考察数据结构——第二部分:队列、堆栈和哈希表[译]
本文是"考察数据结构"系列文章的第二部分,考察了三种研究得最多的数据结构:队列(Queue),堆栈(Stack)和哈希表(Hashtable)。正如我们所知,Quenu和Stack其实一种特殊的ArrayList,提供大量不同类型的数据对象的存储,只不过访问这些元素的顺序受到了限制。Hashtable则提供了一种类数组(array-like)的数据抽象,它具有更灵活的索引访问。数组需要通过序数进行索引,而Hashtable允许通过任何一种对象索引数据项。
目录:
简介
“排队顺序”的工作进程
“反排队顺序”——堆栈数据结构
序数索引限制
System.Collections.Hashtable类
结论
简介
在第一部分中,我们了解了什么是数据结构,评估了它们各自的性能,并了解了选择何种数据结构对特定算法的影响。另外我们还了解并分析了数据结构的基础知识,介绍了一种最常用的数据结构:数组。
数组存储了同一类型的数据,并通过序数进行索引。数组实际的值是存储在一段连续的内存空间中,因此读写数组中特定的元素非常迅速。
因其具有的同构性及定长性,.Net Framework基类库提供了ArrayList数据结构,它可以存储不同类型的数据,并且不需要显式地指定长度。前文所述,ArrayList本质上是存储object类型的数组,每次调用Add()方法增加元素,内部的object数组都要检查边界,如果超出,数组会自动以倍数增加其长度。
第二部分,我们将继续考察两种类数组结构:Queue和Stack。和ArrayList相似,他们也是一段相邻的内存块以存储不同类型的元素,然而在访问数据时,会受到一定的限制。
之后,我们还将深入了解Hashtable数据结构。有时侯,我们可以把Hashtable看作杀一种关联数组(associative array),它同样是存储不同类型元素的集合,但它可通过任意对象(例如string)来进行索引,而非固定的序数。
“排队顺序”的工作进程
如果你要创建不同的服务,这种服务也就是通过多种资源以响应多种请求的程序;那么当处理这些请求时,如何决定其响应的顺序就成了创建服务的一大难题。通常解决的方案有两种:
“排队顺序”原则
“基于优先等级”的处理原则
当你在商店购物、银行取款的时候,你需要排队等待服务。“排队顺序”原则规定排在前面的比后面的更早享受服务。而“基于优先等级”原则,则根据其优先等级的高低决定服务顺序。例如在医院的急诊室,生命垂危的病人会比病情轻的更先接受医生的诊断,而不用管是谁先到的。
设想你需要构建一个服务来处理计算机所接受到的请求,由于收到的请求远远超过计算机处理的速度,因此你需要将这些请求按照他们递交的顺序依此放入到缓冲区中。
一种方案是使用ArrayList,通过称为nextJobPos的整型变量来指定将要执行的任务在数组中的位置。当新的工作请求进入,我们就简单使用ArrayList的Add()方法将其添加到ArrayList的末端。当你准备处理缓冲区的任务时,就通过nextJobPos得到该任务在ArrayList的位置值以获取该任务,同时将nextJobPos累加1。下面的程序实现该算法:
using System; using System.Collections; public class JobProcessing
{
private static ArrayList jobs = new ArrayList(); private static int nextJobPos = 0; public static void AddJob(string jobName)
{ jobs.Add(jobName);
}
public static string GetNextJob()
{
if (nextJobPos > jobs.Count - 1)
return "NO JOBS IN BUFFER";
else
{
string jobName = (string) jobs[nextJobPos];
nextJobPos++;
return jobName;
}
}
public static void Main()
{
AddJob("1");
AddJob("2");
Console.WriteLine(GetNextJob());
AddJob("3");
Console.WriteLine(GetNextJob());
Console.WriteLine(GetNextJob());
Console.WriteLine(GetNextJob());
Console.WriteLine(GetNextJob());
AddJob("4");
AddJob("5");
Console.WriteLine(GetNextJob());
}
}
输出结果如下:
1
2
3
NO JOBS IN BUFFER
NO JOBS IN BUFFER
4
这种方法简单易懂,但效率却可怕得难以接受。因为,即使是任务被添加到buffer中后立即被处理,ArrayList的长度仍然会随着添加到buffer中的任务而不断增加。假设我们从缓冲区添加并移除一个任务需要一秒钟,这意味一秒钟内每调用AddJob()方法,就要调用一次ArrayList的Add()方法。随着Add()方法持续不断的被调用,ArrayList内部数组长度就会根据需求持续不断的成倍增长。五分钟后,ArrayList的内部数组增加到了512个元素的长度,这时缓冲区中却只有不到一个任务而已。照这样的趋势发展,只要程序继续运行,工作任务继续进入,ArrayList的长度自然会继续增长。
出现如此荒谬可笑的结果,原因是已被处理过的旧任务在缓冲区中的空间没有被回收。也即是说,当第一个任务被添加到缓冲区并被处理后,此时ArrayList的第一元素空间应该被再利用。想想上述代码的工作流程,当插入两个工作——AddJob("1")和AddJob("2")后——ArrayList的空间如图一所示: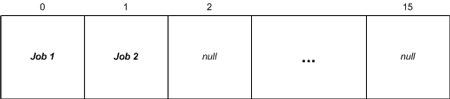 图一:执行前两行代码后的ArrayList
图一:执行前两行代码后的ArrayList
注意这里的ArrayList共有16个元素,因为ArrayList初始化时默认的长度为16。接下来,调用GetNextJob()方法,移走第一个任务,结果如图二:
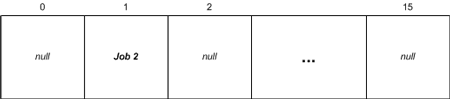 图二:调用GetNextJob()方法后的ArrayList
图二:调用GetNextJob()方法后的ArrayList
当执行AddJob(“3”)时,我们需要添加新任务到缓冲区。显然,ArrayList的第一元素空间(索引为0)被重新使用,此时在0索引处放入了第三个任务。不过别忘了,当我们执行了AddJob(“3”)后还执行了AddJob(“4”),紧接着用调用了两次GetNextJob()方法。如果我们把第三个任务放到0索引处,则第四个任务会被放到索引2处,问题发生了。如图三:![考察数据结构——第二部分:队列、堆栈和哈希表[译]_第1张图片](http://img.e-com-net.com/image/info5/5e586bb7e38f4045996f5b6fe2007892.gif) 图三:将任务放到0索引时,问题发生
图三:将任务放到0索引时,问题发生
现在调用GetNextJob(),第二个任务从缓冲中移走,nextJobPos指针指向索引2。因此,当再一次调用GetNextJob()时,第四个任务会先于第三个被移走,这就有悖于与我们的“排序顺序”原则。
问题发生的症结在于ArrayList是以线形顺序体现任务列表的。因此我们需要将新任务添加到就任务的右恻以保证当前的处理顺序是正确的。不管何时到达ArrayList的末端,ArrayList都会成倍增长。如果产生产生未被使用的元素,则是因为调用了GetNextJob()方法。
解决之道是使我们的ArrayList成环形。环形数组没有固定的起点和终点。在数组中,我们用变量来维护数组的起止点。环形数组如图四所示:
![考察数据结构——第二部分:队列、堆栈和哈希表[译]_第2张图片](http://img.e-com-net.com/image/info5/3f1f47383d134b03886a0ce85074c561.jpg) 图四:环形数组图示
图四:环形数组图示
在环形数组中,AddJob()方法添加新任务到索引endPos处(译注:endPos一般称为尾指针),之后“递增”endPos值。GetNextJob()方法则根据头指针startPos获取任务,并将头指针指向null,且“递增”startPos值。我之所以把“递增”两字加上引号,是因为这里所说的“递增”不仅仅是将变量值加1那么简单。为什么我们不能简单地加1呢?请考虑这个例子:当endPos等于15时,如果endPos加1,则endPos等于16。此时调用AddJob(),它试图去访问索引为16的元素,结果出现异常IndexOutofRangeException。
事实上,当endPos等于15时,应将endPos重置为0。通过递增(increment)功能检查如果传递的变量值等于数组长度,则重置为0。解决方案是将变量值对数组长度值求模(取余),increment()方法的代码如下:
int increment(int variable)
{
return (variable + 1) % theArray.Length;
}
注:取模操作符,如x % y,得到的是x 除以 y后的余数。余数总是在0 到 y-1之间。
这种方法好处就是缓冲区永远不会超过16个元素空间。但是如果我们要添加超过16个元素空间的新任务呢?就象ArrayList的Add()方法一样,我们需要提供环形数组自增长的能力,以倍数增长数组的长度。
System.Collection.Queue类
就象我们刚才描述的那样,我们需要提供一种数据结构,能够按照“排队顺序”的原则插入和移除元素项,并能最大化的利用内存空间,答案就是使用数据结构Queue。在.Net Framework基类库中已经内建了该类——System.Collections.Queue类。就象我们代码中的AddJob()和GetNextJob()方法,Queue类提供了Enqueue()和Dequeue()方法分别实现同样的功能。
Queue类在内部建立了一个存放object对象的环形数组,并通过head和tail变量指想该数组的头和尾。默认状态下,Queue初始化的容量为32,我们也可以通过其构造函数自定义容量。既然Queue内建的是object数组,因此可以将任何类型的元素放入队列中。
Enqueue()方法首先判断queue中是否有足够容量存放新元素。如果有,则直接添加元素,并使索引tail递增。在这里tail使用求模操作以保证tail不会超过数组长度。如果空间不够,则queue根据特定的增长因子扩充数组容量。增长因子默认值为2.0,所以内部数组的长度会增加一倍。当然你也可以在构造函数中自定义该增长因子。
Dequeue()方法根据head索引返回当前元素。之后将head索引指向null,再“递增”head的值。也许你只想知道当前头元素的值,而不使其输出队列(dequeue,出列),则Queue类提供了Peek()方法。
Queue并不象ArrayList那样可以随机访问,这一点非常重要。也就是说,在没有使前两个元素出列之前,我们不能直接访问第三个元素。(当然,Queue类提供了Contains()方法,它可以使你判断特定的值是否存在队列中。)如果你想随机的访问数据,那么你就不能使用Queue这种数据结构,而只能用ArrayList。Queue最适合这种情况,就是你只需要处理按照接收时的准确顺序存放的元素项。
注:你可以将Queues称为FIFO数据结构。FIFO意为先进先出(First In, First Out),其意等同于“排队顺序(First come, first served)”。
译注:在数据结构中,我们通常称队列为先进先出数据结构,而堆栈则为先进后出数据结构。然而本文没有使用First in ,first out的概念,而是first come ,first served。如果翻译为先进先服务,或先处理都不是很适合。联想到本文在介绍该概念时,以商场购物时需要排队为例,索性将其译为“排队顺序”。我想,有排队意识的人应该能明白其中的含义吧。那么与之对应的,对于堆栈,只有名为“反排队顺序”,来代表(First Come, Last Served)。希望各位朋友能有更好地翻译来取代我这个拙劣的词语。为什么不翻译为“先进先出”,“先进后出”呢?我主要考虑到这里的英文served,它所包含的含义很广,至少我们可以将其认为是对数据的处理,因而就不是简单地输出那么简单。所以我干脆避开这个词语的含义。 “反排队顺序”——堆栈数据结构
Queue数据结构通过使用内部存储object类型的环形数组以实现“排队顺序”的机制。Queue提供了Enqueue()和Dequeue()方法实现数据访问。“排队顺序”在处理现实问题时经常用到,尤其是提供服务的程序,例如web服务器,打印队列,以及其他处理多请求的程序。
在程序设计中另外一个经常使用的方式是“反排队顺序(first come,last served)”。堆栈就是这样一种数据结构。在.Net Framework基类库中包含了System.Collection.Stack类,和Queue一样,Stack也是通过存储object类型数据对象的内部环形数组来实现。Stack通过两种方法访问数据——Push(item),将数据压入堆栈;Pop()则是将数据弹出堆栈,并返回其值。
一个Stack可以通过一个垂直的数据元素集合来形象地表示。当元素压入堆栈时,新元素被放到所有其他元素的顶端,弹出时则从堆栈顶端移除该项。下面两幅图演示了堆栈的压栈和出栈过程。首先按照顺序将数据1、2、3压入堆栈,然后弹出: ![考察数据结构——第二部分:队列、堆栈和哈希表[译]_第3张图片](http://img.e-com-net.com/image/info5/287ee5619bbd4f31990e4d98eed33eba.gif) 图五:向堆栈压入三个元素
图五:向堆栈压入三个元素  图六:弹出所有元素后的Stack
图六:弹出所有元素后的Stack
注意Stack类的缺省容量是10个元素,而非Queue的32个元素。和Queue和ArrayList一样,Stack的容量也可以根据构造函数定制。如同ArrayList,Stack的容量也是自动成倍增长。(回忆一下:Queue可以根据构造函数的可选项设置增长因子。)
注:Stack通常被称为“LIFO先进后出”或“LIFO后进先出”数据结构。 堆栈:计算机科学中常见的隐喻 现实生活中有很多同Queue相似的例子:DMV(译注:不知道其缩写,恕我孤陋寡闻,不知其意)、打印任务处理等。然而在现实生活很难找到和Stack近似的范例,但它在各种应用程序中却是一种非常重要的数据结构。
设想一下我们用以编程的计算机语言,例如:C#。当执行C#程序时,CLR(公共语言运行时)将调用Stack以跟踪功能模块(译注:这里原文为function,我理解作者的含义不仅仅代表函数,事实上很多编译器都会调用堆栈以确定其地址)的执行情况。每当调用一个功能模块,相关信息就会压入堆栈。调用结束则弹出堆栈。堆栈顶端数据为当前调用功能的信息。(如要查看功能调用堆栈的执行情况,可以在Visual Studio.Net下创建一个项目,设置断点(breakpoint),在执行调试。当执行到断点时,会在调试窗口(Debug/Windows/Call Stack)下显示堆栈信息。
序数索引的限制
我们在第一部分中讲到数组的特点是同种类型数据的集合,并通过序数进行索引。即:访问第i个元素的时间为定值。(请记住此种定量时间被标记为O(1)。)
也许我们并没有意识到,其实我们对有序数据总是“情有独钟”。例如员工数据库。每个员工以社保号(social security number)为其唯一标识。社保号的格式为DDD-DD-DDDD(D的范围为数字0——9)。如果我们有一个随机排列存储所有员工信息的数组,要查找社保号为111-22-3333的员工,可能会遍历数组的所有元素——即执行O(n)次操作。更好的办法是根据社保号进行排序,可将其查找时间缩减为O(log n)。
理想状态下,我们更愿意执行O(1)次时间就能查找到某员工的信息。一种方案是建立一个巨型的数组,以实际的社保号值为其入口。这样数组的起止点为000-00-0000到999-99-9999,如下图所示: ![考察数据结构——第二部分:队列、堆栈和哈希表[译]_第4张图片](http://img.e-com-net.com/image/info5/8380a827c4e145db81e31c589a21b002.gif) 图七:存储所有9位数数字的巨型数组
图七:存储所有9位数数字的巨型数组
如图所示,每个员工的信息都包括姓名、电话、薪水等,并以其社保号为索引。在这种方式下,访问任意一个员工信息的时间均为定值。这种方案的缺点就是空间极度的浪费——共有109,即10亿个不同的社保号。如果公司只有1000名员工,那么这个数组只利用了0.0001%的空间。(换个角度来看,如果你要让这个数组充分利用,也许你的公司不得不雇佣全世界人口的六分之一。)
用哈希函数压缩序数索引
显而易见,创建10亿个元素数组来存储1000名员工的信息是无法接受的。然而我们又迫切需要提高数据访问速度以达到一个常量时间。一种选择是使用员工社保号的最后四位来减少社保号的跨度。这样一来,数组的跨度只需要从0000到9999。图八显示了压缩后的数组。 ![考察数据结构——第二部分:队列、堆栈和哈希表[译]_第5张图片](http://img.e-com-net.com/image/info5/2145b6fa746c4dd7a895b136c39b8c52.gif) 图八:压缩后的数组
图八:压缩后的数组
此方案既保证了访问耗时为常量值,又充分利用了存储空间。选择社保号的后四位是随机的,我们也可以任意的使用中间四位,或者选择第1、3、8、9位。
在数学上将这种9位数转换为4位数成为哈希转换(hashing)。哈希转换可以将一个索引器空间(indexers space)转换为哈希表(hash table)。
哈希函数实现哈希转换。以社保号的例子来说,哈希函数H()表示为: H(x) = x 的后四位
哈希函数的输入可以是任意的九位社保号,而结果则是社保号的后四位数字。数学术语中,这种将九位数转换为四位数的方法称为哈希元素映射,如图九所示: ![考察数据结构——第二部分:队列、堆栈和哈希表[译]_第6张图片](http://img.e-com-net.com/image/info5/a431c4e3816348ad8e27de5517269147.gif) 图九:哈希函数图示
图九:哈希函数图示
图九阐明了在哈希函数中会出现的一种行为——冲突(collisions)。即我们将一个相对大的集合的元素映射到相对小的集中时时,可能会出现相同的值。例如社保号中所有后四位为0000的均被映射为0000。那么000-99-0000,113-14-0000,933-66-0000,还有其他的很多都将是0000。
看看之前的例子,如果我们要添加一个社保号为123-00-0191的新员工,会发生什么情况?显然试图添加该员工会发生冲突,因为在0191位置上已经存在一个员工。
数学标注:哈希函数在数学术语上更多地被描述为f:A->B。其中|A|>|B|,函数f不是一一映射关系,所以之间会有冲突。
显然冲突的发生会产生一些问题。在下一节,我们会看看哈希函数与冲突发生之间的关系,然后简单地犯下处理冲突的几种机制。接下来,我们会将注意力放在System.Collection.Hashtable类,并提供一个哈希表的实现。我们会了解有关Hashtable类的哈希函数,冲突解决机制,以及一些使用Hashtable的例子。
避免和解决冲突
当我们添加数据到哈希表中,冲突是导致整个操作被破坏的一个因素。如果没有冲突,则插入元素操作成功,如果发生了冲突,就需要判断发生的原因。由于冲突产生提高了代价,我们的目标就是要尽可能将冲突压至最低。
哈希函数中冲突发生的频率与传递到哈希函数中的数据分布有关。在我们的例子中,假定社保号是随机分配的,那么使用最后四位数字是一个不错的选择。但如果社保号是以员工的出生年份或出生地址来分配,因为员工的出生年份和地址显然都不是均匀分配的,那么选用后四位数就会因为大量的重复而导致更大的冲突。
注:对于哈希函数值的分析需要具备一定的统计学知识,这超出了本文讨论的范围。必要地,我们可以使用K维(k slots)的哈希表来保证避免冲突,它可以将一个随机值从哈希函数的域中映射到任意一个特定元素,并限定在1/k的范围内。(如果这让你更加的糊涂,千万别担心!)
我们将选择合适的哈希函数的方法成为冲突避免机制(collision avoidance),已有许多研究设计这一领域,因为哈希函数的选择直接影响了哈希表的整体性能。在下一节,我们会介绍在.Net Framework的Hashtable类中对哈希函数的使用。
有很多方法处理冲突问题。最直接的方法,我们称为“冲突解决机制”(collision resolution),是将要插入到哈希表中的对象放到另外一块空间中,因为实际的空间已经被占用了。其中一种最简单的方法称为“线性挖掘”(linear probing),实现步骤如下: 1. 当要插入一个新的元素时,用哈希函数在哈希表中定位; 2. 检查表中该位置是否已经存在元素,如果该位置内容为空,则插入并返回,否则转向步骤3。 3. 如果该地址为i,则检查i+1是否为空,如果已被占用,则检查i+2,依此类推,知道找到一个内容为空的位置。
例如:如果我们要将五个员工的信息插入到哈希表中:Alice(333-33-1234),Bob(444-44-1234), Cal (555-55-1237), Danny (000-00-1235), and Edward (111-00-1235)。当添加完信息后,如图十所示: ![考察数据结构——第二部分:队列、堆栈和哈希表[译]_第7张图片](http://img.e-com-net.com/image/info5/3a500b9a69174538bd1200138293d048.gif) 图十:有相似社保号的五位员工
图十:有相似社保号的五位员工
Alice的社保号被“哈希(这里做动词用,译注)”为1234,因此存放位置为1234。接下来来,Bob的社保号也被“哈希”为1234,但由于位置1234处已经存在Alice的信息,所以Bob的信息就被放到下一个位置——1235。之后,添加Cal,哈希值为1237,1237位置为空,所以Cal就放到1237处。下一个是Danny,哈希值为1235。1235已被占用,则检查1236位置是否为空。既然为空,Danny就被放到那儿。最后,添加Edward的信息。同样他的哈希好为1235。1235已被占用,检查1236,也被占用了,再检查1237,直到检查到1238时,该位置为空,于是Edward被放到了1238位置。
搜索哈希表时,冲突仍然存在。例如,如上所示的哈希表,我们要访问Edward的信息。因此我们将Edward的社保号111-00-1235哈希为1235,并开始搜索。然而我们在1235位置找到的是Bob,而非Edward。所以我们再搜索1236,找到的却是Danny。我们的线性搜索继续查找知道找到Edward或找到内容为空的位置。结果我们可能会得出结果是社保号为111-00-1235的员工并不存在。
线性挖掘虽然简单,但并是解决冲突的好的策略,因为它会导致同类聚合(clustering)。如果我们要添加10个员工,他们的社保号后四位均为3344。那么有10个连续空间,从3344到3353均被占用。查找这10个员工中的任一员工都要搜索这一簇位置空间。而且,添加任何一个哈希值在3344到3353范围内的员工都将增加这一簇空间的长度。要快速查询,我们应该让数据均匀分布,而不是集中某几个地方形成一簇。
更好的挖掘技术是“二次挖掘”(quadratic probing),每次检查位置空间的步长以平方倍增加。也就是说,如果位置s被占用,则首先检查s+12处,然后检查s-12,s+22,s-22,s+32 依此类推,而不是象线性挖掘那样从s+1,s+2……线性增长。当然二次挖掘同样会导致同类聚合。
下一节我们将介绍第三种冲突解决机制——二度哈希,它被应用在.Net Framework的哈希表类中。
System.Collections.Hashtable 类 .Net Framework 基类库包括了Hashtable类的实现。当我们要添加元素到哈希表中时,我们不仅要提供元素(item),还要为该元素提供关键字(key)。Key和item可以是任意类型。在员工例子中,key为员工的社保号,item则通过Add()方法被添加到哈希表中。
要获得哈希表中的元素(item),你可以通过key作为索引访问,就象在数组中用序数作为索引那样。下面的C#小程序演示了这一概念。它以字符串值作为key添加了一些元素到哈希表中。并通过key访问特定的元素。
using System; using System.Collections;
public class HashtableDemo { private static Hashtable ages = new Hashtable();
public static void Main() { // Add some values to the Hashtable, indexed by a string key ages.Add("Scott", 25); ages.Add("Sam", 6); ages.Add("Jisun", 25); // Access a particular key if (ages.ContainsKey("Scott")) { int scottsAge = (int) ages["Scott"]; Console.WriteLine("Scott is " + scottsAge.ToString()); } else Console.WriteLine("Scott is not in the hash table..."); } } 程序中的ContainsKey()方法,是根据特定的key判断是否存在符合条件的元素,返回布尔值。Hashtable类中包含keys属性(property),返回哈希表中使用的所有关键字的集合。这个属性可以通过遍历访问,如下:
// Step through all items in the Hashtable foreach(string key in ages.Keys) Console.WriteLine("Value at ages[/"" + key + "/"] = " + ages[key].ToString());
要认识到插入元素的顺序和关键字集合中key的顺序并不一定相同。关键字集合是以存储的关键字对应的元素为基础,上面的程序的运行结果是:
Value at ages["Jisun"] = 25 Value at ages["Scott"] = 25 Value at ages["Sam"] = 6
即使插入到哈希表中的顺序是:Scott,Sam, Jisun。
Hashtable类的哈希函数
Hashtable类中的哈希函数比我们前面介绍的社保号的哈希值更加复杂。首先,要记住的是哈希函数返回的值是序数。对于社保号的例子来说很容易办到,因为社保号本身就是数字。我们只需要截取其最后四位数,就可以得到合适的哈希值。然而Hashtable类中可以接受任何类型的值作为key。就象上面的例子,key是字符串类型,如“Scott”或“Sam”。在这样一个例子中,我们自然想明白哈希函数是怎样将string转换为数字的。
这种奇妙的转换应该归功于GetHashCode()方法,它定义在System.Object类中。Object类中GetHashCode()默认的实现是返回一个唯一的整数值以保证在object的生命期中不被修改。既然每种类型都是直接或间接从Object派生的,因此所以object都可以访问该方法。自然,字符串或其他类型都能以唯一的数字值来表示。
Hashtable类中的对于哈希函数的定义如下:
H(key) = [GetHash(key) + 1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1))] % hashsize
这里的GetHash(key),默认为对key调用GetHashCode()方法的返回值(虽然在使用Hashtable时,你可以自定义GetHash()函数)。GetHash(key)>>5表示将得到key的哈希值,向右移动5位,相当于将哈希值除以32。%操作符就是之前介绍的求模运算符。Hashsize指的是哈希表的长度。因为要进行求模,因此最后的结果H(k)在0到hashsize-1之间。既然hashsize为哈希表的长度,因此结果总是在可以接受的范围内。
Hashtable类中的冲突解决方案
当我们在哈希表中添加或获取一个元素时,会发生冲突。插入元素时,必须查找内容为空的位置,而获取元素时,即使不在预期的位置处,也必须找到该元素。前面我们简单地介绍了两种解决冲突的机制——线性和二次挖掘。在Hashtable类中使用的是一种完全不同的技术,成为二度哈希(rehasing)(有的资料也将其称为双精度哈希double hashing)。
二度哈希的工作原理如下:有一个包含多个哈希函数(H1……Hn)的集合。当我们要从哈希表中添加或获取元素时,首先使用哈希函数H1。如果导致冲突,则尝试使用H2,一直到Hn。各个哈希函数极其相似,不同的是它们选用的乘法因子。通常,哈希函数Hk的定义如下: Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1)))] % hashsize
注:运用二度哈希重要的是在执行了hashsize次挖掘后,哈希表中的每一个位置都确切地被有且仅有一次访问。也就是说,对于给定的key,对哈希表中的同一位置不会同时使用Hi和Hj。在Hashtable类中使用二度哈希公式,其保证为:(1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1))与hashsize两者互为素数。(两数互为素数表示两者没有共同的质因子。)如果hashsize是一个素数,则保证这两个数互为素数。
二度哈希较前两种机制较好地避免了冲突。
调用因子(load factors)和扩充哈希表
Hashtable类中包含一个私有成员变量loadFactor,它指定了哈希表中元素个数与表位置总数之间的最大比例。例如:loadFactor等于0.5,则说明哈希表中只有一半的空间存放了元素值,其余一半皆为空。
哈希表的构造函数以重载的方式,允许用户指定loadFactor值,定义范围为0.1到1.0。要注意的是,不管你提供的值是多少,范围都不超过72%。即使你传递的值为1.0,Hashtable类的loadFactor值还是0.72。微软认为loadFactor的最佳值为0.72,因此虽然默认的loadFactor为1.0,但系统内部却自动地将其改变为0.72。所以,建议你使用缺省值1.0(事实上是0.72,有些迷惑,不是吗?)
注:我花了好几天时间去咨询微软的开发人员为什么要使用自动转换?我弄不明白,为什么他们不直接规定值为0.072到0.72之间。最后我从编写Hashtable类的开发团队的到了答案,他们非常将问题的缘由公诸于众。事实上,这个团队经过测试发现如果loadFactor超过了0.72,将会严重的影响哈希表的性能。他们希望开发人员能够更好地使用哈希表,但却可能记不住0.72这个无规律数,相反如果规定1.0为最佳值,开发者会更容易记住。于是,就形成现在的结果,虽然在功能上有少许牺牲,但却使我们能更加方便地使用数据结构,而不用感到头疼。
向Hashtable类添加新元素时,都要进行检查以保证元素与空间大小的比例不会超过最大比例。如果超过了,哈希表空间将被扩充。步骤如下: 1. 哈希表的位置空间近似地成倍增加。准确地说,位置空间值从当前的素数值增加到下一个最大的素数值。(回想一下前面讲到的二度哈希的工作原理,哈希表的位置空间值必须是素数。) 2. 既然二度哈希时,哈希表中的所有元素值将依赖于哈希表的位置空间值,所以表中所有值也需要二度哈希(因为在第一步中位置空间值增加了)。
幸运的是,Hashtable类中的Add()方法隐藏了这些复杂的步骤,你不需要关心它的实现细节。
调用因子(load factor)对冲突的影响决定于哈希表的总体长度和进行挖掘操作的次数。Load factor越大,哈希表越密集,空间就越少,比较于相对稀疏的哈希表,进行挖掘操作的次数就越多。如果不作精确地分析,当冲突发生时挖掘操作的预期次数大约为1/(1-lf),这里lf指的是load factor。
如前所述,微软将哈希表的缺省调用因子设定为0.72。因此对于每次冲突,平均挖掘次数为3.5次。既然该数字与哈希表中实际元素个数无关,因此哈希表的渐进访问时间为O(1),显然远远好于数组的O(n)。
最后,我们要认识到对哈希表的扩充将以性能损耗为代价。因此,你应该预先估计你的哈希表中最后可能会容纳的元素总数,在初始化哈希表时以合适的值进行构造,以避免不必要的扩充。