学习 OpenGL 和 OpenCL 的互操作性
转自http://www.linuxeden.com/html/news/20140608/152458.html
引言在过去的十年里, GPU (图形处理单元)已经从特殊硬件(特供)转变成可以在数值计算领域开辟新篇章的高性能计算机设备。 许多算法可以使用拥有巨大的处理能力的GPU来高速执行和处理大数据量。即使在通常的情况下,不可能将图形硬件编程化, 图形硬件也可以加快算法与图像的处理。 举个例子:通常情况下可以用来计算图形差分,模糊图像, 合并图像,甚至是进行图像(或数组)平均值计算。 |
|
随后,可编程方式的出现给编程者带来了极大的便利。 可编程方式所提供的新的可能性,更广泛类别的算法可以移植到GPU来执行。需要转换一定的思路来适应使用屏幕渲染的形式来表达出算法。 现如今可编程GPU支持更高级别的编程范例,可以把它们称之为GPGPU (通用图形处理单元). 新模式允许执行更加通用的算法其不涉及到GPU硬件设备相关内容,可不关心图形化来编制程序了。 |
|
本文探讨不通过GPGPU的API而是用可扩展可编程渲染管道autostereogram与GPGPU进行交互.(译注:这个意思是autostereogram为GPGPU的一个框架么?)autostereogram场景渲染深度缓冲使用GPU的OpenGL和OpenCL (GPGPU) 内核,并且OpenGL GLSL (可编程渲染通道) 着色器的深度数据不必被CPU读取. |
案例分析:Autostereogram本文只提供autostereogram生成算法基础,将不涉及到更多细节,更具体的信息请参阅其他资料。 Autostereograms的普遍使用将使立体图像重新流行。Autostereograms可以使单个图片不聚焦在平面上,以3D场景的形式进行显示 ,最常用的方式是三维场景的展示。
autostereograms编码3D场景的能力并不是最好的, 但很快, 观看隐藏在autostereograms的这些"奥秘" 场景将变的非常容易。 |

|
本文所实现的算法是最简单的autostereogram生成算法之一,该算法简单地重复某个可平铺模式(可以是一个可平铺纹理或者一个随机生成的纹理),并根据输入深度图中像素的z深度来改变其“重复长度”: 对于输出图的每一行:
复制该重复纹理的一整行 (该瓦片)
对输入深度图中该行的每一个像素:
复制离左边 one-tile-width 个像素的那个像素的颜色, 然后减去偏移量 X
对于最大深度(离眼睛最远),X为0,对于最小深度(离眼睛最近),X为最大像素偏移量(~30 像素)
因此,查看器中的像素越是接近,重复模式就越短。这就是诱导眼睛和大脑认为该图像是三维图像的基础。输出图的宽度将会是重复图与输入深度图之和,这样就可以给最初那个未经改变的重复图的拷贝留出足够的空间。 当为之后的结果和性能比较呈现一个参考实现时,一个有着确切描述的CPU实现会在稍后被测试,而不是提供一个更加正式的算法描述。 参考:
一般实现预览: 下图给出了总体的算法流程
|

3d场景渲染使用opengl核心外形管线来完成3d场景的渲染,在此文中用作的示例场景,它包括一个简单反弹的开发箱壁的动画球。此动态场景的选择能提供更多来自不同实现的“实时”效果。 使用aframebufferobject渲染场景纹理是为了更容易操作计算得到的数据,使用纹理作为渲染目的,而不是依靠主要后备缓冲区拥有的某一优势。
然而,它很可能使用标准后备缓冲区来渲染和简单地来回读取此缓冲区。 |
|
场景渲染通常有两个输出结果:颜色缓存和深度缓存。深度缓存是立体图产生的一部分。当渲染场景的时候,就没有必要存储颜色,只需要深度信息。所以,当创建帧缓存对象的时候,就不需要添加颜色纹理信息。下面的代码就展示了以深度纹理作为目的的,帧缓存的创建。 // Allocate a texture to which depth will be rendered. // This texture will be used as an input for our stereogram generation algorithm. glGenTextures( 1 , &mDepthTexture ); glBindTexture( GL_TEXTURE_2D , mDepthTexture ); glTexImage2D( GL_TEXTURE_2D , 0 , GL_DEPTH_COMPONENT32 , kSceneWidth , kSceneHeight , 0 , GL_DEPTH_COMPONENT , GL_FLOAT , 0 ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_MAG_FILTER , GL_LINEAR ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_MIN_FILTER , GL_LINEAR ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_WRAP_S , GL_CLAMP_TO_EDGE ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_WRAP_T , GL_CLAMP_TO_EDGE ); glBindTexture( GL_TEXTURE_2D , 0 ); // Create a framebuffer object to render directly to the depth texture. glGenFramebuffers( 1 , &mDepthFramebufferObject ); // Attach only the depth texture: we don't even bother attaching a target // for colors, because we don't care about it. glBindFramebuffer( GL_FRAMEBUFFER , mDepthFramebufferObject ); glFramebufferTexture2D( GL_FRAMEBUFFER , GL_DEPTH_ATTACHMENT , GL_TEXTURE_2D , mDepthTexture , 0 ); glBindFramebuffer( GL_FRAMEBUFFER , 0 ); 当场景渲染的时候,还有一些初始化的任务。尤其是: 1. 创建,加载和编译渲染着色器 2. 创建顶点缓存 在主渲染循环中,下面的任务是必须加入的: 1. 设置帧缓存对象作为渲染的目标 2. 设置着色器程序作为当前活跃程序 3. 渲染场景 为了保持文章在合理的长度内,这些内容在此都不一一解释了。这些在这个算法中都是很常用,很直接的,没有特别的地方。 下面就是用这个程序渲染的场景结果:
|

水平坐标计算
|
|
这一步的操作结果将最终输出相同的小的立体图,其中每个像素保存一个单一的浮点值,它表示在水平纹理坐标的二维图像。 这些浮点值将不断地从左向右出现,其中小数部分将代表(0~1范围内)的实际坐标和整数部分将代表该模式的重复次数。 这种表示是为了避免在寻找关键值时出现的混合值. 例如,如果值0.99和0.01之间的算法,插值将产生0.5左右的样值,但是这是完全错误的。 通过使用值0.99和1.01,插值将产生约1.0样值,这才是对的。 |
|
上面的伪码稍作修改就能实现这一中间步骤。在为每一个重复瓷片坐标的整个行设置第一个像素标记之后(比如在0——1之间增加取值个数来获取整个瓷片行),查询步骤就可以开始了。查询步骤是通过查询靠左的一个瓷片宽度数减去一个关于深度的值进行的。所以伪码如下: For 输出坐标图片的每一行 为所有重复瓷片的第一行写入坐标 For 输入的深度映射行中的每个像素点 在当前写入行中,将靠左的一瓷片宽度像素减去X的偏移量,并实例化坐标系。 where 对于最大深度(人眼识别的最大深度),X值为0 and 对于最小深度(最接近人眼的深度)X是偏移像素的最大值(~30像素) 这个值加“1”,这样可以使得结果连续递增。 在输出坐标图片中存入计算得到的值。
更细致的应用细节由CPU的相关性能、应用来决定,不过考虑到各种运行细节,这个方法依然是水平较高的算法。 |
立体渲染这最后一步的坐标“形象”,并重复平铺图像作为输入,并简单地通过在合适的位置采样平铺图像最终渲染图像。 它会从输入的坐标“图像“得到水平纹理坐标。他将从输出的坐标"图像"中计算垂直坐标(只是简单的重复自身). 这个采样过程是在GPU上通过自定义着色器完成的。 一个屏幕对齐的四边形开始呈现,接下来的像素着色器则被用来计算最终的颜色渲染。 #version 150
smooth in vec2 vTexCoord;
out vec4 outColor;
// Sampler for the generated offset texture.
uniform sampler2D uOffsetTexture;
// Sampler for the repeating pattern texture.
uniform sampler2D uPatternTexture;
// Scaling factor (i.e. ratio of height of two previous textures).
uniform float uScaleFactor;
void main( )
{
// The horizontal lookup coordinate comes directly from the
// computed offsets stored in the offset texture.
float lOffsetX = texture( uOffsetTexture, vTexCoord ).x;
// The vertical coordinate is computed using a scaling factor
// to map between the coordinates in the input height texture
// (i.e. vTexCoord.y) and where to look up in the repeating pattern.
// The scaling facture is the ratio of the two textures' height.
float lOffsetY = ( vTexCoord.y * uScaleFactor );
vec2 lCoords = vec2( lOffsetX , lOffsetY );
outColor = texture( uPatternTexture , lCoords );
};
这样就完成了算法概述。下一节介绍了CPU执行的坐标生成阶段。 |
CPU实现
|
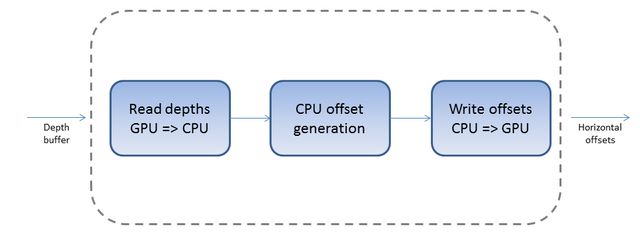
第一步 : 从GPU中读取深度值在进行场景渲染之后,深度值会被保存在GPU的一个纹理中。为了得到CPU算法中所需要的深度值,必须首先从GPU中获取深度值并保存到CPU能够访问的内存中。在这里,一个标准的浮点向量std::vector<float>被用来保存这些用于在CPU进行计算的深度值。实现的代码如下: // 从GPU中读取深度值.
glBindTexture( GL_TEXTURE_2D , mDepthTexture );
glGetTexImage(
GL_TEXTURE_2D ,
0 ,
GL_DEPTH_COMPONENT ,
GL_FLOAT ,
mInputDepths.data()
);
glBindTexture( GL_TEXTURE_2D , 0 );
深度值将被储存在 mInputDepths 这个浮点型向量中。 |
第二步 : 计算偏移量计算偏移量就是简单地实现了上面的伪代码所描述的过程并将计算结果保存到内存数组中。下面的代码展示了如何将输入的深度值转换成相应的偏移量输出。 const int lPatternWidth = pPatternRenderer.GetPatternWidth();
const int lStereogramWidth = kSceneWidth + lPatternWidth;
for ( int j = 0; j < kSceneHeight; ++j )
{
// 首先初始化偏移量数组.
for ( int i = 0, lCountI = lPatternWidth; i < lCountI; ++i )
{
float& lOutput = mOutputOffsets[ j * lStereogramWidth + i ];
lOutput = i / static_cast< float >( lPatternWidth );
}
// 然后计算偏移量.
for ( int i = lPatternWidth; i < lStereogramWidth; ++i )
{
float& lOutput = mOutputOffsets[ j * lStereogramWidth + i ];
// 得到该像素所对应的深度值.
const int lInputI = i - lPatternWidth;
const float lDepthValue = mInputDepths[ j * kSceneWidth + lInputI ];
// Get where to look up for the offset value.
const float lLookUpPos = static_cast< float >( lInputI ) + kMaxOffset * ( 1 - lDepthValue );
// 在两个像素之间进行线性插值.
const int lPos1 = static_cast< int >( lLookUpPos );
const int lPos2 = lPos1 + 1;
const float lFrac = lLookUpPos - lPos1;
const float lValue1 = mOutputOffsets[ j * lStereogramWidth + lPos1 ];
const float lValue2 = mOutputOffsets[ j * lStereogramWidth + lPos2 ];
// 我们对线性插值的量加1以保证偏移量在一个给定的行中总是递增(以保证任何偏移量之间的线性插值都是有意义的)
const float lValue = 1.0f + ( lValue1 + lFrac * ( lValue2 - lValue1 ) );
lOutput = lValue;
}
}
|
第三步 : 将偏移量从CPU写入GPU在上一步偏移量计算结束以后,这些值必须被写回GPU中进行渲染。这个操作和上面第一步的操作正好相反,具体实现的代码如下: glBindTexture( GL_TEXTURE_2D , mOffsetTexture );
glTexSubImage2D(
GL_TEXTURE_2D ,
0 ,
0 ,
0 ,
lStereogramWidth ,
kSceneHeight ,
GL_RED ,
GL_FLOAT ,
mOutputOffsets.data()
);
glBindTexture( GL_TEXTURE_2D , mOffsetTexture );
偏移量将会被写入到GPU的存储器中。 这样就完成了算法的CPU实现。这种方法的最大缺点是每一帧都需要在CPU和GPU之间进行大量的数据交换。从GPU进行图像数据的读取然后再写回GPU,这严重影响了实时程序的性能。 为了防止这个问题,第二步的处理将直接在GPU的存储器上执行,以避免CPU和GPU之间的往返读写。这一方法将在下面的部分中进行具体描述。 |
GPU 实现为了避免CPU和GPU之间不必要的往返读写,深度数据应该直接在GPU上进行处理。然而,stereogram生成算法需要得到先前输出图像同一行中设置的值。和使用片段着色器一样,对相同的纹理/图像缓冲区同时进行读取和写入对于传统GPU来说是非常不友好的的处理方法。 这里可以使用一个“带”为基础的方法,其中垂直条带会被从左至右呈现出来,每个频带的大小都不会超过左边的最小距离。在所提供的例子的源代码中可以看到,重复图案的宽度是85个像素,而最大的偏移量是30个像素(kMaxOffset的值),所以产生的最大的频带宽度为55个像素。由于不能过对于将要写入的纹理进行随机读取的操作,因此被渲染的纹理必须同时保存两个副本:一个用于读取,一个用于写入。那么刚才所写的必须被复制到另一个的纹理中去。 |
|
这种使用两个纹理的方法并不是最佳的。另外,频带的宽度对渲染的次数有直接的影响,这也将对性能产生直接的影响。不过,这个宽度是依赖于重复图案的,它可以根据具体的情况而改变,同时最大偏移量也是一个可以根据实时性需求改变的参数。性能会受到参数变化的影响,这并不是理想的情况。 一种更加灵活的方法是使用可编程渲染管线。使用OpenCL。GPGPU的API中“通用”的部分在类似的应用程序中发挥着十分重要的作用。这将允许使用GPU进行更通用,而非面向渲染的算法。这种灵活性使得我们能够有效地利用GPU进行立体图的生成。 首先,我们需要对前面CPU实现的算法做一些改变。然后对创建一个OpenCL的上下文,以及利用OpenCL对OpenGL的上下文的共享资源的使用进行说明。最后,将对使用OpenCL核函数来产生立体图的方法以及所需的要素进行展示。 |
渲染场景要做出的修改CPU版本的深度贴图算法不能被用于GPU。这贴图会同时被OpenCL使用,而OpenCL能直接使用的OpenGL贴图格式有限。依据文档clCreateFromGLTexture2D其中提到的支持的图像通道格式,GL_DEPTH_COMPONENT32不是可以被OpenCL使用的图像格式,非常不幸,因为这个图像格式和我们想要使用的非常像,但是我们可以避开这个问题。 |
|
为从场景渲染步骤中获取深度纹理,第二个纹理对象将填充到帧缓冲区。切记只有单一深度纹理会附属于CPU版本。这个深度纹理仍然需要填充到深度缓冲区进行深度测试才能显示。不管怎样,另一个纹理会作为成颜色填充除非接收到相应颜色单元值,它将会接收深度值。下面的代码展示了如何创建纹理以及如何将它帧缓冲区对象。 // Skipped code to allocate depth texture... // *** DIFFERENCE FROM CPU IMPLEMENTATION *** // However, because OpenCL can't bind itself to depth textures, we also create // a "normal" floating point texture that will also hold depths. // This texture will be the input for our stereogram generation algorithm. glGenTextures( 1 , &mColorTexture ); glBindTexture( GL_TEXTURE_2D , mColorTexture ); glTexImage2D( GL_TEXTURE_2D , 0 , GL_R32F , kSceneWidth , kSceneHeight , 0 , GL_RED , GL_FLOAT , 0 ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_MAG_FILTER , GL_LINEAR ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_MIN_FILTER , GL_LINEAR ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_WRAP_S , GL_CLAMP_TO_EDGE ); glTexParameteri( GL_TEXTURE_2D , GL_TEXTURE_WRAP_T , GL_CLAMP_TO_EDGE ); glBindTexture( GL_TEXTURE_2D , 0 ); // Create a framebuffer object to render directly to the depth texture. glGenFramebuffers( 1 , &mDepthFramebufferObject ); // Attach the depth texture and the color texture (to which depths will be output) glBindFramebuffer( GL_FRAMEBUFFER , mDepthFramebufferObject ); glFramebufferTexture2D( GL_FRAMEBUFFER , GL_DEPTH_ATTACHMENT , GL_TEXTURE_2D , mDepthTexture , 0 ); glFramebufferTexture2D( GL_FRAMEBUFFER , GL_COLOR_ATTACHMENT0 , GL_TEXTURE_2D , mColorTexture , 0 ); glBindFramebuffer( GL_FRAMEBUFFER , 0 ); 片断着色器会使用深度值对颜色填充进行渲染。正如下面代码所示的那样简洁。 #version 150
out vec4 outColor;
void main( )
{
float lValue = gl_FragCoord.z;
outColor = vec4( lValue , lValue , lValue , 1.0 );
}
这些修改将使纹理适用于 withclCreateFromGLTexture2D(),以便于在OpenCL的上下文共享,正如下面的部分展示的那样。
文章转载自:开源中国社区 [http://www.oschina.net] 英文原文:OpenGL / OpenCL Interoperability : A Case Study Using Autostereograms |
