简单的MapReduce程序(Hadoop2.2.0)
继上篇文章: 配置Hadoop开发环境(Eclipse) http://blog.csdn.net/zythy/article/details/17397153
我们以简化版的气温统计为例,演示如何开发一个MapReduce程序。
Eclipse中新建一个MapReduce项目,命名为MaxTemperature。
源代码文件
新建以下3个类文件,代码依次如下:
MaxTemperatureDriver.java
package com.oss.maxtemperature;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.conf.Configured;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
importorg.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.util.Tool;
importorg.apache.hadoop.util.ToolRunner;
public class MaxTemperatureDriver extends Configuredimplements Tool {
@SuppressWarnings("deprecation")
@Override
public int run(String[] args) throwsException {
if (args.length != 2){
System.err.printf("Usage: %s <input><output>",getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Configuration conf =getConf();
Job job = newJob(getConf());
job.setJobName("Max Temperature");
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args)throws Exception{
int exitcode = ToolRunner.run(new MaxTemperatureDriver(), args);
System.exit(exitcode);
}
}
MaxTemperatureMapper.java
packagecom.oss.maxtemperature;
importjava.io.IOException;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.LongWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line =value.toString();
try {
String year =line.substring(0,4);
int airTemperature = Integer.parseInt(line.substring(5));
context.write(new Text(year),new IntWritable(airTemperature));
} catch (Exception e) {
System.out.print("Error in line:" + line);
}
}
}
MaxTemperatureReducer.java
packagecom.oss.maxtemperature;
importjava.io.IOException;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer extendsReducer<Text,IntWritable,Text,IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for(IntWritable value: values){
maxValue = Math.max(maxValue,value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
导出为.Jar文件
将项目导出为jar文件,注意选择MaxTemperatureDriver作为包含main的类。
运行MapReduce程序
请确保Hadoop相关服务已经启动。
准备数据文件:
我们假设在hdfs://localhost:9000/input目录下有4个数据文件,如下图:
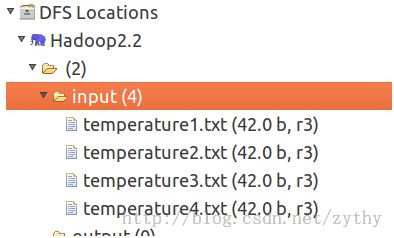
其中,文件的内容格式如下:
1990 21
1990 18
1991 21
1992 30
1990 21
说明:一个文件包含多行数据,前4位为年份,第5位为空格,第6位起为对应的温度。
进入Hadoop安装目录下的bin目录,执行以下命令:
./hadoopjar ~/hadoop_jar/maxtemperature.jar hdfs://localhost:9000/input hdfs://localhost:9000/output/temperature
注意:
以上命令请在一行输入。
请确保jar文件路径正确。
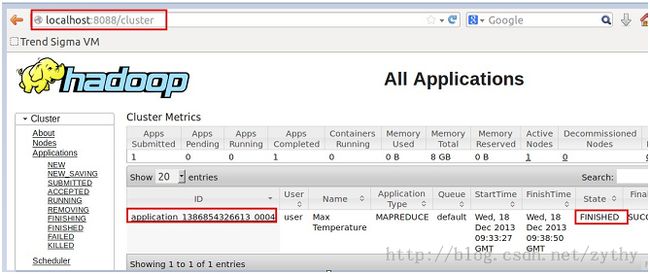
通过命令行或者UI接口查看job的工作进度,如下图所示,job已成功完成。
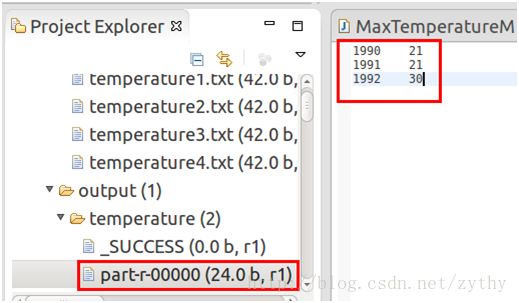
最终结果如下图:
发生错误怎么办?
有时候,你会发现job被提交后一直处于pending状态。此时,应该检查所有的hadoop服务是否正常工作。运行jps命令查看hadoop相关服务,如下图:
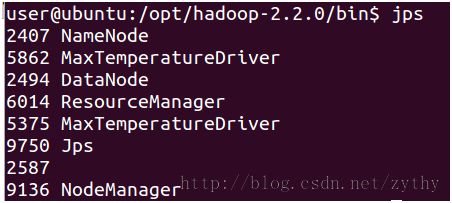
请确保Namenode,DataNode,ResourceManager,NodeManager正常启动。如果发现有服务未启动,应该尝试重新启动服务,或者查看对应的log文件。比如某些配置错误会导致NodeManager服务在有job提交后因为发生异常而停止服务。
源代码
包含4个数据文件。
下载地址:http://download.csdn.net/detail/zythy/6735883