HBase结合MapReduce批量导入
2016年5月14日13:17:05
HBase结合MapReduce批量导入
作者:数据分析玩家
Hbase是Hadoop生态体系配置的数据库,我们可以通过HTable api中的put方法向Hbase数据库中插入数据,但是由于put效率太低,不能批量插入大量的数据,文本将详细介绍如何通过MapReduce运算框架向Hbase数据库中导入数据。
开篇先介绍业务场景:将电信手机上网日志中的数据导入到Hbase数据库中,将部分数据以及相应字段描述列出:
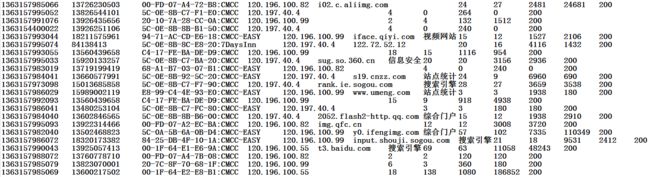
图片格式描述:
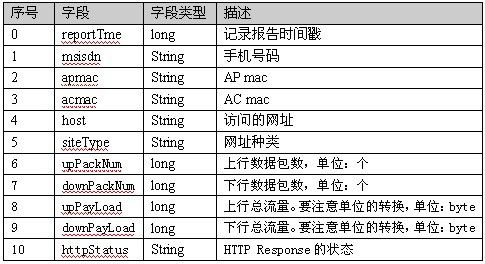
先介绍一个日期格式的转换:
public class TestDate
{
public static void main(String[] args)
{
Date d = new Date();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String time = df.format(d);
System.out.println(time);
}
}
/*2016-05-14 13:32:24*/ 在Java当中,我们经常利用SimpledateFormat这个类将给定的日期转化成指定的格式。
接下来在归纳一下Hbase结合MapReduce批量导入数据的时候,在代码当中应该注意的事项:
①MyReducer类继承的是TableReduce类,而不在是MapReduce中常用的Reducer类
②<k3,v3>的数值类型没有什么用,通常将k3的数值类型设置为NullWritable即可
③只设置map函数的输出类型,不在设置reduce函数的输出类型,因为②的原因
④指定对输出文件格式化处理的类改为TableOutputFormat,而不在是TextOutputFormat
⑤输出文件的路径改为指定的表名,在Configuration中进行设定,而不在是path的方式
⑥如果想过jar包的方式运行程序,貌似还需要加入什么jar包,我没有整出来。
接下来将贴出我在编程的时候第一次写出的业务代码:当然遇到了很多的问题。
package IT01;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class HbaseApp
{
public static String path1 = "hdfs://hadoop80:9000/FlowData.txt";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("hbaser.rootdir","hdfs://hadoop80:9000/hbase");
conf.set("hbase.zookeeper.quorum","hadoop80");
conf.set(TableOutputFormat.OUTPUT_TABLE,"wlan_log");//在这里需要指定表的名字:相当于输出文件的路径
conf.set("dfs.socket.timeout","2000");
Job job = new Job(conf,"HbaseApp");
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
// job.setOutputKeyClass(Text.class);
// job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TableOutputFormat.class);
// FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text>
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
String[] splited = v1.toString().split("\t");
String reportTime = splited[0];
String msisdn = splited[1];
Date date = new Date(Long.parseLong(reportTime));
String time = DateConvert.dateParse(date);
String rowkey = msisdn+":"+time;//获取到行健
context.write(new Text(rowkey),new Text(v1.toString()));
}
}
public static class MyReducer extends TableReducer<Text, Text, NullWritable>
{
protected void reduce(Text k2, Iterable<Text> v2s,Context context)throws IOException, InterruptedException
{
for (Text v2 : v2s)
{
String[] splited = v2.toString().split("\t");
/**添加记录的时候需要指定行健、列族、列名、数值***/
Put put = new Put(k2.toString().getBytes());
put.add("cf".getBytes(),"reportTime".getBytes(), splited[0].getBytes());
put.add("cf".getBytes(),"msisdn".getBytes(), splited[1].getBytes());
put.add("cf".getBytes(),"apmac1".getBytes(), splited[2].getBytes());
put.add("cf".getBytes(),"apmac2".getBytes(), splited[3].getBytes());
put.add("cf".getBytes(),"host".getBytes(), splited[4].getBytes());
put.add("cf".getBytes(),"sitetype".getBytes(), splited[5].getBytes());
put.add("cf".getBytes(),"upPackNum".getBytes(), splited[6].getBytes());
put.add("cf".getBytes(),"downPackNum".getBytes(), splited[7].getBytes());
put.add("cf".getBytes(),"upPayLoad".getBytes(), splited[8].getBytes());
put.add("cf".getBytes(),"downPayLoad".getBytes(), splited[9].getBytes());
put.add("cf".getBytes(),"httpstatus".getBytes(), splited[10].getBytes());
context.write(NullWritable.get(),put);
}
}
}
}
class DateConvert
{
public static String dateParse(Date date)
{
SimpleDateFormat df = new SimpleDateFormat("yyyyMMddhhmmss");//构造一个日期解析器
return df.format(date);
}
}程序运行完之后:显示如下异常NumberFormatException
显示的是数字格式异常, 于是我在map函数当中又加了一个throws NumberFormatException
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException,NumberFormatException
{
String[] splited = v1.toString().split("\t");
String reportTime = splited[0];
String msisdn = splited[1];
Date date = new Date(Long.parseLong(reportTime));
String time = DateConvert.dateParse(date);
String rowkey = msisdn+":"+time;//获取到行健
context.write(new Text(rowkey),new Text(v1.toString()));
}但是这样我发现也不对,因为当我追踪Mapp这个类的源代码时,我发现父类的map方法并没有抛出NumberFormatException这个异常,根据子类重写方法抛出异常的范围不能大于父类被重写方法抛出异常的范围,我又将上面这段代码用try——catch这种异常处理方式进行处理:
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
try
{
String[] splited = v1.toString().split("\t");
String reportTime = splited[0];
String msisdn = splited[1];
Date date = new Date(Long.parseLong(reportTime));
String time = DateConvert.dateParse(date);
String rowkey = msisdn+":"+time;//获取到行健
context.write(new Text(rowkey),new Text(v1.toString()));
}catch(Exception e)
{
Counter counter = context.getCounter("NumberExceptionNum", "num");
counter.increment(1L);
}
}当我将代码改成这样的时候,此时程序并没有显示抛出NumberFormatException这个异常,说明异常得到了处理,但是当我去查看Hbase数据的时候,发现HDFS中的日志数据并没有导入到Hbase数据库中,于是我又查看了一下MapReduce的运行日志:

也就是我的22行数据在map函数中当中并没有输出,这个问题就匪夷所思了,为什么22行数据都会抛出数字格式异常呢,而且都没有输出,于是我想到可能是SimpleDateFormat这个类的问题,于是我又开始各种百度,发现网上很多文章都是批判这个类的,最终终于找到了问题的解决方案,用trim()这个方法去除字符串前后的空格即可。
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
try
{
String[] splited = v1.toString().split("\t");
String reportTime = splited[0].trim();
String msisdn = splited[1].trim();
Date date = new Date(Long.parseLong(reportTime));
String time = DateConvert.dateParse(date);
String rowkey = msisdn+":"+time;//获取到行健
context.write(new Text(rowkey),new Text(v1.toString()));
}catch(Exception e)
{
Counter counter = context.getCounter("NumberExceptionNum", "num");
counter.increment(1L);
}
}于是我又开始运行程序,但是当我运行完之后,从MapReduce的计数器当中,我发现第一条数据文本并没有导入:因为数字格式异常的这个原因估计在运行过程中被终止了。下面是计数器的显示:
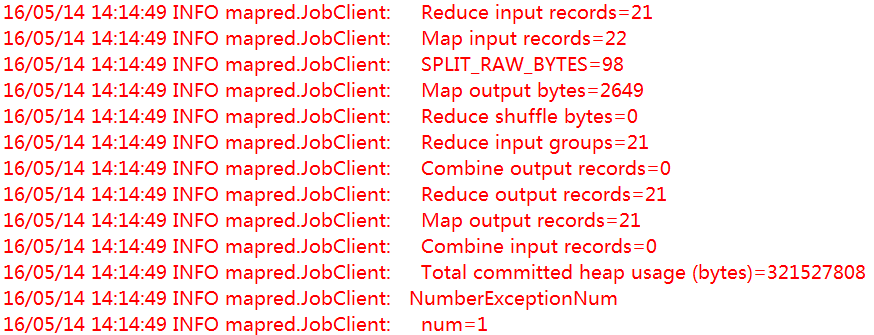
于是我又想到了一个解决方案,将第一条数据多复制一条即可,然后重写将数据上传到HDFS中。
此时在一次 运行程序,显示正确,此时数据也全部导入到Hbase数据库中。

Hbase中数据查看核实:
将HDFS中的数据通过MapReduce导入到Hbase数据库时,总结如下:
核心步骤:先将数据文件上传到HDFS,然后用MapReduce进行处理,将处理后的数据插入到 hbase中
注意事项:
1>子类重写方法抛出异常的范围不能大于父类被重写方法抛出异常的范围
2>用trim()这个方法可以去除字符串前后的空格,换行符。
3>既然第一条数据总是显示数字格式异常,将第一条数据复制为2份即可。