HDU3523 Image copy detection 最小权匹配KM 2010 ACM-ICPC Multi-University Training Contest(9)——Host by HNU
Image copy detection
Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)
Total Submission(s): 169 Accepted Submission(s): 114
Problem Description
The success of the Internet and cost-effective digital storage device has made it possible to replicate, transmit, and distribute digital content in an effortless way. Thus, the protection of intellectual Property right (IPR) has become a crucial legal issue. Detecting copies of digital media(images, audio and video) is a basic requirement for IPR protection (or copyright protection).The applications of copydetection include usage tracking and copyright violation enforcement.
For those above purposes, the image copy detection system came out.It aggregated all the images which were viewed as a copy of original image.In this system,an image is partitioned into m×n equalsized blocks,which makes the system independent of input image sizes,and an m×n sub-image is calculated by taking the average value of each block(see Figure.1(b)), This array is converted to a rank matrix as shown in Fig.1(c).Suppose that the intensity values in Fig.1(b) are changed in the copied image so that its sub-image has values:{{30, 60, 40}, {70, 90, 110}, {50, 100, 80}}. Nevertheless,its rank matrix is identical to that shown in Fig. 1(c) and thus perfect matching with original image can be achieved.
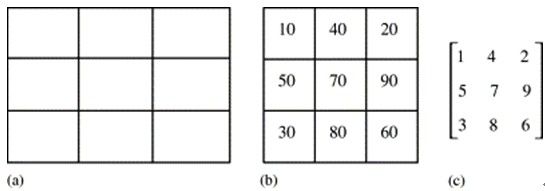
Fig.1 (a)An image is divided into m×n blocks (3×3 in this example),(b)average values of blocks, and(c)rank matrix of (b). Let T and Q represent test image and original image,N represent the matrix size;there exists N tuples (t1,q1),…,( tn,qn),…,( tN,qN)(the order of the rank matrix:from left to right and from top to bottom).Now we define D(T,Q) =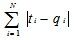 measures the distance between the two images(it’s obvious that if D(T,Q) gets smaller while the probability of the test image is considered as a copy of original image by the system becomes larger). Since there are M original images in the image copy detection system(Q1…QM). And the distance between T and some original images is given by D(T,Q1…QM)=
measures the distance between the two images(it’s obvious that if D(T,Q) gets smaller while the probability of the test image is considered as a copy of original image by the system becomes larger). Since there are M original images in the image copy detection system(Q1…QM). And the distance between T and some original images is given by D(T,Q1…QM)=
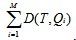 To make it simple,we want to find an image which owns least D(T,Q1…QM).
To make it simple,we want to find an image which owns least D(T,Q1…QM).
For those above purposes, the image copy detection system came out.It aggregated all the images which were viewed as a copy of original image.In this system,an image is partitioned into m×n equalsized blocks,which makes the system independent of input image sizes,and an m×n sub-image is calculated by taking the average value of each block(see Figure.1(b)), This array is converted to a rank matrix as shown in Fig.1(c).Suppose that the intensity values in Fig.1(b) are changed in the copied image so that its sub-image has values:{{30, 60, 40}, {70, 90, 110}, {50, 100, 80}}. Nevertheless,its rank matrix is identical to that shown in Fig. 1(c) and thus perfect matching with original image can be achieved.
Fig.1 (a)An image is divided into m×n blocks (3×3 in this example),(b)average values of blocks, and(c)rank matrix of (b). Let T and Q represent test image and original image,N represent the matrix size;there exists N tuples (t1,q1),…,( tn,qn),…,( tN,qN)(the order of the rank matrix:from left to right and from top to bottom).Now we define D(T,Q) =
Input
The first line of input should give the number of cases, T (at most 100). T test cases follow. The first line of each test case contains two integer n (1 ≤ n ≤ 100) and m(1 ≤ m ≤ 100) indicating the size of rank matrix and number of original images. The following m lines each contains a sequence of n different integers denotes the rank matrix.
Output
For each test case, output one line containing "Case #x: y", where x is the case number (starting from 1) and y is the least distance D(T,Q1…QM).
Sample Input
2
3 2
1 2 3
1 3 2
9 3
1 4 2 5 7 9 3 8 6
2 1 4 5 9 3 7 6 8
9 8 7 6 5 4 3 2 1
3 2
1 2 3
1 3 2
9 3
1 4 2 5 7 9 3 8 6
2 1 4 5 9 3 7 6 8
9 8 7 6 5 4 3 2 1
Sample Output
Case #1: 2
Case #2: 58
Case #2: 58
Source
2010 ACM-ICPC Multi-University Training Contest(9)——Host by HNU
Recommend
zhengfeng
题目意思是定义两个排列a、b的距离d=sum(ai-bi),现在给出m个排列,求一个排列t,使其与m个排列的d值的和最小。
看了别人的解题报告才知道是KM。
建立二分图:
左边节点表示m个排列第i个位置,右边就是1到n,n个数
i到j连边,边权为-sum(abs(Aij-j))
求最小权匹配,匹配边i-->j代表j这个数是在i这个位置,这样一个匹配就代表一个n个数的排列,并且sum(d)最小。
代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#include<cstdio>
#define N 105
#define inf 999999999
int t,tt,n,m,d,a[N][N],lx[N],ly[N],w[N][N],pre[N];
bool bx[N],by[N];
int dfs(int u)
{
int v,t;
bx[u]=1;
for(v=1;v<=n;v++)
if(!by[v])
{
t=lx[u]+ly[v]-w[u][v];
if(t)
d=min(d,t);
else
{
by[v]=1;
if(pre[v]==-1||dfs(pre[v]))
{
pre[v]=u;
return 1;
}
}
}
return 0;
}
int KM()
{
int i,j,ans=0;
for(i=1;i<=n;i++)
{
pre[i]=-1;
lx[i]=-inf;
ly[i]=0;
for(j=1;j<=n;j++)
lx[i]=max(lx[i],w[i][j]);
}
for(i=1;i<=n;i++)
while(1)
{
d=inf;
for(j=1;j<=n;j++)
bx[j]=by[j]=0;
if(dfs(i))
break;
for(j=1;j<=n;j++)
{
if(bx[j])
lx[j]-=d;
if(by[j])
ly[j]+=d;
}
}
for(i=1;i<=n;i++)
ans+=w[pre[i]][i];
return ans;
}
int main()
{
scanf("%d",&t);
while(t--)
{
scanf("%d%d",&n,&m);
int i,j,k;
for(i=1;i<=m;i++)
for(j=1;j<=n;j++)
scanf("%d",&a[i][j]);
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
{
w[i][j]=0;
for(k=1;k<=m;k++)
w[i][j]-=abs(a[k][i]-j);
}
printf("Case #%d: %d\n",++tt,-KM());
}
}