一: memcached介绍
memcached是一个分布式的基于内存的缓存服务器,我们一般用memcached来减轻数据库的负载,提高程序的响应速度。
memcahched采用key-value存储数据,将对象序列化成二进制,以便在网络中进行传输。
二: Linux安装
memcached是基于libevent库的,所以要先安装libevent,然后在安装memcached,主要的几步操作如下:
tar -zxvf memcached-1.4.25.tar.gz
cd
./configure
make
make install
安装好后,启动memcached服务 ./memcached -d -m 1024 -p 10000 -u root -P /tmp/memcached.pid
查看服务是否启动:ps -ef | grep 10000

三:memached的工作机制
3.1 memcached的内存存储
memcached是一个基于内存的高性能的缓存服务器,为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启服务器、重启操作系统等都会导致数据丢失。
memcached目前采用的是Slab Allocator来管理内存,它的原理非常简单,根据我们约定好的块大小,预先将分配的内存分成各个块,并将大小一样的块分成各个组。
当客户端有一个add或者set操作往缓存里存数据的时候,memcached根据添加的数据大小选择合适的某个slab。
1、memcached将内存空间分为一组slab
2、每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的。如果key不和chunk相 匹配,会有一定的内存浪费。但是不会存在内存碎片,我们可以通过在启动服务时-f来减低每个chunk之间的大小差,以便更合理的利用内存
3、相同大小chunk的slab被组织在一起,称为slab_class.
3.2 memcached的缓存过期
在往缓存里面添加数据的时候,可以指定一个expire,表示该数据的过期时间,单位是s,但是由于memecached不会释放已经分配的内存,当我们往缓存里面添加数据的时候,可能会内存空间不足,这个时候memecached就需要择优选择一块可用的内存来存储我们的数据。
memcached使用的是LRU的方式来释放内存,即最近最少使用的内存将优先被用来存新的数据。
memcached采用的是偷懒机制,当某个key过期后,并不会马上释放内存,而是等待下次有get请求到来时,如果发现该key已经过期了才会删除,但其实memcached内部在很多情况下都会判断某个key是否失效,比如当我们重新set一个新的数据时,这个时候memcached需要重新申请一个item来存储咱们的数据,它会首先判断咱们请求的大小然后选择相应的slab放到里面,在这个地方,它在循环slab里面的item的时候实际上已经对每个item进行了判断是否过期,如果过期了,那么就直接使用这个item了。
3.3 memcahced如何实现分布式
一般的分布式系统,都是在服务器端实现的分布式,但是memcached却不是,由于各个memcached服务器之间不存在主备关系,也没有互相通信,所以memcached的分布式是在客户端实现的。
当我们缓存一个key,value的数据时,客户端首先根据一致性hash算法根据key来决定哪个服务器保存该数据。这个地方的原理很简单,将各个服务器节点的哈希值映射到一个圆上,然后将算出的key的哈希值也映射到圆上,然后顺时针查找第一台服务器,找到了就将该key对应的value存到这台服务器上,如果顺时针查找完还没有找到对应的服务器,则选择第一台服务器保存value值。
当我们下次有get请求来的时候,采用同样算法计算key对应的哈希值,就能找到存储该value的服务器了。
3.4 memcached的二阶段Hash
当我们往缓存里面写入一个数据的时候,memecached会首先根据key算出对应的hash值,找到对应的服务器编号,这是第一个hash,当我们确定好对应的服务器编号之后,memcached通过socket在memcached集群里面找到对应的memcached服务器,将我们的数据写入到服务器chunk中,这是第二个hash。同理,当我们get数据的时候,第一个hash采用相同的算法算出key对应的hash值,自然能找到对应的服务器获取缓存的数据
这个地方需要注意的是memecached采用的是一致性hash算法,而不是传统的余数hash。
一致性Hash算法通过一个叫做一致性Hash环的数据结构实现Key到缓存服务器的Hash映射:下面是一个草图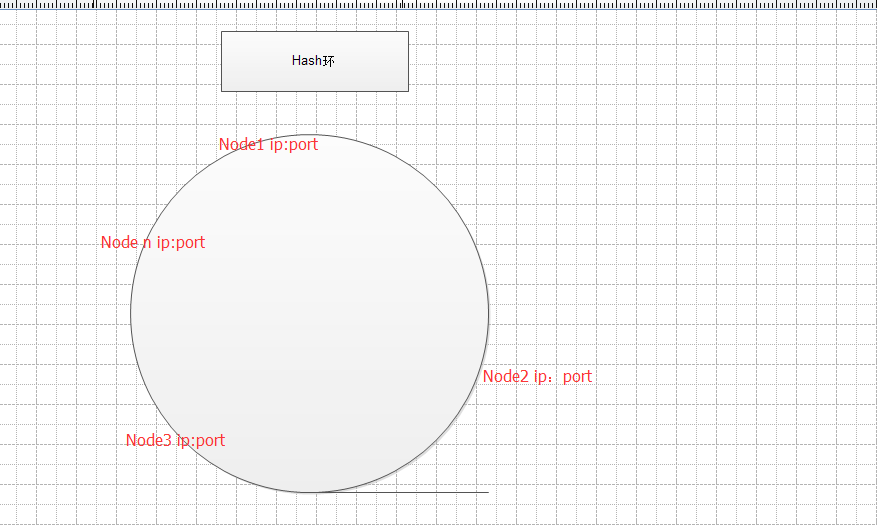
根据各个服务器节点名称的Hash值将缓存服务器节点放置在这个Hash环上,然后根据需要缓存的数据的Key值计算得到其Hash值,然后在Hash环上顺时针查找这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射,然后保存value即可。
但是一致性Hash也有不好的地方,因为我们在查询的时候,如果节点太多,比如上W个节点,那么我们很有可能会依次循环上W次才能找到该节点,这回给网络带来很大的负载。
四:JAVA客户端简单操作实现
目前memcached的Java客户端有几种,下面使用的是memcache client。
工具类:
package com.memcached.util;
import java.util.Date;
import java.util.Map;
import com.danga.MemCached.MemCachedClient;
import com.danga.MemCached.SockIOPool;
/**
* memcached的基本操作类的封装
*
* @author tanjie
*
*/
public class MemcachedUtil {
private MemcachedUtil() {
}
private static MemCachedClient memCachedClient = new MemCachedClient();
private static MemcachedUtil memcachedUtil = new MemcachedUtil();
/**
* 设置与缓存服务器的连接池
*/
static {
String[] servers = { "192.168.8.88:10000" };// Ip地址和端口号
// 权重
Integer[] weights = { 3 };
// 获取socket连接池的实例对象
SockIOPool pool = SockIOPool.getInstance();
pool.setServers(servers);
//设置连接池可用cache服务器的权重,和server数组的位置一一对应
pool.setWeights(weights);
// 设置初始连接数、最小、最大连接数以及最大处理时间
pool.setInitConn(5);
pool.setMinConn(5);
pool.setMaxConn(250);
pool.setMaxIdle(1000 * 60 * 60 * 6);
// 设置主线程的睡眠时间
pool.setMaintSleep(30);
// 设置TCP的参数,连接超时等
pool.setNagle(false);
pool.setSocketTO(3000);
pool.setSocketConnectTO(0);
// 初始化连接池
pool.initialize();
// 设置序列化,因为java的基本类型不支持序列化,在确定cache的数据类型是string的情况下设为true,可以加快处理速度
memCachedClient.setPrimitiveAsString(true);
}
public Object get(String key) {
return memCachedClient.get(key);
}
public static MemcachedUtil getInstance() {
return memcachedUtil;
}
//如果key不存在,就增加,如果存在,就覆盖
public boolean add(String key, Object value) {
return memCachedClient.add(key, value);
}
public boolean add(String key, Object value, Date expiryDate) {
return memCachedClient.add(key, value, expiryDate);
}
//如果key不存在,报错
public boolean replace(String key, Object value) {
return memCachedClient.replace(key, value);
}
public boolean replace(String key, Object value, Date expiry) {
return memCachedClient.replace(key, value, expiry);
}
public boolean delete(String key){
return memCachedClient.delete(key);
}
public boolean delete(String key, Date expiry){
return memCachedClient.delete(key, expiry);
}
public boolean delete (String key, Integer hashCode, Date expiry){
return memCachedClient.delete(key, hashCode, expiry);
}
//如果key存在,则失败
public boolean set(String key,Object value){
return memCachedClient.set(key, value);
}
public boolean set(String key,Object value,Integer hashCode){
return memCachedClient.set(key, value, hashCode);
}
//cache计数
public boolean storeCounter(String key,long value){
return memCachedClient.storeCounter(key, value);
}
public long incr(String key,long value){
return memCachedClient.incr(key, value);
}
//根据多个key获取对象
public Map<String,Object> getObjects(String[] keys){
return memCachedClient.getMulti(keys);
}
//清空对象
public boolean flush(){
return memCachedClient.flushAll();
}
//清空缓存对象,servers表示批量清空哪些机器的缓存
public boolean flushBaseTime(String[] servers){
return memCachedClient.flushAll(servers);
}
//获取服务器状态
public Map<String,Map<String,String>> getStats(){
return memCachedClient.stats();
}
//获取各个slab里item的数量
public Map<String,Map<String,String>> getStatsItem(){
return memCachedClient.statsItems();
}
}
实体类:
package com.memcached.vo;
import java.io.Serializable;
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String userId;
private String userName;
private String adder;
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getAdder() {
return adder;
}
public void setAdder(String adder) {
this.adder = adder;
}
}
测试类:
package com.memcached.test;
import java.util.Map;
import org.junit.After;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import com.memcached.util.MemcachedUtil;
import com.memcached.vo.User;
public class MemcachedTest {
private User user;
private MemcachedUtil cache;
@Before
public void setUp(){
user = new User();
user.setAdder("重庆");
user.setUserId("123");
user.setUserName("张三");
cache = MemcachedUtil.getInstance();
// 如果不存在 这个key的对象, add将会存储一个对象到cache中
cache.add("user", user);
cache.add("hello","memcached");
}
@Test
public void test(){
MemcachedUtil cache = MemcachedUtil.getInstance();
System.out.println("从缓存中获取数据:" + cache.get("hello"));
User cacheUser = (User) cache.get("user");
System.out.println(cacheUser.getUserId());
System.out.println(cacheUser.getUserName());
System.out.println(cacheUser.getAdder());
Assert.assertEquals(user.getUserId(), cacheUser.getUserId());
}
@Test
public void testDelete(){
MemcachedUtil cache = MemcachedUtil.getInstance();
System.out.println("从缓存中获取数据:" + cache.get("hello"));
cache.delete("hello");
System.out.println("再次从缓存中获取数据:" + cache.get("hello"));
}
@Test
public void testReplace(){
MemcachedUtil cache = MemcachedUtil.getInstance();
System.out.println("从缓存中获取数据:" + cache.get("hello"));
User cacheUser = (User) cache.get("user");
System.out.println("第一次从缓存里面获取user:" + cacheUser.getUserId());
user = new User();
user.setUserId("replaceId");
// 只有当存在指定key对象的时候 replace会覆盖已有对象
cache.replace("user", user);
User cacheUser2 = (User) cache.get("user");
System.out.println("再次从缓存中获取数据:" + cacheUser2.getUserId());
}
@Test
public void testGetStats(){
MemcachedUtil cache = MemcachedUtil.getInstance();
Map<String,Map<String,String>> map = cache.getStatsItem();
for(final Map.Entry<String, Map<String,String>> cacheMap : map.entrySet()){
System.out.println(cacheMap.getKey());
Map<String,String> maps = cacheMap.getValue();
for(final Map.Entry<String, String> valueMap : maps.entrySet()){
System.out.println("key:" + valueMap.getKey() + ",value:" +valueMap.getValue() );
}
}
}
@After
public void kill(){
user = null;
cache = null;
}
}
分别运行后结果如下:
test():
从缓存中获取数据:memcached 123 张三 重庆testDelete():
从缓存中获取数据:memcached 再次从缓存中获取数据:nulltestReplace():
从缓存中获取数据:memcached 第一次从缓存里面获取user:123 再次从缓存中获取数据:replaceIdtestGetStats():
ip:10000 key:items:4:evicted_nonzero,value:0 key:items:1:evicted_unfetched,value:0 key:items:1:evicted_time,value:0 key:items:1:expired_unfetched,value:0 key:items:4:tailrepairs,value:0 key:items:1:number,value:1 key:items:4:crawler_items_checked,value:0 key:items:1:lrutail_reflocked,value:0 key:items:1:reclaimed,value:0 key:items:4:crawler_reclaimed,value:0 key:items:1:evicted_nonzero,value:0 key:items:4:outofmemory,value:0 key:items:4:age,value:0 key:items:4:evicted,value:0 key:items:1:evicted,value:0 key:items:4:lrutail_reflocked,value:0 key:items:1:tailrepairs,value:0 key:items:4:evicted_time,value:0 key:items:1:age,value:0 key:items:1:crawler_reclaimed,value:0 key:items:4:reclaimed,value:0 key:items:1:outofmemory,value:0 key:items:1:crawler_items_checked,value:0 key:items:4:expired_unfetched,value:0 key:items:4:evicted_unfetched,value:0 key:items:4:number,value:1其实memcached客户端的方法都大同小异,只是各个客户端所特有的特性不一样罢了,这就看大家在实际生产中的具体需求了。