JAVA API备忘----I/O
java的I/O向来以纷繁复杂著称。如此多的I/O类,以至于在第一次看到是我就一句:my god,甚至于在用了许多次之后仍然是没有半点概念,下次再用仍然一无所知。的确,是该打压下javaI/O的嚣张气焰了,所以写这篇东西以自勉。关于JAVA I/O,网上也有足够的文章了,比较好的一篇是《彻底明白java的I/O》,整个体系上比较全,今后可以参考。


转自 http://blog.sina.com.cn/s/blog_58adc9e7010009j5.html
在开始之前,先记住,java有两个对称,记得在高数中对空间物体求积分时往往只需要求一小部分,剩下的根据对称乘4或乘8就搞定了,因此对称是相当有效 的方法。在javaI/O中,利用这两个对称你只需掌握1/4,其余的几乎可以推导出来。这两个对称是:输入和输出的对称、字节和字符的对称。也就是说 java I/O的整个体系就是输入字节流,输出字节流,输入字符流,输出字符流四大块。
javaI/O将所有输入输出都看成某种形式的流,流的概念也不陌生了,就好比一个字符串,不是整个将它copy进文件,取而代之,将这个String看作是字符数组,将字符一个一个copy进文件,这样对外而言就是连续的输入文件,就象水流一样。
对任何系统而言,都存在输入和输出,在Java中就表现为InputStream、OutStream;同时,由于Java本身的编码是unicode, 不同于一般字节编码的编译器,所以又分为以字节为导向和以unicode字符为导向,这样对于两种不同的字符处理有着各自的方便,于是就出现了上面提到的 对称。以下就是java的I/O体系。
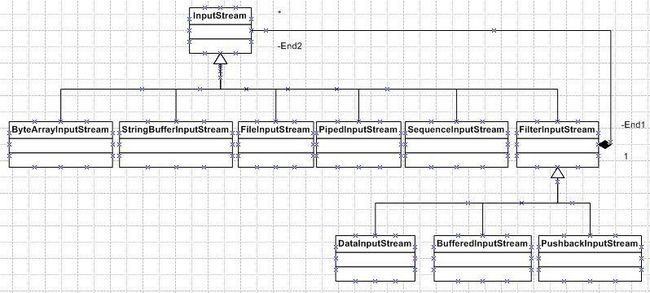
需要记住字节导向的输入流,因为它是最全的。这里需要分别知道各个inputstream的作用,这样才能在适当的场合使用适当的类。首先我们得知道有哪 几种输入类型:字节数组(ByteArrayInputStream),String对象(StringBufferInputStream),文件 (FileInputStream),管道(PipedInputStream),其他流数据(SequenceInputStream),其他数据源 (FilterInputStream)。例如我想从文件中读出数据,自然就能想到FileInputStream;再比如我想从字节数组读数据,这时就 要使用ByteArrayInputStream。在这里InputStream是所有这些类型的父类,根据对称原则,剩下的几个就可以参看图示记忆了, 基本都是一样的。
装饰器模式:
java能够跨平台,这意味着最大的好处就是能够应对多种输入输出情况,缓冲的、打印机的、屏幕的、文件的,而java为了应付各种输入输出而创造了许多类。这样可以减少相互之间的耦合,增加高松散性,并且因此引入的装饰器模式更让整个I/O包有了更好的可维护性。
首先,java对基本的输入输出对应了基本的类,但是我们却不能很方便的做某些事情,比如我要将一个文件读入一个缓冲区进行处理,完了再从缓冲区重新写回文件。通常我们都会这么写:
| ...... BufferedInputStream bis = new BufferedInputStream( new FileInputStream("aaa.txt")); bis.read(); ...... |
这个时候就要用到FilterInputStream了。如图,FileInputStream和 FilterInputStream都是继承自InputStream,而BufferedInputStream又继承自 FilterInputStream,也就是说每一个BufferedInputStream也是一个InputStream对象。并且,由于它们都是抽 象类InputStream的子类,所以它们都重写了read()方法。不同的是FileInputStream的read()是操作I/O读如文件,而 BufferedInputStream则在自己的read()中先执行了传入的FileInputStream的read(),之后再加入了一段特殊的 处理将这个stream加入到buffer的程序,所以在BufferedInputStream中read()看起来应该如此:
| read(){ fileInputStream.read(); //将stream的读入的内容输出到buffer } |
这时候调用BufferdInputStream的read()就相当于调用了fileInputStream的read()和自己的处理,最开始只是文 件,后来进化到文件+buffer。类似的,我们还可以像这样再“包装”,这样一来,这个原始的对象就有了更多的功能,这就是decorator的威力 了。不修改现有的代码,只需继承特定的接口便能有效的利用现有代码,好像我们现实生活中层层打包,每次都包进一件东西。
在jive中也有同样使用的例子:
我们有论坛的消息需要处理,最开始我们需要消息高亮,然后我们要过滤掉违禁词语,最后我们要过滤掉中间那些HTML文本,使HTML文本以文本方式而不是 在浏览器中以控制符输出。怎么做呢,同样的道理,第一次对Message用消息高亮过滤器包装,第二次对Message用违禁词语过滤器包装,第三次用 HTML文本过滤器包装,则在调用最外层包装器的getBody()方法时,先调用次外层的getBody()方法,最后是最里层的getBody()方 法,返回一个处理过的Message,此外层接着处理,再返回到最外层处理完的Message,最后此外层处理完整个过程就结束了,实际上处理过三次,非 常高级的办法。需要更多信息,请参考jive源码和GOF设计模式。
值得注意的是只有继承FilterInputStream的类才有“包装”的功能,其他类只能做为最底层的“被包装者”。
既然如此,包装者自然很重要了,同样需要我们熟悉和记忆。以下给出“包装者”图。这里介绍两个比较基本的DataInputStream和 BufferedInputStream,前者是读取各种基本类型的包装器,比如int,long等等;而后者是读缓冲区的包装器。一般情况下可以用 DataInputStream,当然,如果需要readLine()方法时用BufferedReader。(DataInputStream的 readLine方法被declared,因为它被认为是不适合转换字节到字符)
将字节流向字符流转换的类:
InputStreamReader, OutputStreamWriter。分别将inputStream转换成Reader,以及OutputStream转为Writer。在某些特定的场合很有用。
最后,让我们见识一下javaI/O中几个独立的类: StreamTokenizer,RandomAccessFile
StreamTokenizer把一个输入流分析为多个“标记(token)”,允许一次读取一个标记。分析过程由一张表和可设置为多种状态的多种标记控制。很类似StringTokenizer,但是功能稍微强些,能够查许多特殊字符。
RandomAccessFile可以用来随机存取文件,跟其它只能顺序读取的类比较,它更能满足某些特殊的需要。通过seek()就能地位。并且可以用r,w在创建文件时来指定读写。
现在可以练练手,找几个常用的输入输出来做。
1.将数据从文件test.txt读入缓冲区。
2.从键盘读入数据,如果是y则将数据变为字符串,否则不变。
3.将格式化的数据再次读入。
4.最后将数据转变为字符流输出。
转自 http://blog.sina.com.cn/s/blog_58adc9e7010009j5.html