Bluemix中的Apache Spark数据分析服务入门
Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速。Spark非常小巧玲珑,由加州伯克利大学AMP实验室的Matei为主的小团队所开发。使用的语言是Scala,项目的core部分的代码只有63个Scala文件,非常短小精悍。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为Mesos的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
创建服务实例
按以下步骤创建一个Apache Spark 服务的实例1、登录 Bluemix ,进入仪表板页面,单击“数据和分析”下的“使用数据”。
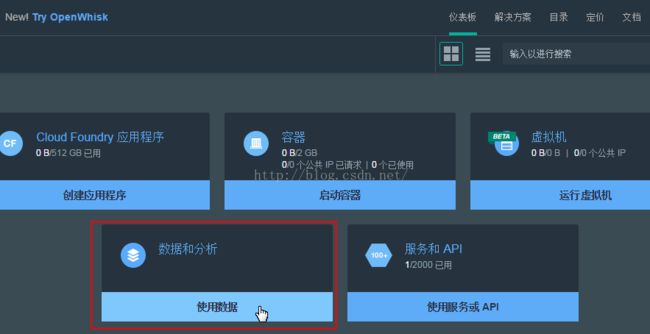
2、在左侧的标签中选择“Analytics”,然后点击下面的“New Instance”;
3、了解价格与服务概述,创建服务实例;
查看不同地区的价格,但我没有找到中国,难道中国还没有服务器?
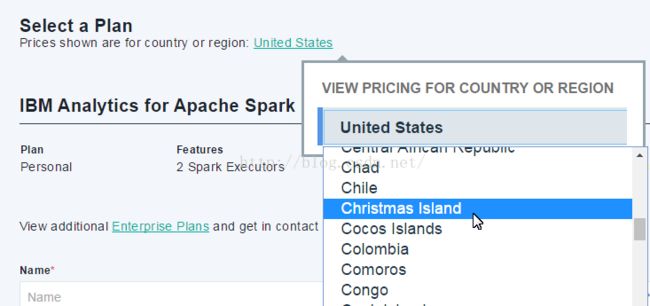
点击 Terms 可以查看服务描述

填写实例名称,然后点击“Create Instance”开始创建服务实例
4、实例创建成功后会返回到实例创建的引导页面,在Service下可以看到刚刚创建的Apache Spark服务,在Analytics的Instance下也可以看到刚刚创建的Apache Spark服务;
刚创建完成的时候,我返回到仪表盘去查看,发现没有,然后转到“Try the new Bluemix”找到了,以为仪表盘中不会显示,后来又打开仪表盘页面发现又有了,看样子是反应慢。
管理服务实例
在实例创建的引导页面,仪表盘,“Try the new Bluemix”等多个页面都可以查看并管理你的服务实例。

管理功能包括:
1、重命名、删除服务;
2、点击服务,可以进入服务功能的管理界面;
3、监视服务的使用情况,查看服务的使用历史记录;
4、使用笔记本电脑和Spark工作
5、运行Spark应用程序
6、查看和管理连接的应用程序或服务
单击“创建连接”可以将 spark test 连接到某个现有应用程序或兼容服务,这时你之前创建的应用都会列出来。
我还真是被搞晕了,“连接”这个管理功能从不同的地方进入管理页面有的有,有的没有!
7、服务凭证,可以查看,添加凭证,或复制凭证应用到你的应用中,凭证内容类似如下:
{
"credentials": {
"tenant_id": "s983-b882f590d2c0fc-b38a1adda111",
"tenant_id_full": "2e50d60b-0b9b-4b64-a983-b882f590d2c0_5b31a712-0086-4d32-96fc-b38a1sdda111",
"cluster_master_url": "https://169.54.219.20:8443",
"instance_id": "2e50d60b-0b9b-4b64-a983-b88ss590d2c0",
"tenant_secret": "f2f0ed85-b044-4c78-8da2-a245esda867a",
"plan": "ibm.SparkService.PayGoPersonal"
}
}
创建笔记本
要使用笔记本工作和开发,需要先创建笔记本;
笔记本电脑提供了一个交互式的计算环境中执行的数据来自不同来源的分析任务,让你在一个地方相结合的代码执行,丰富的文字,数学,情节和丰富的媒体。
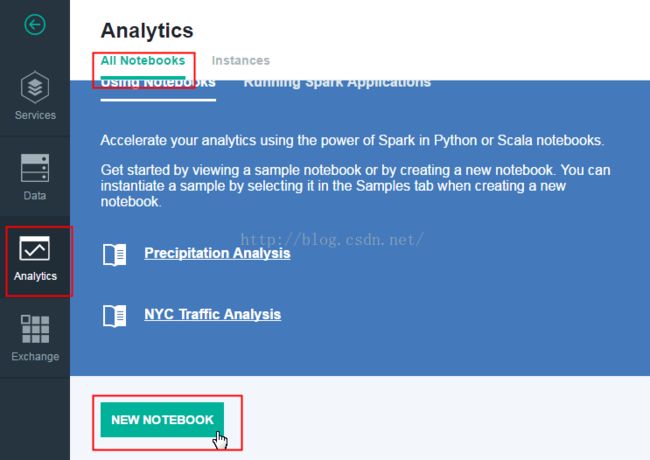
1、进入仪表盘页面,单击使用数据;
2、在打开的页面左侧选择:Analytics
3、单击“NEW NOTEBOOK”
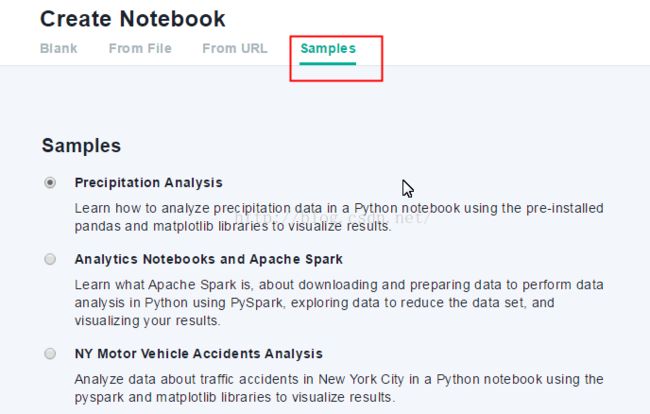
4、我们可以先从笔记本样本示例来浏览和学习,单击“Samples”标签,选择“Precipitation Analysis”,单击“Create NOTEBOOK”按钮
5、阅读并探索这个样本Python笔记本了解什么是可用的,以及如何加载数据,并使用它。
参考:
Apache Spark数据分析入门
Apache Spark 学习中心
Get Started in Bluemix