python 抓取网页
1. 主要内容
此部分的主要内容包括:
抓取网页的的基本方法。
使用urllib和urllib2库。
可以使用参数编码。
2. 代码举例
2.1 基本的抓取
使用sudo python命令,进入python环境。在此之前可以自己搭一个web服务器,专门做测试用。我在我的一个Ubuntu系统中搭建了LNMP环境,地址为192.168.1.33。
其实python代码很简洁,抓取一个网页只需要两行代码:
pyhon
import urllib
httpResponse = urllib.urlopen("http://192.168.1.33")
运行玩这两行代码后,可以通过httpResponse.code查看响应状态,httpResponse.read()显示返回的内容。

通过dir()函数可以进一步查看httpResponse内部的内容。
>>>
>>> dir(httpResponse)
[‘doc‘, ‘init‘, ‘iter‘, ‘module‘, ‘repr‘, ‘close’, ‘code’, ‘fileno’, ‘fp’, ‘getcode’, ‘geturl’, ‘headers’, ‘info’, ‘next’, ‘read’, ‘readline’, ‘readlines’, ‘url’]
>>>
>>> httpResponse.url
‘http://192.168.1.33’
>>> dir(httpResponse.headers)
[‘contains‘, ‘delitem‘, ‘doc‘, ‘getitem‘, ‘init‘, ‘iter‘, ‘len‘, ‘module‘, ‘setitem‘, ‘str‘, ‘addcontinue’, ‘addheader’, ‘dict’, ‘encodingheader’, ‘fp’, ‘get’, ‘getaddr’, ‘getaddrlist’, ‘getallmatchingheaders’, ‘getdate’, ‘getdate_tz’, ‘getencoding’, ‘getfirstmatchingheader’, ‘getheader’, ‘getheaders’, ‘getmaintype’, ‘getparam’, ‘getparamnames’, ‘getplist’, ‘getrawheader’, ‘getsubtype’, ‘gettype’, ‘has_key’, ‘headers’, ‘iscomment’, ‘isheader’, ‘islast’, ‘items’, ‘keys’, ‘maintype’, ‘parseplist’, ‘parsetype’, ‘plist’, ‘plisttext’, ‘readheaders’, ‘rewindbody’, ‘seekable’, ‘setdefault’, ‘startofbody’, ‘startofheaders’, ‘status’, ‘subtype’, ‘type’, ‘typeheader’, ‘unixfrom’, ‘values’]
>>> httpResponse.headers.items()
[(‘content-length’, ‘151’), (‘accept-ranges’, ‘bytes’), (‘server’, ‘nginx/1.1.19’), (‘last-modified’, ‘Mon, 04 Oct 2004 15:04:06 GMT’), (‘connection’, ‘close’), (‘date’, ‘Thu, 18 Jun 2015 12:30:19 GMT’), (‘content-type’, ‘text/html’)]
>>>
我们通过一段循环程序将httpResponse的头部内容打印出来:
for header,value in httpResponse.headers.items():
print header + ' : ' + value
从Server字段,我们可以看到服务器端运行的时Nginx,版本信息为1.1.19。
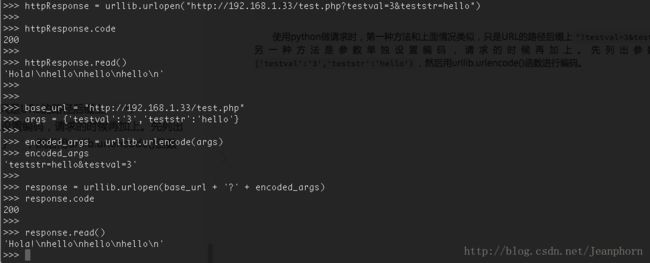
2.2 带参数URL请求
很多情况下,网页是要和用户交互的。即请求的路径中会包含一些参数,例如用户登录时会有用户名和密码,翻页时会有页面数,搜索时会有关键词等。而用户的HTTP请求主要有两种方式:POST和GET。现以GET为例说明一下,带参数时url请求格式及语法。
为了测试方便,我写了一个php小程序放在Nginx服务器上。
<?php
$output = "Hola!\n";
if (isset($_GET['testval']) &&
isset($_GET['teststr']) &&
is_numeric($_GET['testval']))
{
for ($i = 0; $i < $_GET['testval']; ++$i)
{
$output .= $_GET['teststr'] . "\n";
}
}
echo $output;
?> 使用python做请求时,第一种方法和上面情况类似,只是URL的路径后缀上"?testval=3&teststr=hello"。另一种方法是参数单独设置编码,请求的时候再加上。先列出参数来args = {'testval':'3','teststr':'hello'},然后用urllib.urlencode()函数进行编码。