Oracle Database 12c In-Memory 基本原理与简介
概要
Database In-Memory是Oracle数据库的选项,类似于RAC,ADG,发布于12.0.1.2。
它的主要目的是利用内存的速度和优化的列格式来加速分析。以下我们用DBIM或IM作为Database In-Memory的缩写。

Oracle Database In-Memory 选件
行格式与列格式
传统的数据库概念中,行式数据库适合于OLTP的DML操作,如Oracle, Mysql;而列式数据库适合于分析,如Sybase IQ, SAP HANA。
而在一个混合负载的环境中,就会面临两难的选择。
DBIM在Oracle传统的行式存储之外提供了内存中的列式存储,然后自动的为用户访问选择后端的行式或列式存储,从而解决了此难题。
换句话说,在磁盘上只有一份数据,而在内存中则存在行式的Cache和列式的IM内存数据。
新的IM存储不会增加双倍的内存需求,首先因为我们无需将所有的列式数据都载入内容,其次内存中列式数据可以压缩,而且由于重复值较多,压缩的比率也较高。
增加了DBIM,通常内存需求会增加20%,具体可以使用In-Memory Advisor计算。
虽然列式数据适合于只读的情形,但并不意味数据不可修改,数据修改后,DBIM自动维护数据的一致性,自动在后台刷新列式存储,这一切对于应用都是透明的。
再次强调,列式数据不是Cache,因此也就没有Cache中Aging的概念。加载时需要将指定列的所有行数据加载,而不能选择某些行。
内存中列存储
DBIM在内存中需要预留空间,属于SGA中的静态池分,是纯列式存储。列存储不会取代缓冲区缓存,而是作为一种补充,以便数据现在可同时以行格式和列格式存储在内存中。
通过INMEMORY_SIZE控制DBIM内存的大小,至少为100M,当其大于0时,启用DBIM功能。
作为静态池,对 INMEMORY_SIZE 参数所做的任何更改在重启数据库实例后才会生效。
内存中区域可分为两个池:一个 1MB 池,用于存储填充到内存中的实际列格式数据,称为In Memory Compression Units (IMCUs);一个 64K 池,用于存储填充到 IM 列存储的对象的元数据以及交易的状态, 称为 Snapshot Metadata Units (SMUs)。当数据被修改是,SCU可以记录哪些列式数据是过期的,需要修改。
填充内存中列存储
填充内存中列存储又称为populate。DBIM为表和物化视图添加了一个新的 INMEMORY 属性,具有 INMEMORY 属性的对象可以加载到 IM 列存储。
可以在表空间、表、(子)分区或物化视图上指定 INMEMORY 属性。可以通过排除法的方式选择部分列和部分分区,但不能选择部分行。
ALTER TABLESPACE ts_data INMEMORY; -- 所有表空间中的表
ALTER TABLE sales INMEMORY; -- 表的所有列
ALTER TABLE sales INMEMORY NO INMEMORY(prod_id); -- 表的所有列,除去prod_id
ALTER TABLE sales MODIFY PARTITION SALES_Q1_1998 NO INMEMORY; -- 表的所有分区,除去SALES_Q1_1998分区IM 列存储通过一组称为工作进程 (ora_w001_orcl) 的后台进程进行填充。填充时,数据库可完全访问。
而其它厂商的纯内存中数据库,需要等到所有数据都填充到内存中后,才可访问数据库,但这会引起严重的可用性问题。
填充是一种流式机制,填充的同时对数据采用列格式并进行压缩。
与磁盘上的表空间由多个区段构成一样,IM 列存储由多个内存中压缩单元 (IMCU) 构成。
每个工作进程分配自己的IMCU,并在其中填充部分数据库块。在填充过程中,数据不以任何特定的方式进行排序或排列。以在行格式中的显示顺序读取数据。
在数据库打开后立即以按优先级顺序将对象填充到 IM 列存储,或首次扫描(查询)对象后将其填充到 IM 列存储。对象的加载顺序通过关键字 PRIORITY 进行控制,关键字 PRIORITY 有五个级别。默认 PRIORITY 为 NONE,这表示只在首次扫描对象后才将其填充。

对于索引组织表 (IOT)和集群表,由于其特性是面向OLTP的,DBIM不支持,另外如LONG何out-of-line LOB也不支持。
目前DBIM还无法再ADG的standby实例中使用,未来会支持,这样可以利用灾备站点做分析,提升其ROI。
内存中压缩
通常只将压缩视为节省空间的一种机制。但是,填充到 IM 列存储的数据是使用一组新压缩算法进行压缩的,这谢新压缩算法不仅有助于节省空间,而且还能提高查询性能。这种新的 Oracle 内存中压缩格式允许直接对压缩的列执行查询。这意味着,将对非常少量的数据执行所有扫描和筛选操作。仅当结果集需要数据时才解压缩数据。 使用关键字 MEMCOMPRESS(INMEMORY 属性的分子句)指定内存中压缩。有六个级别,每个级别提供不同的压缩级别和性能。
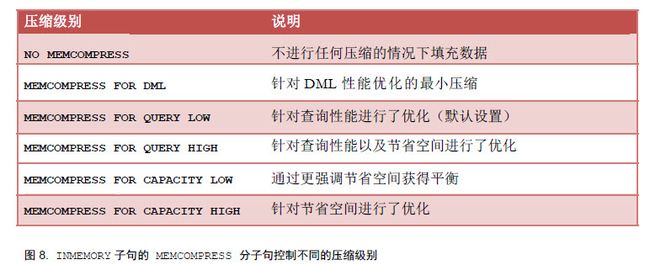
默认情况下,使用 FOR QUERY LOW 选项压缩数据,该选项提供最佳的查询性能。这种方式的压缩对于性能影响不大的原因是其使用的是字典压缩,其实就是重复数据删除。
可以对一个表内的各个列或各个分区使用不同的压缩技术,例如:
CREATE TABLE employees ( c1 NUMBER, c2 NUMBER, c3 VARCHAR2(10), c4 CLOB ) INMEMORY MEMCOMPRESS FOR QUERY NO INMEMORY(c4) INMEMORY MEMCOMPRESS FOR CAPCITY HIGH(c2);使用何种压缩可以使用Oracle Compression Advisor (DBMS_COMPRESSION)来评估。
内存中扫描
内存中扫描速度快取决于以下因素。
列式存储
这时最根本的,分析只访问部分列,这样避免了大量I/O,好处类似于分区,只不过是垂直分区。
Storage Index
在Exadata中已经出现过此技术,在DBIM中原理是一样的。内存中存储索引跟踪 IMCU 中各列的最小值和最大值,好处类似于分区修剪。

存储索引自动的维护在内存中,不过每次重启不知道是否需要重新算。
SIMD 向量处理
SIMD又称为single instruction processing multiple data。SIMD并非Oracle的技术,最初用于计算机生成动画和高性能计算。
好处是SIMD 向量处理允许发出一条 CPU 指令来估算一组列值,而不是一次估算列中的一个条目
内存中 Join
除了内存速度外, Join的快取决于Bloom Filter,Bloom Filter于Oracle Database 10g引入。
bloom filter的原理需要解释一下:
A bloom filter transforms a join to a filter that can be applied as part of the scan of the fact table. Bloom filters were originally introduced in Oracle Database 10g to enhance hash join performance and are not specific to Oracle Database In-Memory. However, they are very efficiently applied to columnar data via SIMD vector processing.
Here is a brief description of how they work: When two tables are joined via a hash join, the first table (typically the smaller table) is scanned and the rows that satisfy the ‘where’ clause predicates (for that table) are used to create a hash table. During the hash table creation a bit vector or bloom filter is also created based on the join column. The bit vector is then sent as an additional predicate to the second table scan. After the where clause predicates have been applied to the second table scan, the resulting rows will have their join column hashed and it will be compared to values in the bit vector. If a match is found in the bit vector that row will be sent to the hash join. If no match is found then the row will be discarded. On Exadata the bloom filter or bit vector is passed as an additional predicate so it will be offloaded to the storage cells making bloom filtering even more efficient.
这里的关键是vector table是根据join的column计算的,如果有多个join则有多个vector table。可以参考Bloom Filters by Example
内存中 Aggregation
分析式查询通常需要的不仅仅是简单筛选和联接。它们需要复杂的聚合和汇总。Oracle Database 12.1.0.2 中引入了一个新优化器转换(称为 Vector Group By),能够确保可使用有效利用 CPU 的新算法处理更复杂的分析查询。
典型的Aggregation指类似于Group By之类的语句,其它还包括SUM, AVG, MIN, MAX等。
DML 和内存中列存储
分析的数据很少会改动,但在混合负载的环境下,如果数据修改了,对于DBIM会有何影响?
对于批量数据加载,DBIM建议和分区以前使用,从而可以提供最佳性能。
对于DML修改,数据变化在行式缓存中修改,这和以前一样,然后在SCU(前面提到过)中会标记DBIM中的哪些数据是陈旧的,当访问到这些数据时就会结合日志返回最新的数据,后续在合适的时候会更新DBIM中的数据。
IMCU 中的陈旧条目越多,IMCU 的扫描速度就越慢。因此,当 IMCU 中的陈旧条目数达到陈旧程度阈值时,Oracle 数据库将重新填充 IMCU。
IMCO (内存中协调器)每隔两分钟就唤醒一次,检查是否有任何填充任务需要完成。
IM 列存储保持事务一致性带来的开销随应用程序而异,具体取决于多种因素,其中包括:更改速度、为表选择的内存中压缩级别、更改行的位置以及执行的操作类型。具有较高压缩级别的表将比具有较低压缩级别的表产生的开销要多。
对于具有高 DML 速率的表,建议使用 MEMCOMPRESS FOR DML,此外,如果可能,还建议使用分区在表内定位更改。
总之对应用是透明的,数据也是一致的。原理看以下两张图就足够了。

RAC 上的内存中列存储
RAC 环境中的每个节点都可以有其自己独立的 IM 列存储。对于不需要 IM 列存储的任何 RAC 节点,应将 INMEMORY_SIZE 参数设为 0。
强烈建议将每个 RAC 节点的 IM 列存储设置为相同的大小。
可以在每个节点上填充完全不同的对象,也可以在集群的所有 IM 列存储间分布(DISTRIBUTE)较大的对象。
还可以在每个节点的 IM 列存储中存储相同的对象(DUPLICATE,仅限工程化系统)。
对象在集群中各个 IM 列存储间的分布通过 INMEMORY 属性的两个附加分子句进行控制:DISTRIBUTE 和 DUPLICATE。
默认情况下,Oracle 基于使用的分区类型(如果有)决定在集群中分布对象的最佳方式。或者,可以指定 DISTRIBUTE BY ROWID RANGE 按 rowid 范围分布,指定 DISTRIBUTE BY PARTITION 将分区分布给不同的节点,或指定 DISTRIBUTE BY SUBPARTITION 将子分区分布给不同的节点。
RAC可以使用DISTRIBUTE来实现分布和并行处理,Exadata上的RAC可以再加上DUPLICATE实现容错和增加并行度。
DUPLICATE可以只复制到另一个RAC节点,或通过DUPLICATE ALL复制到所有的节点,不过复制和为维护一致性带来的开销应较大。
多租户环境中的内存中列存储
Oracle Multitenant 是一个新的数据库整合模型,在该模型中,多个可插拔数据库 (PDB) 整合在一个容器数据库 (CDB) 中。在保持单一数据库的多个隔离特性的同时,它还支持多个 PDB 共享一个通用 CDB 的系统全局区域 (SGA) 和后台进程。因此,多个 PDB 也共享一个 IM 列存储。
IM 列存储的总大小通过在 CDB 中设置 INMEMORY_SIZE 参数进行控制。通过设置每个 PDB 的 INMEMORY_SIZE 参数,来指定其能够使用的共享 IM 列存储的大小。并非给定 CDB 中的所有 PDB 都需要使用内存中列存储。一些 PDB 可以将 INMEMORY_SIZE 参数设为 0,这意味着它们根本不使用内存中列存储。
PDB 的 INMEMORY_SIZE 参数的总和无需小于或等于 CDB 的 INMEMORY_SIZE 参数的大小。PDB 可以过度使用 IM 列存储。允许过度使用可确保某个可插拔数据库关闭或拔出的情况下不浪费 IM 列存储的宝贵空间。由于 INMEMORY_SIZE 参数是静态的(需要数据库实例重启才能反映更改),最好允许 PDB 过度使用,以便可以使用 IM 列存储的所有空间。
但是,由于这种过度使用,一个 PDB 可能会抢占另一个 PDB 在 IM 列存储中的空间。如果不希望任何 PDB 长时间关闭或拔出,建议不采用过度使用。
控制 Oracle Database In-Memory 的使用
核心初始化参数
- INMEMORY_SIZE - 大于0时启用DBIM.该参数只能在系统级进行修改,且需要数据库重启才能生效
- INMEMORY_QUERY - 可以在会话级或系统级将 INMEMORY_QUERY 设置为 DISABLE,来禁用 IM 列存储。默认值为 ENABLE。
- INMEMORY_MAX_POPULATE_SERVERS - 可以启动的最大工作进程数通过 INMEMORY_MAX_POPULATE_SERVERS 进行控制,该参数默认设置为 0.5 X CPU_COUNT。减少工作进程数将减少填充过程中占用的 CPU 资源,但可能会延长填充 IM 列存储所花费的时间。
优化器提示
如 SELECT /+ NO_INMEMORY /
监视和管理 Oracle Database In-Memory
哪些对象位于内存中列存储中
存在两个新的 v 视图—v IM_SEGMENTS 和 v$IM_USER_SEGMENTS,这两个视图可指示目前填充到 IM 列存储的对象。
SQL> SELECT v.owner, v.segment_name name,
v.populate_status status, v.bytes_not_populated
FROM v$im_segments v;
OWNER NAME STATUS BYTES_NOT_POPULATED
---------- --------------- --------- -------------------
SSB DATE_DIM COMPLETED 0
SSB PART COMPLETED 0
SSB SUPPLIER COMPLETED 0
SSB LINEORDER STARTED 835780608
SSB CUSTOMER COMPLETED 0USER_TABLES
向 *_TABLES 字典表中添加了一个新的布尔型列(称为 INMEMORY),以指示对哪些表指定了 INMEMORY 属性。
SQL> SELECT table_name, cache, inmemory, inmemory_priority,
inmemory_distribute,inmemory_compression
FROM user_tables;
TABLE_NAME CACHE INMEMORY INMEMORY INMEMORY_DISTRI INMEMORY_COMPRESS
---------- -------------------- -------- -------- --------------- -----------------
DATE_DIM Y ENABLED NONE AUTO FOR QUERY LOW
LINEORDER Y ENABLED NONE AUTO FOR QUERY LOW
SUPPLIER Y ENABLED NONE AUTO FOR QUERY LOW
CUSTOMER Y ENABLED NONE AUTO FOR QUERY LOW
PART Y ENABLED NONE AUTO FOR QUERY LOW管理 IM 列存储填充的 CPU 占用
IM 列存储的初始填充是 CPU 密集型操作,可能会影响同时运行的其他负载的性能。可以使用 Resource Manager2 控制 IM 列存储填充操作的 CPU 使用,并根据需要更改操作的优先级。
参考
- Oracle Database In-Memory 中文白皮书
- Oracle Database In-Memory White Paper
- Oracle Database In-Memory Advisor Best Practice
- Oracle Database In-Memory Blog