sh $1 regionserver"
done
}
case $1 in
start) ssh -t ${HMaster_1} "/usr/local/cluster/hbase/bin/hbase-daemon.sh start master" ;
ssh -t ${HMaster_2} "/usr/local/cluster/hbase/bin/hbase-daemon.sh start master" ;
HRegionServer start
;;
stop) HRegionServer stop
ssh -t ${HMaster_2} "/usr/local/cluster/hbase/bin/hbase-daemon.sh stop master" ;
ssh -t ${HMaster_1} "/usr/local/cluster/hbase/bin/hbase-daemon.sh stop master" ;
;;
* ) echo -e "Usage: sh hbase-manager.sh {start|stop} ^_^\n" && exit;;
esac
end_time=`date +%s`
elapse_time=$((${end_time}-${start_time}))
echo -e "\n$1 Hbase Server takes ${elapse_time} seconds\n"2.7 整个集群管理脚本
1. 文件名:Bigdata-Cluster.sh
2. 功能:统一启动、关闭及查看 ZooKeeper+Hadoop+HBase 大集群
3. 内容
#!/bin/bash
CLUSTER_CONF_PATH=$(cd "$(dirname "$0")"; pwd)
NameNode_1=master5
NameNode_2=master52
SLAVE_1=slave51
start_time=`date +%s`
function showJps() {
echo -e "\n**********************************************************************************"
echo -e "当前 ${NameNode_1} 上的进程为:" && ssh -t ${NameNode_1} "source ~/.bash_profile; jps"
echo -e "\n**********************************************************************************"
echo -e "当前 ${NameNode_2} 上的进程为:" && ssh -t ${NameNode_2} "source ~/.bash_profile; jps"
echo -e "\n**********************************************************************************"
echo -e "当前 ${SLAVE_1} 上的进程为:" && ssh -t ${SLAVE_1} "source ~/.bash_profile; jps"
echo -e "************************************************************************************"
}
case $1 in
start) sh $CLUSTER_CONF_PATH/zk-manager.sh start ;
sh $CLUSTER_CONF_PATH/journal-manager.sh start ;
sh $CLUSTER_CONF_PATH/hadoop-manager.sh start ;
sh $CLUSTER_CONF_PATH/hbase-manager.sh start ;
showJps
;;
stop) sh $CLUSTER_CONF_PATH/hbase-manager.sh stop ;
sh $CLUSTER_CONF_PATH/hadoop-manager.sh stop ;
sh $CLUSTER_CONF_PATH/journal-manager.sh stop ;
sh $CLUSTER_CONF_PATH/zk-manager.sh stop ;
showJps
;;
status) showJps
;;
*) echo -e "Usage: sh Bigdata-Cluster.sh {start|stop|status} ^_^\n" ;;
esac
end_time=`date +%s`
elapse_time=$((${end_time}-${start_time}))
echo -e "\n$1 Bigdata Cluster takes ${elapse_time} seconds\n"2.8 配置文件统一分发管理脚本
1. 文件名:cluster-rsync.sh
2. 功能:在已经安装 rsync 服务器的情况下,在配合该脚本,即可实现在主节点上修改配置文件,其他节点迅速更新 (因为采用的 增量备份)
3. 内容
!/bin/bash
RSYN_SECRET_PATH=/home/hadoop5/softwares/rsyncd/rsyncd.secrets
NN_STANDBY=master52
SLAVES=$(cat slaves)
RSYNC_PORT=1873
RSYNC_SERVER=master5
function updateHadoopConf () {
echo -e "\n****************************** Hadoop **********************************************\n"
for slave in $SLAVES
do
ssh -t ${slave} "rsync -avz --port=${RSYNC_PORT} --password-file=${RSYN_SECRET_PATH} ${RSYNC_SERVER}::hadoop $HADOOP_HOME/etc/hadoop" #1>/dev/null
echo -e "\n"
done
echo -e "\n"
ssh -t ${NN_STANDBY} "rsync -avz --port=${RSYNC_PORT} --password-file=${RSYN_SECRET_PATH} ${RSYNC_SERVER}::hadoop $HADOOP_HOME/etc/hadoop" #1>/dev/null
}
function updateHbaseConf () {
echo -e "\n***************************** Hbase **********************************************\n"
for slave in $SLAVES
do
ssh -t ${slave} "rsync -avz --port=${RSYNC_PORT} --password-file=${RSYN_SECRET_PATH} ${RSYNC_SERVER}::hbase $HBASE_HOME/conf" #1>/dev/null
echo -e "\n"
done
echo -e "\n"
ssh -t ${NN_STANDBY} "rsync -avz --port=${RSYNC_PORT} --password-file=${RSYN_SECRET_PATH} ${RSYNC_SERVER}::hbase $HBASE_HOME/conf" #1>/dev/null
}
case $1 in
hadoop) updateHadoopConf ;;
hbase) updateHbaseConf ;;
all ) updateHadoopConf;updateHbaseConf ;;
*) echo -e "Usage: sh cluster-rsync.sh {hadoop|hbase|all} ^_^\n" && exit ;;
esac三. 验证
3.1 同步集群配置文件
sh cluster-rsync.sh all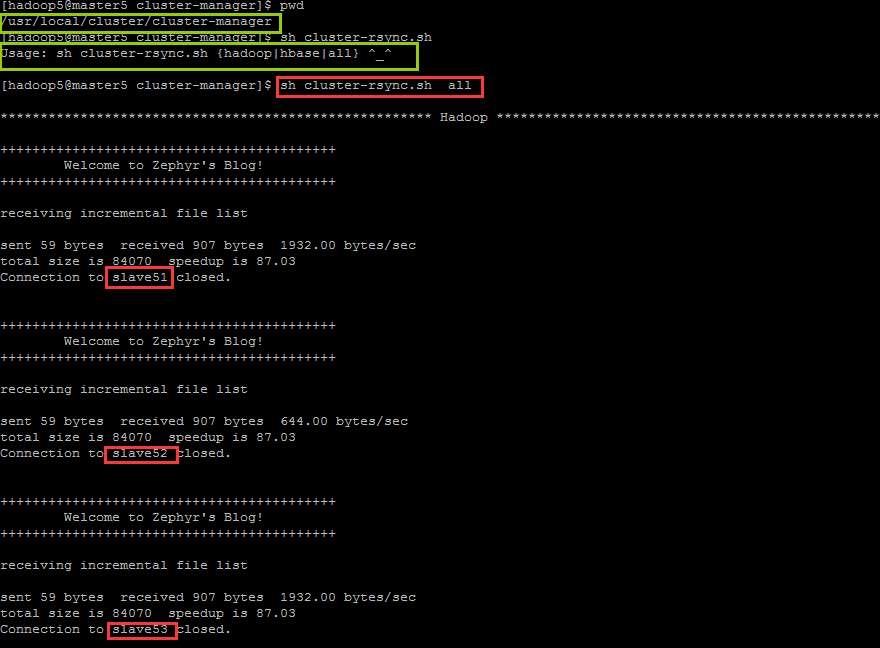
3.2 启动整个大集群
1. 启动前查看大集群的状态
sh Bigdata-Cluster.sh status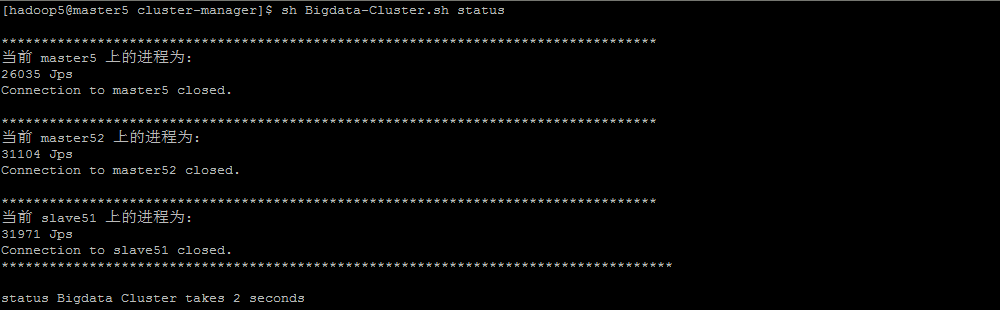
2. 启动大集群
sh Bigdata-Cluster.sh start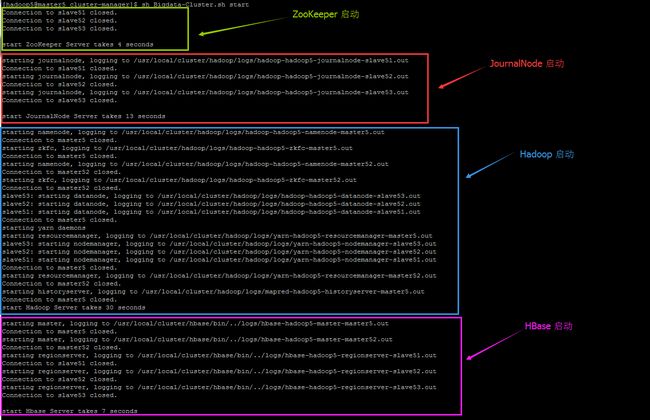
3. 启动后的进程
sh Bigdata-Cluster.sh status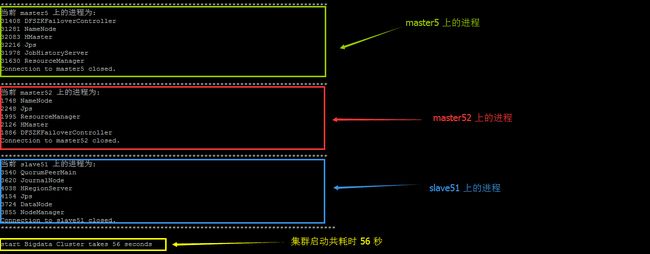
4. 关闭大集群
sh Bigdata-Cluster.sh stop