XML基础和XML编程
XML基础和XML编程
XML 的学习目标:
1.能够用xml 描述有层次的数据关系.
2.能够用解析器读取xml中的有层次关系的数据. (parser)
一、XML是什么?作用是什么?
1、XML是指可扩展标记语言(eXtensible Markup Language),用户自定义的标签.相对于HTML来讲的。
2、XML被设计的宗旨是表示数据。HTML是用来显示数据的。目前经常使用的XML版本是1.0
3、XML除了表示数据外。在实际的企业开发中,主要用XML作为程序的配置文件。
二、XML的基本语法
1)文档声明
编写xml文件的时候,必须要添加声明. 声明必须要出现在第一行,之前连空行都不能有.
最简单的文档声明: <?xml version="1.0"?>
如果要添加中文字符: 需要给其设定encoding属性.
<?xml version="1.0" encoding="gbk"?>
standalone 属性, 用来说明xml 文档是否独立.
注意: 在写标点符号的时候,需要是英文的标点符号.
2)元素
a) 一个xml的元素也可以叫做标签. 这个必须要有 开始和结束标签.
如果标签中没有 标签体, 那么也可以简写成 . 例如 : <北京/>
标签要合理的嵌套.不能够没爹没娘的嵌套.
一个xml 文档必须有且仅有一个根标签哦.
b) xml中的空格和换行会被当做元素内容去处理,所以在实际开发过程中,需要将
空格和换行 给去掉. 响应的写成这样一种形式:
例如: <中国><北京/></中国>
3)属性
一个xml标签可以有多个属性, 语法类似 html中设置 属性的语法.
<mytag name="value"/>
其中,标签中的属性也可以改写成这样一种形式:
<mytag>
<name>
<firstname></firstnamename>
<secondname></secondname>
</name>
</mytag>
4注释
注释的格式: <!-- 这是注释哦-->
注释也不能够嵌套.
xml中的注释不能够出现在第一行.
5.CDATA区 、
CDATA (Character Data) 的缩写. 实际开发过程中,一些数据可能不想让解析引擎处理.
就可以把它们放到CDATA区中
<![CDATA[
文本内容
]]>
特殊字符 :
& & ampersand
> > great than
< < less than
" " quotation
' ' apostrophe
6.处理指令(processing instruction) (PI)
<?xml-stylesheet type="text/css" href="s.css"?>
文档的声明也是一个处理指令
三、XML的约束
1、格式良好的XML文档:符合XML语法的。
2、有效的XML文档:遵循约束规范的。
格式良好的不一定是有效的,但有效的必定格式良好。
四、DTD的基本语法(看懂即可)
1、DTD:Document Type Definition
2、作用:约束XML的书写规范。
3、DTD文件保存到磁盘时,必须使用UTF-8编码
4、如何引入外部的DTD文档来约束当前的XML文档
DTD文件在本地:<!DOCTYPE 根元素名称 SYSTEM "DTD文件的路径">
DTD文件在网络上:<!DOCTYPE 根元素名称 PUBLIC "DTD名称" "DTD的路径URL">
5、DTD的语法细节
5.1定义元素
语法:<!ELEMENT 元素名称 使用规则>
使用规则:
(#PCDATA):指示元素的主体内容只能是普通的文本.(Parsed Character Data)
EMPTY:指示元素的不能有主体内容。
ANY:用于指示元素的主体内容为任意类型
(子元素):指示元素中包含的子元素
如果子元素用逗号分开,说明必须按照声明顺序去编写XML文档
如果子元素用“|”分开,说明任选其一。
用+、*、?来表示元素出现的次数
5.2定义元素的属性(attribute)
语法:<!ATTLIST 哪个元素的属性
属性名1 属性值类型 设置说明
属性名2 属性值类型 设置说明>
属性值类型:
CDATA:说明该属性的取值为一个普通文本
ENUMERATED (DTD没有此关键字):
语法:<!ATTLIST 元素名称 (值1|值2) "值1">
ID:属性的取值不能重复
设置说明:
#REQUIRED:表示该属性必须出现
#IMPLIED:属性可有可无
#FIXED:表示属性的取值为一个固定值 语法:#FIXED "固定值"
直接值:表示属性的取值为该默认值
5.2定义实体
关键字ENTITY
实体的定义分为引用实体和参数实体
引用实体:
作用:在DTD中定义,在XML中使用
语法:<!ENTITY 实体名称 "实体内容">
在XML中使用:&实体名称;
参数实体:
作用:在DTD中定义,在DTD中使用
语法:<!ENTITY % 实体名称 "实体内容">
在DTD中使用:%实体名称;
五、XML解析方式概述
1、常用XML的解析方式:DOM和SAX
DOM:Document Object Model是W3C推荐使用的解析方式
SAX:Simple API for XML。非官方标准。
2、常用解析开发包:
JAXP:SUN推出的实现,能进行DOM和SAX方式解析
Dom4J
JDom等
六、JAXP进行DOM解析
JAXP的API都在JavaSE中。
org.w3c.dom:提供DOM方式解析XML的标准接口
org.xml.sax:提供SAX方式解析XML的标准接口
javax.xml:提供了解析XML文档的类
XML编程(CRUD)
DOM解析:
获得JAXP中的DOM解析器:
l 调用 DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。
l 调用工厂对象的 newDocumentBuilder方法得到 DOM 解析器对象。
l 调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进而可以利用DOM特性对整个XML文档进行操作了。
DOM模型(document object model)
DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系, 解析成一个个Node对象(节点)。
在dom中,节点之间关系如下:
位于一个节点之上的节点是该节点的父节点(parent)
一个节点之下的节点是该节点的子节点(children)
同一层次,具有相同父节点的节点是兄弟节点(sibling)
一个节点的下一个层次的节点集合是节点后代(descendant)
父、祖父节点及所有位于节点上面的,都是节点的祖先(ancestor)
Node对象
Node对象提供了一系列常量来代表结点的类型,当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象(Node的子类对象),以便于调用其特有的方法。(查看API文档)
Node对象提供了相应的方法去获得它的父结点或子结点。编程人员通过这些方法就可以读取整个XML文档的内容、或添加、修改、删除XML文档的内容了。
更新XML文档
avax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象,
用javax.xml.transform.stream.StreamResult 对象来表示数据的目的地。
Transformer对象通过TransformerFactory获得。
实例代码:
- <?xml version="1.0" encoding="UTF-8" standalone="no"?>
- <!DOCTYPE china[
- <!ELEMENT china (itheima,itcast)>
- <!ELEMENT itheima (teacher+)>
- <!ELEMENT itcast (teacher+)>
- <!ELEMENT teacher (name,age,teach)>
- <!ELEMENT name (#PCDATA)>
- <!ELEMENT age (#PCDATA)>
- <!ELEMENT teach (#PCDATA)>
- <!ATTLIST teacher id ID #REQUIRED>
- ]>
- <china>
- <itheima>
- <teacher id="a1">
- <name>张孝祥</name>
- <age>38</age>
- <teach>javaee</teach>
- </teacher>
- <teacher id="a2">
- <name>方立勋</name>
- <age>36</age>
- <teach>javaweb</teach>
- </teacher>
- <teacher id="a3">
- <name>付东</name>
- <age>34</age>
- <teach>andriod</teach>
- </teacher>
- <!-- 验证成功 -->
- </itheima>
- <itcast>
- <teacher id="b1">
- <name>张磊</name>
- <age>34</age>
- <teach>web基础</teach>
- </teacher>
- <teacher id="b2">
- <name>韩顺平</name>
- <age>39</age>
- <teach>linux</teach>
- </teacher>
- <teacher id="b3">
- <name>张昭廷</name>
- <age>34</age>
- <teach>javaweb</teach>
- </teacher>
- </itcast>
- </china>
-------------------------------------------------
- package cn.itheima.dom;
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import javax.xml.transform.Transformer;
- import javax.xml.transform.TransformerFactory;
- import javax.xml.transform.dom.DOMSource;
- import javax.xml.transform.stream.StreamResult;
- import org.junit.Assert;
- import org.junit.Test;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
- public class DOMTeast {
- /**
- * @param args
- * @throws Exception
- */
- public static void main(String[] args) throws Exception {
- // TODO Auto-generated method stub
- // test1();
- // readAtt();
- // addNode();
- // deleteNode();
- // binaLiNode();
- // refreshNode();
- }
- // 6.打印所有元素节点的名称. 遍历
- public static void binaLiNode() throws Exception{
- Document document = getDocument();
- listNode(document);
- }
- private static void listNode(Node node) {
- // TODO Auto-generated method stub
- if(node.getNodeType() == Node.ELEMENT_NODE){
- System.out.println(node.getNodeName());
- }
- NodeList nl = node.getChildNodes();
- for (int i = 0; i < nl.getLength(); i++) {
- Node node1 = nl.item(i);
- listNode(node1);
- }
- }
- // 5.更新节点 : <teach>javaee</teach>
- public static void refreshNode() throws Exception{
- Document document = getDocument();
- NodeList nodeList = document.getElementsByTagName("teach");
- /*for (int i = 0; i < nodeList.getLength(); i++) {
- Node node = nodeList.item(i);
- if(node.getTextContent().equals("javaee")){
- node.getParentNode().setTextContent("android");
- }
- }*/
- nodeList.item(0).getParentNode().setTextContent("android");
- refreshXML(document);
- }
- // 4.删除节点 : <teach>javaee</teach>
- @Test
- public static void deleteNode() throws Exception{
- Document document = getDocument();
- NodeList nodeList = document.getElementsByTagName("teach");
- for (int i = 0; i < nodeList.getLength(); i++) {
- Node node = nodeList.item(i);
- if(node.getTextContent().equals("javaee")){
- node.getParentNode().removeChild(node);
- }
- }
- refreshXML(document);
- }
- // 3.添加节点 : <售价>59.00</售价>
- public static void addNode() throws Exception{
- Document document = getDocument();
- // 添加吴超标签题,然后设置属性id为5;
- Element element = document.createElement("teacher");
- // element.setAttribute("id", "5");
- element.setTextContent("test");
- Node item = document.getElementsByTagName("itheima").item(0);
- item.appendChild(element);
- refreshXML(document);
- }
- // 2.读取属性值,这个思路没问题,测试结果不行!!!--
- public static void readAtt() throws Exception{
- Document document = getDocument();
- NodeList tagName = document.getElementsByTagName("name");
- /*for(int i = 0;i<tagName.getLength();i++){
- Element item = (Element) tagName.item(i);
- //测试用
- // System.out.println(item.getLocalName());
- Object att = item.getAttribute("color");
- System.out.println(att);
- Assert.assertEquals("red", att);
- }*/
- Element item = (Element) tagName.item(0);
- Object att = item.getAttribute("color");
- System.out.println(att);
- Assert.assertEquals("red", att);
- }
- // * 1.读取节点的文本内容
- public static void test1() throws Exception{
- Document document = getDocument();
- NodeList tagName = document.getElementsByTagName("teach");
- for(int x = 0;x<tagName.getLength();x++){
- Node node = tagName.item(x);
- //getTextContent获取标签的标签体
- String string = node.getTextContent();
- System.out.println(string);
- /*javaee
- javaweb
- andriod
- web基础
- linux
- javaweb*/
- }
- }
- // -----------------------------------------
- public static Document getDocument() throws Exception{
- // 首先拿到 一个 documentbuilderfactory 对象.
- DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- // 通过 factory 对象拿到 一个 documentbuilder对象.
- DocumentBuilder builder = factory.newDocumentBuilder();
- // 通过 builder的 parse 方法获得一个 document 对象.
- Document document = builder.parse("src\\itheima.xml");
- return document;
- }
- // -----------------------------------------
- public static void refreshXML(Document doc) throws Exception{
- // 如何更新 xml 文件 从 内存 中 到 xml 文档.
- // 首先 要 拿到 一个工厂
- TransformerFactory factory = TransformerFactory.newInstance();
- // 拿到 工厂 之后 在 获得一个 transformer
- Transformer transformer = factory.newTransformer();
- transformer.transform(new DOMSource(doc), new StreamResult("src/itheima.xml"));
- }
- }
七、JAXP进行SAX解析
在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。 (java 中虚拟机默认开辟的内存空间) out of memort(OOM)
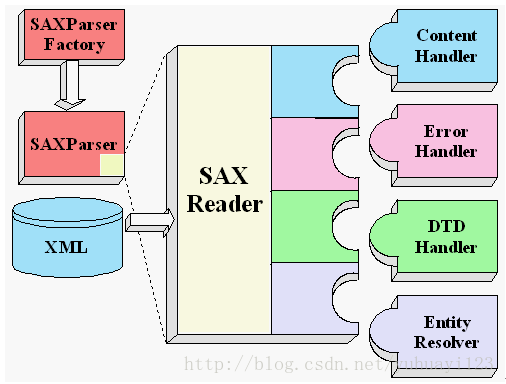
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才对文档进行操作。
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器:
解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。
解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
SAX方式解析XML文档
使用SAXParserFactory创建SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
通过SAX解析工厂得到解析器对象
SAXParser sp = spf.newSAXParser();
通过解析器对象得到一个XML的读取器
XMLReader xmlReader = sp.getXMLReader();
设置读取器的事件处理器
xmlReader.setContentHandler(new BookParserHandler());
解析xml文件
xmlReader.parse("book.xml");
******八.Pull解析器
pull 解析器是一个第三方的开源api,其解析原理与sax 解析原理很相像,都是采用事件驱动的方式.
不同点: pull 解析器在每次读取到一段数据之后,需要程序员手动的调用其next() 方法,将当前解析到的这一行的"指针"移到下一行.
- <?xml version="1.0" encoding="UTF-8" standalone="no"?><书架>
- <书 出版社="北京传智">
- <书名>Java就业培训教程</书名>
- <作者>张孝祥</作者>
- <售价>59.00元</售价>
- </书>
- <书 出版社="上海传智">
- <书名>JavaScript网页开发</书名>
- <作者>张孝祥</作者>
- <售价>28.00元</售价>
- </书>
- </书架>
------------------------------------------------------------------------------
- public static List<Book> getBooks() throws Exception{
- List<Book> list = new ArrayList<Book>();
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlPullParser parser = factory.newPullParser();
- parser.setInput(new FileInputStream("src/book.xml"), "UTF-8");
- int eventType = parser.getEventType();
- Book book = null ;
- while(eventType != XmlPullParser.END_DOCUMENT){
- switch (eventType) {
- case XmlPullParser.START_TAG:
- if("书".equals(parser.getName())){
- String area = parser.getAttributeValue(0);
- book = new Book();
- book.setArea(area);
- }
- if("书名".equals(parser.getName())){
- // 用于 获取 书名 开始 后 紧挨着的 文本 内容
- String bookname = parser.nextText();
- book.setBookaname(bookname);
- }
- if("作者".equals(parser.getName())){
- // 用于 获取 书名 开始 后 紧挨着的 文本 内容
- String author = parser.nextText();
- book.setAuthor(author);
- }
- break;
- case XmlPullParser.END_TAG:
- if("书".equals(parser.getName())){
- list.add(book);
- book=null;
- }
- break;
- default:
- break;
- }
- eventType = parser.next();
- }
- return list;
- }
开始解析文档
area = 出版社, author = 张孝祥, bookaname = Java就业培训教程
area = 出版社, author = 张孝祥, bookaname = JavaScript网页开发开始解析文档
area = 出版社, author = 张孝祥, bookaname = Java就业培训教程
area = 出版社, author = 张孝祥, bookaname = JavaScript网页开发开始解析文档
area = 出版社, author = 张孝祥, bookaname = Java就业培训教程
area = 出版社, author = 张孝祥, bookaname = JavaScript网页开发
九、Dom4J简介
Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j开发,需下载dom4j相应的jar文件。
DOM4j中,获得Document对象的方式有三种:
1.读取XML文件,获得document对象
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document对象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主动创建document对象.
Document document = DocumentHelper.createDocument();
//创建根节点
Element root = document.addElement("members");
节点对象
1.获取文档的根节点.
Element root = document.getRootElement();
2.取得某个节点的子节点.
Element element=node.element(“书名");
3.取得节点的文字
String text=node.getText();
4.取得某节点下所有名为“member”的子节点,并进行遍历.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something
}
5.对某节点下的所有子节点进行遍历.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something
}
6.在某节点下添加子节点.
Element ageElm = newMemberElm.addElement("age");
将文档写入XML文件.
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
// 指定XML编码
format.setEncoding("GBK");
XMLWriter writer = new XMLWriter(new FileOutputStream("output.xml"),format);
writer.write(document);
writer.close();
字符串与XML的转换
1.将字符串转化为XML
String text = "<members> <member>sitinspring</member></members>";
Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
*****十、XML约束之schema(看懂即可)
XML Schema 文件自身就是一个XML文件,但它的扩展名通常为.xsd。
一个XML Schema文档通常称之为模式文档(约束文档),遵循这个文档书写的xml文件称之为实例文档。
和XML文件一样,一个XML Schema文档也必须有一个根结点,但这个根结点的名称为Schema。
编写了一个XML Schema约束文档后,通常需要把这个文件中声明的元素绑定到一个URI地址上,在XML Schema技术中有一个专业术语来描述这个过程,即把XML Schema文档声明的元素绑定到一个名称空间上,以后XML文件就可以通过这个URI(即名称空间)来告诉解析引擎,xml文档中编写的元素来自哪里,被谁约束。
重点: 能够根据schema 写出 xml 文档.
难点: 如何去引用一个已经写好的 schema 文档.
名称空间的概念
在XML Schema中,每个约束模式文档都可以被赋以一个唯一的名称空间,名称空间用一个唯一的URI(Uniform Resource Identifier,统一资源标识符)表示。 在Xml文件中书写标签时,可以通过名称空间声明(xmlns),来声明当前编写的标签来自哪个Schema约束文档。如:
<itcast:书架 xmlns:itcast=“http://www.itcast.cn”>
<itcast:书>……</itcast:书>
</itcast:书架>
此处使用itcast来指向声明的名称,以便于后面对名称空间的引用。
注意:名称空间的名字语法容易让人混淆,尽管以 http:// 开始,那个 URL 并不指向一个包含模式定义的文件。事实上,这个 URL:http://www.itcast.cn根本没有指向任何文件,只是一个分配的名字。
使用名称空间引入Schema
为了在一个XML文档中声明它所遵循的Schema文件的具体位置,通常需要在Xml文档中的根结点中使用schemaLocation属性来指定,例如:
<itcast:书架 xmlns:itcast="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.itcast.cn book.xsd">
schemaLocation此属性有两个值。第一个值是需要使用的命名空间。第二个值是供命名空间使用的 XML schema 的位置,两者之间用空格分隔。
注意,在使用schemaLocation属性时,也需要指定该属性来自哪里。
使用默认名称空间
基本格式:
xmlns="URI"
举例:
<书架 xmlns="http://www.it315.org/xmlbook/schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation=“http://www.itcast.cn book.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
<书架>
使用名称空间引入多个XML Schema文档
文件清单:xmlbook.xml
<?xml version="1.0" encoding="UTF-8"?>
<书架 xmlns="http://www.it315.org/xmlbook/schema"
xmlns:demo="http://www.it315.org/demo/schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.it315.org/xmlbook/schema http://www.it315.org/xmlbook.xsd
http://www.it315.org/demo/schema http://www.it315.org/demo.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价 demo:币种=”人民币”>28.00元</售价>
</书>
</书架>
不使用名称空间引入XML Schema文档
文件清单:xmlbook.xml
<?xml version="1.0" encoding="UTF-8"?>
<书架 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="xmlbook.xsd">
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
</书架>
在XML Schema文档中声明名称空间
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www. itcast.cn"
elementFormDefault="qualified">
<xs:schema>
targetNamespace元素用于指定schema文档中声明的元素属于哪个名称空间。
elementFormDefault元素用于指定,该schema文档中声明的根元素及其所有子元素都属于targetNamespace所指定的名称空间。
作业
a. 参看w3c文档
b. xml一般的应用场景?
c. xml的约束结束有几种?分别是什么技术?
d. 简述dom解析的原理? dom解析与sax 解析的各自的优点以及缺点是什么?
e. 在一个java项目中,如何导入第三方开源jar包?
f. 参看dom4j quick start (快速入门)
g. 简述pull 解析器的原理? 参看pull 解析器的api文档.
h. 在schema 中名称空间的是什么?
i. 一个schema 约束文档 的根元素必须要是什么?
a) 思考 : 你要写的xml 文档的 根元素是 什么?
看schema 文档中的 第一个 element 出现的地方.
<xs:element name='书架' >
b) 思考: 你写的 根元素来自于哪个 名称 空间.
看 schema 文档的 targetNamespace="http://www.itcast.cn" .
<itcast:书架 xmlns:itcast="http://www.itcast.cn">
c) 思考: 名称空间与 这个 schema 约束的 对应关系.
xsi:schemaLocation="{namespace} {location}"
d)<itcast:书架 xmlns:itcast="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn book.xsd">
XSD是指XML结构定义 ( XML Schemas Definition )
XML Schema 是DTD的替代品。XML Schema语言也就是XSD。
XML Schema描述了XML文档的结构。可以用一个指定的XML Schema来验证某个XML文档,以检查该XML文档是否符合其要求。文档设计者可以通过XML Schema指定一个XML文档所允许的结构和内容,并可据此检查一个XML文档是否是有效的。XML Schema本身是一个XML文档,它符合XML语法结构。可以用通用的XML解析器解析它。
一个XML Schema会定义:文档中出现的元素、文档中出现的属性、子元素、子元素的数量、子元素的顺序、元素是否为空、元素和属性的数据类型、元素或属性的默认和固定值。
XSD是DTD替代者的原因,一是据将来的条件可扩展,二是比DTD丰富和有用,三是用XML书写,四是支持数据类型,五是支持命名空间。
XSD文件的后缀名为.xsd。
XML Schema的优点:
1) XML Schema基于XML,没有专门的语法
2) XML可以象其他XML文件一样解析和处理
3) XML Schema支持一系列的数据类型(int、float、Boolean、date等)
4) XML Schema提供可扩充的数据模型。
5) XML Schema支持综合命名空间
6) XML Schema支持属性组。