checkpoint RBA (即low cache RBA)的说明
Oracle RBA 浅谈
今天来和大家简单谈一下rba ,rba = redo byte address 。
讲到Oracle 实例恢复时的几个rba概念(还有该rba定位的那个redo记录里的scn字段),这里涉及到了几点需要大家提前预知,即controlfile header,ckpt process 与 dbwn process , dirty buffer 。
先来看一下RBA的构成:
它由3部分组成,4byte+4byte+2byte分别为 logfile sequence number ,logfile block number,byte offsetinto the block ,即redo 序列号,redo block 号,以及偏移量。
并且全部使用16进制。
例如:rba= 0x000024.000011bd.0010
seq#=0x000024=36
blk#=0x000011bd=4541
ofs#=0x0010=16
接下来说一下instance recovery
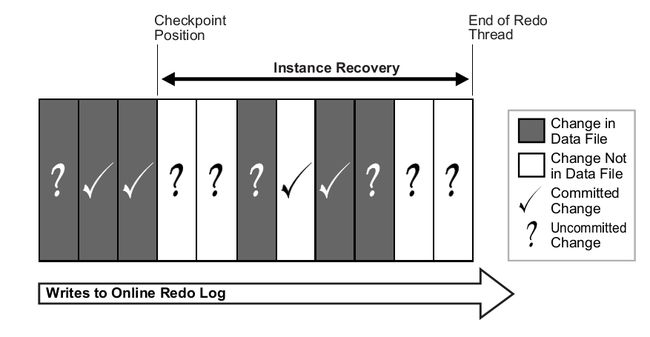
这里的Checkpoint position 其实就是cache low rba, End of redo thread就是最后一个on-disk rba。
大家都知道实例恢复的时候需要从cache low rba 到 on-disk rba , lowrba 与 on-disk 全部存储在控制文件里面,on-diskrba 可以简单的理解为是 lgwr 最后写日志文件的地址。那么cache low rba是如何而来呢?
cache low rba 其实就是ckpt进程每3秒写入到controlfileheader 上面的rba 。
大家知道 ckpt 分为三种,即 database check points ,Tablespace and datafile checkpoints和Incremental checkpoints。前两种属于完全检查点类型,后一种属于增量检查点类型。
这里和第三种checkpoints有关。增量检查点的存在是为了防止在发生日志切换的时候,写出大量的dirty block 到disk上面,它每3秒会监控一下dbwn写出block的情况,并且写到controlfile header里面(不包括datafile header)。
这里有几点需要注意:
1. dbwn 写出 dirtyblock 是使用一个叫做ckpt queue的双向链表来维护的,按照lrba的顺序写出dirty block 到 disk 上面。
2. 每个dirty block 上面都有一个lrba ,并且有一个指向ckpt queue的指针。
3. dbwn触发条件,请详见concepts。
好,下面我们用实验说话:
1. 先取出几个块的数据
01:57:02 dex@FAKE> select * from
01:58:10 2 (
01:58:10 3 selectdbms_rowid.rowid_relative_fno(substr(rowid,1,15)||'AAA') as file# ,
01:58:10 4 dbms_rowid.rowid_block_number(substr(rowid,1,15)||'AAA') as blk#,
01:58:10 5 max(t.id),max(t.name)
01:58:10 6 from dex.t
01:58:10 7 group by substr(rowid,1,15)
01:58:10 8 )
01:58:10 9 where rownum < 4 ;
FILE# BLK# MAX(T.ID) MAX(T.NAME)
---------- ---------- ---------- --------------------
4 446 37949 name
4 447 38433 name
4 442 39401 name
看一下x$bh
02:02:17 sys@FAKE> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=4 and dbablk in (442,446,447);
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
442 0 0 524288
447 0 0 524288
446 0 0 524288
看一下当前的cache low rba 和 ondisk rba
02:02:21 sys@FAKE> selectcplrba_seq,cplrba_bno,cplrba_bof,cpodr_seq,cpodr_bno,cpodr_bof,cphbt,cpodt fromx$kcccp where indx=0 ;
CPLRBA_SEQ CPLRBA_BNO CPLRBA_BOF CPODR_SEQ CPODR_BNO CPODR_BOF CPHBT CPODT
---------- ---------- ---------- -------------------- ---------- ---------- --------------------
37 10567 0 37 13157 0 791349660 08/15/2012 02:02:02
2. 更新数据
02:07:16 sys@FAKE> update dex.t set name='aaaa'where id=37949 ;
1 row updated.
02:10:46 sys@FAKE> update dex.t set name='ssss'where id=38433 ;
1 row updated.
02:10:46 sys@FAKE> update dex.t set name='dddd'where id=39401 ;
1 row updated.
02:10:48 sys@FAKE> commit ;
Commit complete.
3. 查看一下各种状态
状态为脏数据
02:10:51 sys@FAKE> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=4 and dbablk in (442,446,447);
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
442 37
14429 33554433
447 37
14429 33554433
446 37
14429 33554433
现在的cache low rba 为14104
02:10:56 sys@FAKE> selectcplrba_seq,cplrba_bno,cplrba_bof,cpodr_seq,cpodr_bno,cpodr_bof,cphbt,cpodt fromx$kcccp where indx=0 ;
CPLRBA_SEQ CPLRBA_BNO CPLRBA_BOF CPODR_SEQ CPODR_BNO CPODR_BOF CPHBT CPODT
---------- ---------- ---------- -------------------- ---------- ---------- --------------------
37
14104 0 37 14437 0 791349830 08/15/2012 02:10:51
4. 再来更新一下442块的内容
02:12:00 sys@FAKE> update dex.t setname='bfsdff' where id=39401 ;
1 row updated.
02:10:10 sys@FAKE> commit ;
Commit complete.
可以看到flag变了,但是这个block的lrba确没有变,这是因为对于一个dirty block 只会有一个lrba。直到这个dirty block被写出到disk为止。
02:12:36 sys@FAKE> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=4 and dbablk in (442,446,447);
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
442 37
14429 33554441
447 37
14429 33554433
446 37
14429 33554433
我们可以看到这时的 cache low rba 已经为14398 这说明 14398以前的dirty block 已经被写出到disk上。
02:12:55 sys@FAKE> selectcplrba_seq,cplrba_bno,cplrba_bof,cpodr_seq,cpodr_bno,cpodr_bof,cphbt,cpodt fromx$kcccp where indx=0 ;
CPLRBA_SEQ CPLRBA_BNO CPLRBA_BOF CPODR_SEQ CPODR_BNO CPODR_BOF CPHBT CPODT
---------- ---------- ---------- -------------------- ---------- ---------- --------------------
37 14398 0 37 14491 0 791349872 08/15/2012 02:12:13
再来看一下buffer中的内容。lrba的内容已经被清掉了。
02:15:47 sys@FAKE> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=4 and dbablk in (442,446,447);
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
442 0 0 35651584
447 0 0 35651584
446 0 0 35651584
关于实例恢复:
实例恢复是从cache low rba 到 ondisk rba的,但是ckpt 确实每3秒检查一次dbwn写出的状态,所以就有可能出现dirty block 已经写出到disk上,但是却没有记录到controlfile header 上面。这个时候,实例恢复还是从上一次记录的cache low rba 开始恢复。
下面有个实例恢复的trace信息,见附录2。
使用dump logfile 命令查看dirty block当前rba。具体请看下面的附录1。
附录1
查看dirty block 当前rba
sys@FAKE> set time on
02:34:21 sys@FAKE> oradebug setmypid
Statement processed.
02:34:24 sys@FAKE> oradebugtracefile_name
/u01/apps/oracle/diag/rdbms/fake/fake/trace/fake_ora_7405.trc
02:34:28 sys@FAKE> selectl.sequence#,l.group#,l.status,f.status,member from v$log l , v$logfile f wherel.group#=f.group# ;
SEQUENCE# GROUP# STATUS STATUS
---------- ---------- -----------------------
MEMBER
------------------------------------------------------------------------------------------------------------------------------------------------------
36 3 INACTIVE
/u01/apps/oracle/oradata/fake/redo03.log
35 2 INACTIVE
/u01/apps/oracle/oradata/fake/redo02.log
37 1 CURRENT
/u01/apps/oracle/oradata/fake/redo01.log
02:35:14 sys@FAKE> alter system dumplogfile '/u01/apps/oracle/oradata/fake/redo01.log'
02:35:28 2 dba min 4 442
02:36:38 3 dba max 4 442 ;
System altered.
02:36:42 sys@FAKE> !vi/u01/apps/oracle/diag/rdbms/fake/fake/trace/fake_ora_7405.trc
主要片段
REDO RECORD - Thread:1 RBA:0x000025.0000389a.0010 LEN: 0x01e0 VLD: 0x0d
SCN: 0x0000.0017af70 SUBSCN: 1 08/15/2012 02:12:13
rba=seq#37 blk#14490
附录2
实例恢复片段
23:51:08 sys@FAKE> selectcplrba_seq,cplrba_bno,cplrba_bof,cpodr_seq,cpodr_bno,cpodr_bof,cphbt,cpodt fromx$kcccp where indx=0 ;
CPLRBA_SEQ CPLRBA_BNO CPLRBA_BOF CPODR_SEQ CPODR_BNO CPODR_BOF CPHBT CPODT
---------- ---------- ---------- -------------------- ---------- ---------- --------------------
36
7988 0 36
8068 0 791347039 08/14/2012 23:47:34
实例恢复trace关键性信息
THREAD #1 - status:0x2 flags:0x0 dirty:25
low cacherba:(0x24.1f34.0) on disk rba:(0x24.1f84.0)
on disk scn: 0x0000.0017453f 08/14/201223:47:34
resetlogs scn: 0x0000.000ce1bd 07/08/201213:36:03
heartbeat: 791347199 mount id: 4210244756
0x24.1f34.0=seq#36blk#7988
0x24.1f84.0=seq#36blk#8068
x$bh flag 含义 :http://blog.csdn.net/wzy0623/article/details/3089712
Dirty buffers are maintained on the buffer cache checkpoint queues in low RBA order.The checkpoint RBA is the point up to which DBWn has written buffers from the checkpoint queues if incremental checkpointing is enabled --otherwise it is the RBA of last full thread checkpoint.