IKAnalyzer中文分词器简介
类文档:http://tool.oschina.net/uploads/apidocs/ikanalyzer/index.html?overview-summary.html
下载:http://code.google.com/p/ik-analyzer/downloads/list
分词器对英文的支持是非常好的。一般分词经过的流程:
1)切分关键词
2)去除停用词
3)把英文单词转为小写
但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好。
国人林良益写的IK Analyzer应该是最好的Lucene中文分词器之一,而且随着Lucene的版本更新而不断更新,目前已更新到IK Analyzer 2012版本。
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。到现在,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
在系统环境:Core2 i7 3.4G双核,4G内存,window 7 64位, Sun JDK 1.6_29 64位 普通pc环境测试,IK2012具有160万字/秒(3000KB/S)的高速处理能力。
特别的,在2012版本,词典支持中文,英文,数字混合词语。
IK Analyzer 2012版本的分词效果示例:
IK Analyzer2012版本支持 细粒度切分 和 智能切分。
我们看两个演示样例:
1)文本原文1:
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版本开始,IKAnalyzer已经推出了3个大版本。
智能分词结果:
ikanalyzer | 是 | 一个 | 开源 | 的 | 基于 | java | 语言 | 开发 | 的 | 轻量级 | 的 | 中文 | 分词 | 工具包 | 从 | 2006年 | 12月 | 推出 | 1.0版 | 开始 | ikanalyzer | 已经 | 推 | 出了 | 3个 | 大 | 版本
最细粒度分词结果:
ikanalyzer | 是 | 一个 | 一 | 个 | 开源 | 的 | 基于 | java | 语言 | 开发 | 的 | 轻量级| 量级 | 的 | 中文 | 分词 | 工具包 | 工具 | 包 | 从 | 2006 | 年 | 12 | 月 | 推出 | 1.0 | 版 | 开始 | ikanalyzer | 已经 | 推出 | 出了 | 3 | 个 | 大 | 版本
2)文本原文2:
张三说的确实在理。
智能分词结果:
张三 | 说的 | 确实 | 在理
最细粒度分词结果:
张三 | 三 | 说的 | 的确 | 的 | 确实 | 实在 | 在理
IKAnalyzer的使用
1)下载地址:
GoogleCode开源项目:http://code.google.com/p/ik-analyzer/
GoogleCode下载地址:http://code.google.com/p/ik-analyzer/downloads/list
2)兼容性:
IKAnalyzer 2012版本兼容Lucene3.3以上版本。
3)安装部署:
十分简单,只需要将IKAnalyzer2012.jar引入项目中就可以了。对于"的"、"了"、"着"之类的停用词,它有一个词典stopword.dic。把stopword.dic和IKAnalyzer.cfg.xml复制到class根目录就可以启用停用词功能和扩展自己的词典。
4)测试例子:
新建一个Java Project,引入Lucene所需的jar文件和IKAnalyzer2012.jar文件,把stopword.dic和IKAnalyzer.cfg.xml复制到class根目录,建立一个扩展词典ext.dic和中文停用词词典chinese_stopword.dic。
chinese_stopword.dic内容格式:

IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;chinese_stopword.dic</entry>
</properties>
可以配置多个词典文件,文件使用";"号分隔。文件路径为相对java包的起始根路径。
扩展词典ext.dic需要为UTF-8编码。
ext.dic内容:
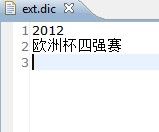
我把"2012"作为一个词,"欧洲杯四强赛"作为一个词。
测试分词代码:
package com.cndatacom.lucene.test;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
* IKAnalyzer 分词器测试
* @author Luxh
*/
public class IKAnalyzerTest {
@Test
public void testIKAnalyzer() throws Exception {
String keyWord = "2012年欧洲杯四强赛";
IKAnalyzer analyzer = new IKAnalyzer();
//使用智能分词
analyzer.setUseSmart(true);
//打印分词结果
printAnalysisResult(analyzer,keyWord);
}
/**
* 打印出给定分词器的分词结果
* @param analyzer 分词器
* @param keyWord 关键词
* @throws Exception
*/
private void printAnalysisResult(Analyzer analyzer, String keyWord) throws Exception {
System.out.println("当前使用的分词器:" + analyzer.getClass().getSimpleName());
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(keyWord));
tokenStream.addAttribute(CharTermAttribute.class);
while (tokenStream.incrementToken()) {
CharTermAttribute charTermAttribute = tokenStream.getAttribute(CharTermAttribute.class);
System.out.println(new String(charTermAttribute.buffer()));
}
}
}
打印出来的分词结果:

可以看到”2012“作为一个词,“欧洲杯四强赛”也是作为一个词,停用词”年“已被过滤掉。
IKAnalyzer各个版本之间有些小的差异,哪一个版本可以结合哪一个Lucene版本使用,下载包里面的说明文档中有说明~~~~
很棒的一个中文分词器~~~