Zeppelin对Spark进行交互式数据查询和分析
Zeppelin是一个Web笔记形式的交互式数据查询分析工具,可以在线用scala和SQL对数据进行查询分析并生成报表。Zeppelin的后台数据引擎可以是Spark(目前只有Spark),开发者可以通过实现更多的解释器来为Zeppelin添加数据引擎。
Zeppelin的数据可视化能力很赞,下面是Zeppelin自带的Tutorial的显示效果:
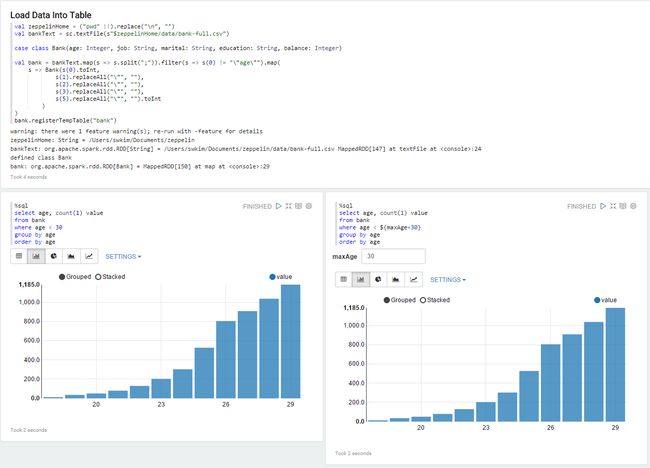
安装使用
Zeppelin的安装方式是从源码编译,编译步骤比较简单,编译完成后就可以直接运行了。官方给出的操作系统平台是OSX和CentOS6。亲测CentOS 6可以用,windows下面稍作改动也可以用。
目前Zeppelin还在起步阶段,master上代码的版本号是0.5.0,而官网上的文档内容基本对应的还是0.4.0的代码,至于youtube上的那个视频demo,估计是更早期的版本了。不过没关系,Zeppelin的UI比较好用,上手没有什么难度。
在安装试玩Zeppelin之前,需要注意的是
- Zeppelin支持Spark的local mode,所以可以直接编译运行,不用事先搭好一个Spark集群。
- Zeppelin目前还不支持Spark 1.2,所以如果想测试集群模式,要选择1.1.x系列的Spark。
- Zeppelin默认会使用8080作为web端口,并且会占用8081端口作为web socket通信的端口。如果端口冲突,可以设置环境变量ZEPPELIN_PORT来修改端口。
Zeppelin启动之后,可以看到Zeppelin本身提供的Tutorial。点击“Create new note”创建新的笔记,新创建的笔记默认以随机串命名,用户可以对笔记名称进行修改。
下面是一个用scala从hdfs上读取数据,然后用sql进行分析的例子
val bankText = sc.textFile("hdfs://localhost:19000/home/qixia/zeppelin/bank/bank-full.csv") case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer) val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map( s=>Bank(s(0).toInt, s(1).replaceAll("\"", ""), s(2).replaceAll("\"", ""), s(3).replaceAll("\"", ""), s(5).replaceAll("\"", "").toInt ) ) bank.registerTempTable("bank")
进阶配置
Zeppelin的工作方式和Spark的Thrift Server很像,都是向Spark提交一个应用(Application),然后每一个查询对应一个stage。
因此,在启动Zeppelin前,可以通过配置环境变量ZEPPELIN_JAVA_OPTS来对即将启动的Spark driver进行配置,例如“-Dspark.executor.memory=8g -Dspark.cores.max=64”。
常见问题
一. Spark的版本不匹配。Zeppelin在编译的时候是需要指定Spark的版本的,所以当Zeppelin的Spark版本,和你连接的Spark集群的版本不一致时,就会出现下面的异常。
ERROR [2015-03-13 09:40:22,508] ({sparkDriver-akka.actor.default-dispatcher-22} Slf4jLogger.scala[apply$mcV$sp]:66) – org.apache.spark.storage.BlockManagerId; local class incompatible: stream classdesc serialVersionUID = 2439208141545036836, local class serialVersionUID = 1677335532749418220
java.io.InvalidClassException: org.apache.spark.storage.BlockManagerId; local class incompatible: stream classdesc serialVersionUID = 2439208141545036836, local class serialVersionUID = 1677335532749418220
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:604)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1601)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1514)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1750)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1347)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1964)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1888)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1771)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1347)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:369)
at akka.serialization.JavaSerializer$$anonfun$1.apply(Serializer.scala:136)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57)
at akka.serialization.JavaSerializer.fromBinary(Serializer.scala:136)
at akka.serialization.Serialization$$anonfun$deserialize$1.apply(Serialization.scala:104)
at scala.util.Try$.apply(Try.scala:161)
解决方法有两个:
- 编译时候指定对应的版本;如果是自己编译的Spark,就用mvn install把Spark的jar都安装到本地的maven库,然后在编译zeppelin时指定自己的Spark版本即可S,例如“-Dspark.version=1.1.0-SNAPSHOT”。
- 直接替换{Zeppelin Home}\interpreter\spark下面有关spark的jar包,把”datanucleus-*.jar”和“spark-*.jar”都替换掉。
二. 访问HDFS时,出现异常“class org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$AppendRequestProto overrides final method getUnknownFields.()Lcom/google/protobuf/UnknownFieldSet;”
解决方法是,删掉{Zeppelin Home}\interpreter\spark下面的protobuf*.jar,换成HDFS使用的Protobuf的版本。