C66x定点浮点混合DSP循环编程优化指南
C66x DSP是TI最新出的定点和浮点混合DSP,后向兼容C64x+和C67x+、C674x系列DSP。本文介绍了基于C66x架构的常用优化技巧,首先介绍C66x相对于C64x+定点DSP的浮点和定点处理能力的增强,以及C66x新引入的128-bit的数据类型。接下来说明c66x特有的特性和相关的优化技术,重点在其浮点增强以及对复数运算和矩阵、向量运算的intrinsics选择,最后是如何解决寄存器不足、SIMD move的使用平衡寄存器和功能单元的分配以及解决寄存器生命周期过长的问题的高级优化技巧。本文中的编译结果基于CCSv4.1中的CGTools v7.2编译器,编译选项–o3 –s –mw –mv6600。
C66x DSP简介
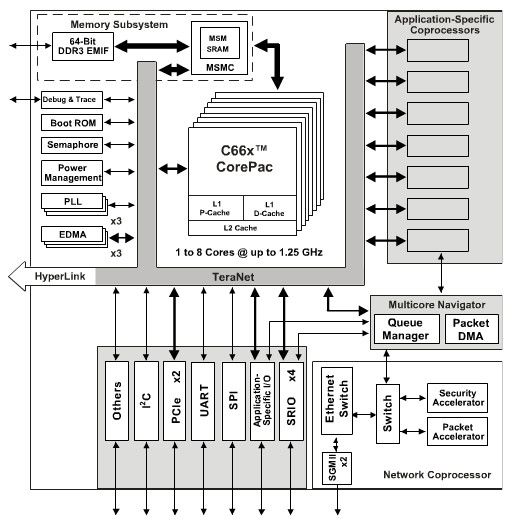
图1. KeyStone C66x DSP框架图
C66x DSP是TI最新出的定点和浮点混合DSP,后向兼容C64x+和C67x+、C674x系列DSP。最高主频到1.25GHz,RSA指令集扩展。每个核有32KB的L1P和32KB的L1D,512KB到1MB L2存储区,2MB~4MB的多核共享存储区MSM,多核共享存储控制器MSMC能有效的管理核间内存和数据一致性。针对通信应用,其片内集成了2个TCP3d Turbo码字译码器,一个TCP3e Turbo码编码器,2个FFT/IFFT,DFT/IDFT协处理器以及4个VCP2 Viterbi译码器。高速互联总线,4个串行RapidIO接口,千兆网口、EMIF-DDR3内存控制器。TeraNet Switch用于片内和外设间的快速交互。
C66x DSP的架构和指令增强
TMS320C66x ISA架构是对TMS320C674x DSP的增强,也是基于增强VLIW架构的,具有8个功能单元(2个乘法器,6个ALU算术运算单元),该架构的基本增强如下:
- 4倍的乘累加能力, 每个周期32个 (16x16-bit)或者8个单精度浮点乘法;
- 浮点运算的增强:优化了将TMS320C67x +和TMS320C64x+ DSP 结合的TMS320C674x DSP,原生支持IEEE 754单精度和双精度浮点运算,包括所有的浮点操作,加减乘除;浮点运算的SIMD支持以及单精度复数乘法,附加的灵活性,如在.L和.S单元完成INT到单精度SP的相互转换
- 浮点和定点向量处理能力的增强: TMS320C64x+/C674x DSPs支持2-way的16-bit数据SIMD或者4-way的8-bit,C66x增加了SIMD的宽度,增加了128-bit的向量运算。如QMPY32能做2个包含4x32-bit向量的乘法。另外SIMD的处理能力也得到增强;
- 复数和矩阵运算的引入和增强:针对通信信号处理中的常用复数算术函数和如矩阵运算的线性算法的应用,如单周期可以完成两个[1×2]复数向量和[2×2]的矩阵乘法
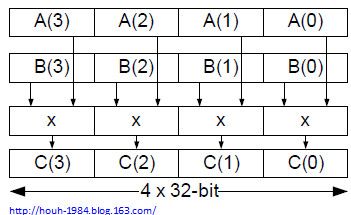
图2. QMPY32的向量操作
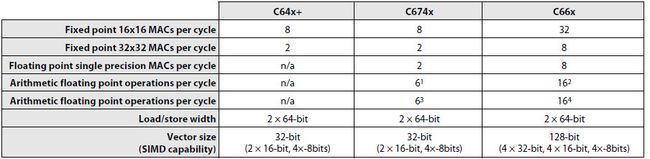
图2. C64x+/C674x/C66x ISA定点和浮点处理能力对比
128-bit数据类型
__x128_t是一个保存128-bit的数据类型的容器,用于C6600的SIMD处理。当使用__x128_t容器时,需要包含头文件c6x.h并且通过编译选项-mv6600使能针对C6600平台的编译。这个类型可以用于定义针对特定C6600的intrinsics。当使用_x128_t对象时,一个__x128_t占4个寄存器,如果在内存则对齐在128-bit边界。
? 定义一个__x128_t全局对象,(e.g. __x128_t a;),默认放在.far段。
? 定义一个__x128_t局部变量,(e.g. __x128_t a;),放在堆栈
? 定义一个__x128_t global/local指针 (e.g. __x128_t *a;)
? 定义一个__x128_t数组 (e.g. __x128_t a[10];)
? 定义一个结构体,联合体、类包含一个__x128_t类型对象
? __x128_t对象赋值给另外一个__x128_t对象
? 传递一个__x128_t对象给函数入口参数,通过值传递
? 函数返回一个__x128_t对象
? 使用128-bit处理的intrinsics来设置或者摘取内容。
而像针对__x128_t对象的原生+, -, *操作是不允许的,也不能进行类型转换,也不能把__x128_t对象传递给像printf 的I/O函数,而应该摘取元素输出。
C66x DSP的浮点运算和向量、复数、矩阵运算的优化
本节考虑C66x的一些特殊的地方,如浮点运算和向量、矩阵运算的优化。针对浮点运算,可以考虑如下:什么时候决定采用浮点(高精度,高动态范围),消除因为定点实现引入的缩放和舍入运算,使用浮点独有的求倒数和求平方根的倒数的指令、快速的进行浮点和定点数据类型转换的指令等。而对于向量和复数矩阵运算,则考虑更为有效的复数操作指令,向量和矩阵运算的独特指令。
浮点操作
C66x的浮点支持可以原生的运行很多的浮点算法,即便是从Matlab或者C代码刚刚转换的算法,就可以评估性能和算法精度。本节主要以单精度浮点为例,虽然C66x可以很好的支持双精度浮点的运行。
使用C66x的浮点操作有以下好处,由于不用考虑精度和数据范围权衡而进行的定点数据Q定标和数据转换,因而在通用C和MatlAB上验证的算法可以直接在C66x的DSP上实现。浮点处理还能从减少的缩放和Q值调整带来的cycle减少,浮点操作还提供快速的出发和求平方根的指令,单精度浮点处理能带来很高的动态范围和固定的24-bit精度,和32-bit定点相比更节省功耗。而快速的数据格式转换指令更能有效的处理定点和浮点混合的代码,带来更多的便利性。
C66x的浮点算术运算包括如下:
? 每个周期内和C64x+核相同数量的单精度浮点操作,即8个,CMPYSP 和 QMPYSP在一个周期能处理4个单精度乘法。每个周期8个定点乘法操作,4倍于C64x+核;
? 加减操作,每个周期8个单精度加减操作,DADDSP和DSUBSP能处理2个浮点加减,而且可以在.L 和 .S功能单元上执行。
? 浮点和整型的转换:8个单精度到整数,8个整数到单精度浮点转换,DSPINT, DSPINTH, DINTHSP, 和DSPINTH能转换2个浮点到整型,可以在.L 和 .S功能单元上执行
? 除法:每个周期2个倒数 1/x 和平方根的倒数1/sqrt(x),为了获取更高的精度可以采用如牛顿-拉夫森等迭代算法。
一下是一个求解复数数据的幅度和相位的函数
void example1_gc(cplxf_t *a, cplxf_t *ejalpha, float *abs_a, int n)
{
int i;
float a_sqr, oneOverAbs_a;
for ( i = 0; i < n; i++)
{
a_sqr =a[i].real * a[i].real + a[i].imag * a[i].imag;
oneOverAbs_a =1.f/(float)sqrt(a_sqr);
abs_a[i] = a_sqr * oneOverAbs_a;
ejalpha[i].real =a[i].real * oneOverAbs_a;
ejalpha[i].imag =a[i].imag * oneOverAbs_a;
}
}
输入的测试序列使用rand()函数产生实部和虚部,然后减去0x4000来让随机数据在[-16384 16383]范围内,对于C66x,直接通用C的API。另外本例中采用C64x+的代码实现来做对比。对于定点代码需要把输入数据转换为定点的16-bit的I/Q格式,相位用Q15格式表示。本例中的编译环境CCSv4.1.0,编译器Compiler 7.2.0A10232,使用Nyquist Device Cycle Approximate Simulator, Little Endian的编译和运行方式,对Big Endian也类似。
如果直接用上述的浮点代码进行编译执行,会发现C64x+平台需要473483个周期,而C66x 平台需要 69644个周期,这主要因为对于两个平台而言以上循环都没法进行软件流水因为循环体内有函数调用,对于C64x+而言,不仅1/sqrt(x)函数需要调用math函数,所有的浮点运行也是需要调用定点模拟的函数实现的。对于C66x平台而言,只有1/sqrt(x)函数需要调用math函数,这也就是为什么会有6.8x的性能提升。这个提升也很好的作为验证算法的准确性。
考虑C64x+平台的优化
优化点包括:
? 快速计算1/sqrt(x)的函数,需要inline的函数:可以考虑使用分段查找表来计算该函数,或者采用查表和其他的迭代算法结合的方法;
? 考虑适当的scale缩放和Q值调整;
? 考虑更高位宽的数据读写;
? 考虑定点的复数乘法SIMD指令
_nassert((int) a % 8 == 0);
_nassert((int) ejalpha % 8 == 0);
_nassert((int) abs_a % 8 == 0);
#pragma MUST_ITERATE(4,100, 4);
#pragma UNROLL(2);
for ( i = 0; i < n; i++)
{
temp1 = _amem4(&a[i]);
a_sqr = _dotp2(temp1, temp1);
/* 1/sqrt(a_sqr) */
normal = _norm(a_sqr);
normal = normal & 0xFFFFFFFE;
x_norm = _sshvl(a_sqr, normal);
normal = normal >> 1;
Index = _sshvr(_sadd(x_norm,0x800000),24);
oneOverAbs_a=_mpylir( xcbia[Index], x_norm );
oneOverAbs_a=_sadd((int)x3sa[Index]<<16,
_sshvr(oneOverAbs_a,ShiftValDifp1a[Index]));
normal =15 - ShiftVala[Index] + normal;
ejbeta_re =_sadd(_sshvl(_mpyhir(temp1, oneOverAbs_a), normal - 1), 0x8000);
ejbeta_im =_sadd(_sshvl(_mpylir(temp1, oneOverAbs_a), normal - 1), 0x8000);
_amem4(&ejalpha[i])= _packh2(ejbeta_re, ejbeta_im);
abs_a[i] = sshvr(_sadd(_mpyhir(oneOverAbs_a, a_sqr), 1<<(15 - normal)),16-normal) ;
}
警告编译器的优化得到的循环迭代信息如下
;* SOFTWARE PIPELINE INFORMATION
;*
;* Loop source line : 198
;* Loop opening brace source line : 199
;* Loop closing brace source line : 218
;* Loop Unroll Multiple : 2x
;* Known Minimum Trip Count : 2
;* Known Maximum Trip Count : 50
;* Known Max Trip Count Factor : 2
;* Loop Carried Dependency Bound(^) : 0
;* Unpartitioned Resource Bound : 9
;* Partitioned Resource Bound(*) : 9
;* Resource Partition:
;* A-side B-side
;* .L units 1 1
;* .S units 6 6
;* .D units 7 6
;* .M units 9* 9*
;* .X cross paths 5 1
;* .T address paths 7 6
;* Long read paths 0 0
;* Long write paths 0 0
;* Logical ops (.LS) 8 7 (.L or .S unit)
;* Addition ops (.LSD) 5 7 (.L or .S or .D unit)
;* Bound(.L .S .LS) 8 7
;* Bound(.L .S .D .LS .LSD) 9* 9*
;*
;* Searching for software pipeline schedule at ...
;* ii = 9 Register is live too long
;* ii = 9 Did not find schedule
;* ii = 10 Register is live too long
;* ii = 10 Register is live too long
;* ii = 10 Did not find schedule
;* ii = 11 Schedule found with 5 iterations in parallel
;* Done
以上处理中1/sqrt(x)被inline到循环内,_nassert(), restrict关键字以及#pragmas来告诉编译器尽可能多的关于buffer重叠、数据对其、循环次数和unroll信息。采用_amem4()来进行数据读写,使用 MPYLIR和MPYHIR左16-bit乘以32-bit,使用DOTP2计算16-bit复数的能量。其他的还有round和scale的操作来做Q值调整。现在100个数据的求解幅值和相位仅需要746个周期。
考虑C66x平台的优化
针对C66x平台,有单独的指令RSQRSP来计算1/sqrt(x),复数的乘法和浮点的运算以及定点和浮点的转换还可以考虑并行的SIMD指令。C66x提供了单周期的指令RSQRSP 来计算 1/sqrt(x),RCPSP来计算1/x。另外就是采用编译器友好的关键字_nassert()和restrict以及#pragmas来告诉编译器尽可能多的关于buffer重叠、数据对其、循环次数和unroll信息,另外就是RSQRSP和RCPSP以及双精度格式的RSQRDP、RCPDP能得到正确的指数exponent值和只有8比特精度的尾数mantissa值,因而要更精确的值,需要一些迭代算法,如Newton-Raphson迭代公式x[n+1]=x[n]*(2 - v *x[n]) 来计算倒数,用x[n+1]= x[n]*(1.5 - (v/2)*x[n]*x[n])迭代来计算1/sqrt(v)。多一次迭代多8比特精度,两次迭代24比特尾数精度,3次迭代32比特精度。同时这种实现也不需要查找表了。
_nassert((int) a % 8 == 0);
_nassert((int) ejalpha % 8 == 0);
_nassert((int) abs_a % 8 == 0);
#pragma MUST_ITERATE(4,100, 4);
#pragma UNROLL(2);
for ( i = 0; i < n; i++)
{
a_sqr = a[i].real * a[i].real + a[i].imag * a[i].imag;
oneOverAbs_a = _rsqrsp(a_sqr); /* 1/sqrt() instruction 8-bit mantissa
precision*/
/* One interpolation*/
oneOverAbs_a = oneOverAbs_a * (1.5f - (a_sqr/2.f)* oneOverAbs_a
*oneOverAbs_a);
abs_a[i]= a_sqr * oneOverAbs_a;
ejalpha[i].real =a[i].real * oneOverAbs_a;
ejalpha[i].imag =a[i].imag * oneOverAbs_a;
}
该循环只需要496个周期,而且不用额外的存储查找表。
继续C66x平台的优化
C66x有更强的SIMD处理能力,进一步的优化可以考虑浮点乘法、数据加载等。如数据加载采用_amem8(addr)来加载8字节对齐的整型数据,_amemd8(addr) 来加载8字节对齐的浮点数据。因而定义如下的复数数据结构,就能用_amemd8(addr)一次加载一个复数的实部和虚部了,注意一下定义同时考虑了大小端,保证加载的高4字节是虚步,低4字节是实部。
#ifdef _LITTLE_ENDIAN
typedef struct _CPLXF
{
float imag;
float real;
} cplxf_t;
#else
typedef struct _CPLXF
{
float real;
float imag;
} cplxf_t;
#endif
对于加载的寄存器对的数据,可以采用_hif(src)来得到实部,用_lof(src)来得到虚部,类似于C64x+中的_hill(src) 和 _loll(src)。组成一个寄存器对,可以采用类似_itoll(srcq, src2) 的_fod(src1, scr2).
C66x处理器除了提供C674x+ DSP已经包含的MPYSP (SPxSP->SP), MPYDP (DPxDP->DP), MPYSPDP(SPxDP->DP), 以及MPYSP2DP (SPxSP->DP)外,还有新的DMPYSP以及CMPYSP和QMPYSP指令。
? DMPYSP:浮点的C[i] = A[i] * B[i] for i=0 to 1
? CMPYSP: 用于浮点数据的复数乘法,结果为128-bit格式
C3 = A[1] * B[1]
C2 = A[1] * B[0]
C1 = -A[0] * B[0]
C0 = A[0] * B[1]
为得到复数的实部和虚部,定义128-bit的数据C:
__x128_t C_128;
C_128 = _cmpysp(A, B);
C = _daddsp(_hid128(C_128), _lod128(C_128)),直接得到C3+C1 和 C2+C0。
或者使用intrinsics _complex_mpysp():
C=_complex_mpysp(A, B)
得到A和B的共轭的乘积,考虑如下步骤:
__x128_t C_128;
C_128 = _cmpysp(B, A);
C3 = B[1] * A[1]
C2 = B[1] * A[0]
C1 = -B[0] * A[0]
C0 = B[0] * A[1]
C = _dsubsp(_hid128(C_128), _lod128(C_128)),,直接得到C3-C1 和 C2-C0;
或者采用简单的intrinsics _complex_conjugate_mpysp():
C=_complex_conjugate_mpysp(A, B)
? QMPYSP: C[i] = A[i] * B[i] for i=0 to 3.
使用SIMD修改的程序如下
_nassert(n % 4 == 0);
_nassert((int) a % 8 == 0);
_nassert((int) ejalpha % 8 == 0);
_nassert((int) abs_a % 8 == 0);
#pragma MUST_ITERATE(4,100, 4);
for ( i = 0; i < n; i++)
{
dtemp =_amemd8(&a[i]);
/* using SIMD CMPYSP with conjugation for power calculation */
a_sqr =_hif(_complex_conjugate_mpysp(dtemp, dtemp));
/* or use the following */
/* dtemp2 = _dmpysp(dtemp, dtemp); */
/* a_sqr = _hif(dtemp2) + _lof(dtemp2); */
oneOverAbs_a = _rsqrsp(a_sqr); /* 1/sqrt() instruction 8-bit mantissa precision*/
/* 1st interpolation*/
oneOverAbs_a = oneOverAbs_a * (1.5f - (a_sqr/2.f)* oneOverAbs_a*oneOverAbs_a);
abs_a[i] =a_sqr * oneOverAbs_a;
dtemp1 =_ftod(oneOverAbs_a, oneOverAbs_a);
/* using SIMD DMPYSP for the following operations */
/* ejalpha[i].real = a[i].real * oneOverAbs_a;*/
/* ejalpha[i].imag = a[i].imag * oneOverAbs_a;*/
_amemd8(&ejalpha[i]) = _dmpysp(dtemp, dtemp1);
}
_complex_conjugate_mpysp(a, a)计算能量,只保存32 MSB到寄存器,还可以通过DMPYSP(a, a) 和_hif() + _lof()来计算能量。
得到的结果是需要419个周期。
混合的定点和浮点代码
C66x使用如下指令进行浮点和定点的转换:
? DINTHSP, DINTHSPU, DSPINTH: 把一对的16-bit整数转换为一对单精度,带和不带符号扩展。
? DINTSP, DINTSPU, DSPINT: 把一对的32-bit整型转换为一对的单精度浮点,带和不带符号扩展。
for ( i = 0; i < n; i++)
{
temp = _amem4(&a[i]);
a_sqr =(float) ((int) _dotp2(temp, temp));
dtemp =_dinthsp(temp);
oneOverAbs_a =_rsqrsp(a_sqr);
/* 1st interpolation*/
oneOverAbs_a = oneOverAbs_a * (1.5f - (a_sqr/2.f)*
oneOverAbs_a *oneOverAbs_a);
abs_a[i] =(short)(a_sqr * oneOverAbs_a);
dtemp1 = _ftod(oneOverAbs_a, oneOverAbs_a);
dtemp1 = _dmpysp(dtemp, dtemp1);
dtemp1= _dmpysp(_ftod(32768.f, 32768.f), dtemp1);
_amem4(&ejalpha[i]) =_dspinth(dtemp1);
}
浮点转换成带Q值的16-bit定点的C代码
/ * strip sign */
sp = 0x7FFFFFFF & _ftoi(input);
/* shift the 23-bit mantissa to lower 16-bit */
temp = 0x04C00000 + (head<<23) + (sp & 0xFF800000);
magic = _itof(0x04C00000 + (head<<23) + (sp & 0xFF800000));
tempf = input + magic;
output = _ext(_ftoi(input + magic), 16, 16);
q = 15 + (127 + 8) - (_ftoi(magic) >> 23);
其中head是指headroom,即保留的整数位;
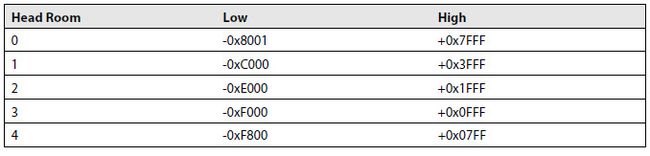
图3. 浮点转定点的动态范围
软件流水优化C66x循环的其他考虑
消除TMS320C66x寄存器不足的压力
尽量避免4-way的SIMD指令来减少寄存器压力,虽然SIMD能有更好的数据处理的并行,但很多SIMD的处理需要4个寄存器作为源和目的操作数,虽然C66x提供了64个寄存器(A侧和B侧各32个),但这种还是会带来寄存器压力的。寄存器不足的常见编译反馈信息如下
;* ii = 19 Cannot allocate machine registers
;* Regs Live Always : 12/10 (A/B-side)
;* Max Regs Live : 38/31
;* Max Cond Regs Live : 1/0
循环的软件流水给的资源约束在功能单元,但是迭代周期没法在相应的约束内完成,这种提示信息表明寄存器资源不足,因而可以考虑在SIMD指令使用的地方分析是否因为SIMD的引入增大了寄存器压力。因而一个原则是如果循环不被某种功能单元所约束,那么尽量别使用该功能单元的SIMD指令吧。
使用SIMD的move来实现资源平衡
C66x的SIMD move指令能在寄存器间转移数据,需要注意的是如_itoll, _ftod _ito128, _fto128, _dto128 和 _llto128在C66x上对应于非SIMD的move指令。使用这些intrinsic会导致循环对
.L, .S 和 .D单元的约束。因而可以考虑使用SIMD的move指令来代替这些intrinsics,如SIMD intrinsics _dmv(整型) _fdmv(双精度)。对于何时用SIMD的move指令,有如下参考建议:
? 使用SIMD move如果你需要赋值寄存器到寄存器对;
? 使用SIMD move如果你确定这些寄存器不会在接下来的指令中使用。
需要注意的是,SIMD的move会增加循环的动态长度。
尽可能避免通用的相同表达式,尤其对于__x128_t类型
对于TMS320C66x编译器而言,那些结果是__x128_t类型的表达式并不会归为相同的表达式,因而可能会重复计算。所以在使用__x128_t数据类型的intrinsic时,尽量吧相同的部分提取出来。如下所示。这种改变不会改变循环的功能功能,但是却能改变性能
void dprod_vcse(double *restrict inputPtr,double *restrict coefsPtr,int
nCoefs,double *restrict sumPtr, int nlength) {
int i, j;
double sumTemp = 0, sumTemp1 = 0, sumTemp2 = 0, sumTemp3 = 0;
for(i = 0; i<nlength/4; i++)
{
for (j = 0; j < nCoefs; j++)
{
sumTemp = _daddsp(sumTemp,_daddsp(_hid128(_cmpysp(inputPtr[i],coefsPtr[i])),_lod128(_cmpysp(inputPtr[i],coefsPtr[i]))));
sumTemp1 = _daddsp(sumTemp1,_daddsp(_hid128(_cmpysp(inputPtr[i+1],coefsPtr[i])),_lod128(_cmpysp(inputPtr[i+1],coefsPtr[i]))));
sumTemp2 = _daddsp(sumTemp2,_daddsp(_hid128(_cmpysp(inputPtr[i+2],coefsPtr[i])),_lod128(_cmpysp(inputPtr[i+2],coefsPtr[i]))));
sumTemp3 = _daddsp(sumTemp3,_daddsp(_hid128(_cmpysp(inputPtr[i+3],coefsPtr[i])),_lod128(_cmpysp(inputPtr[i+3],coefsPtr[i]))));
}
sumPtr[i] = sumTemp;
sumPtr[i+1] = sumTemp1;
sumPtr[i+2] = sumTemp2;
sumPtr[i+3] = sumTemp3;
}
}
修改为
void dprod_novcse(double *restrict inputPtr,double *restrict coefsPtr,int
nCoefs,double *restrict sumPtr, int nlength) {
int i, j;
double sumTemp = 0, sumTemp1 = 0, sumTemp2 = 0, sumTemp3 = 0;
__x128_t cmpysp_temp, cmpysp_temp1, cmpysp_temp2, cmpysp_temp3;
for(i = 0; i<nlength/4; i++)
{
for (j = 0; j < nCoefs; j++)
{
cmpysp_temp = _cmpysp(inputPtr[i],coefsPtr[i]);
sumTemp = _daddsp(sumTemp, _daddsp(_hid128(cmpysp_temp),
_lod128(cmpysp_temp)));
cmpysp_temp1 = _cmpysp(inputPtr[i+1],coefsPtr[i]);
sumTemp1 = _daddsp(sumTemp1, _daddsp(_hid128(cmpysp_temp1),
_lod128(cmpysp_temp1)));
cmpysp_temp2 = _cmpysp(inputPtr[i+2],coefsPtr[i]);
sumTemp2 = _daddsp(sumTemp2, _daddsp(_hid128(cmpysp_temp2),
_lod128(cmpysp_temp2)));
cmpysp_temp3 = _cmpysp(inputPtr[i+3],coefsPtr[i]);
sumTemp3 = _daddsp(sumTemp3, _daddsp(_hid128(cmpysp_temp3),
_lod128(cmpysp_temp3)));
}
sumPtr[i] = sumTemp;
sumPtr[i+1] = sumTemp1;
sumPtr[i+2] = sumTemp2;
sumPtr[i+3] = sumTemp3;
}
}
C6000的C代码中的生命周期过长问题
生命周期过长是DSP代码中的常见问题,这是由于流水线相邻阶段的相关性所致。这通常是算法需要在继续下去前保存结果,这就导致了stall。这不同于寄存器生命周期太长问题(register live-too-long)。开发者需要确定哪些C代码中存在这个问题,然后寻求解决方案。图4是一个从D到A的反馈支路,反馈支路导致了两次迭代间的依赖相关性,一个优化方法是duplicate这个反馈支路,然后优化之。图5是用copy-forward方法解决生命周期过长问题。下面是一个解决问题的方法例子。

图4. 使用复制的方式解决生命周期过长问题

图5. 使用copy-forward方法解决生命周期过长问题
for (i=0; i < N; i++)
{
y[i] = func(x[i]);
}
Duplicate à
k = 0;
for (i=0; i < N; i++)
{
y[k++] = func(x[i]);
}
Copy and Forward
for (i=0; i < N; i++)
{
k = i;
y[k] = func(x[i]);
}
References
1 TMS320C6000 Optimizing Compiler User's Guide (SPRU187 http://www.ti.com/lit/pdf/SPRU187 ).
2 C66x CPU and ISA Reference Guide (SPRUGH7 http://www.ti.com/lit/pdf/SPRUGH7 ).
3 TMS320C6000 Programmer's Guide (SPRU198 http://www.ti.com/lit/pdf/SPRU198 ).
4 Hand-Tuning Loops and Control Code on the TMS320C6000 (SPRA666 http://www.ti.com/lit/pdf/SPRA666 )
5. Optimizing Loops on the C66x DSP (SPRABG7 http://www.ti.com/lit/an/sprabg7/sprabg7.pdf)
6. http://houh-1984.blog.163.com/
C66x DSP是TI最新出的定点和浮点混合DSP,后向兼容C64x+和C67x+、C674x系列DSP。本文介绍了基于C66x架构的常用优化技巧,首先介绍C66x相对于C64x+定点DSP的浮点和定点处理能力的增强,以及C66x新引入的128-bit的数据类型。接下来说明c66x特有的特性和相关的优化技术,重点在其浮点增强以及对复数运算和矩阵、向量运算的intrinsics选择,最后是如何解决寄存器不足、SIMD move的使用平衡寄存器和功能单元的分配以及解决寄存器生命周期过长的问题的高级优化技巧。本文中的编译结果基于CCSv4.1中的CGTools v7.2编译器,编译选项–o3 –s –mw –mv6600。