详解SQL集合运算
以前总是追求新东西,发现基础才是最重要的,今年主要的目标是精通SQL查询和SQL性能优化。
本系列【T-SQL基础】主要是针对T-SQL基础的总结。
概述:
本篇主要是对集合运算中并集、交集、差集运算基础的总结。
集合运算包含四种:
1.并集运算
2.交集运算
3.差集运算
下面是集合运算的思维导图:
在阅读下面的章节时,我们可以先把环境准备好,以下的SQL脚本可以帮助大家创建数据库,创建表,插入数据。
下载脚本文件:TSQLFundamentals2008.zip
一、集合运算
1.集合运算
(1)对输入的两个集合或多集进行的运算。
(2)多集:由两个输入的查询生成的可能包含重复记录的中间结果集。
(3)T-SQL支持三种集合运算:并集(UNION)、交集(INTERSECT)、差集(EXCEPT)
2.语法
集合运算的基本格式:
输入的查询1
<集合运算符>
输入的查询2
[ORDER BY]
3.要求
(1)输入的查询不能包含ORDER BY字句;
(2)可以为整个集合运算结果选择性地增加一个ORDER BY字句;
(3)每个单独的查询可以包含所有逻辑查询处理阶段(处理控制排列顺序的ORDER BY字句);
(4)两个查询 必须包含相同的列数;
(5)相应列必须具有兼容的数据类型。兼容个的数据类型:优先级较低的数据类型必须能隐式地转换为较高级的数据类型。比如输入的查询1的第一列为int类型,输入的查询2的第一列为float类型,则较低的数据类型int类型可以隐式地转换为较高级float类型。如果输入的查询1的第一列为char类型,输入的查询2的第一列为datetime类型,则会提示转换失败:从字符串转换日期和/或时间时,转换失败;
(6)集合运算结果中列名由输入的查询1决定,如果要为结果分配结果列,应该在输入的查询1中分配相应的别名;
(7)集合运算时,对行进行进行比较时,集合运算认为两个NULL相等;
(8)UNION支持DISTINCT和ALL。不能显示指定DISTINCT字句,如果不指定ALL,则默认使用DISTINCT;
(9)INTERSET和EXCEPT默认使用DISTINCT,不支持ALL。
二、UNION(并集)集合运算
1.并集的文氏图
并集:两个集合的并集是一个包含集合A和B中所有元素的集合。
图中阴影区域代表集合A与集合B的并集
2.UNION ALL集合运算
(1)假设Query1返回m行,Query2返回n行,则Query1 UNION ALL Query2返回(m+n)行;
(2)UNION ALL 不会删除重复行,所以它的结果就是多集,而不是真正的集合;
(3)相同的行在结果中可能出现多次。
3.UNION DISTINCT集合运算
(1)假设Query1返回m行,Query2返回n行,Query1和Query2有相同的h行,则Query1 UNION Query2返回(m+n-h)行;
(2)UNION 会删除重复行,所以它的结果就是集合;
(3)相同的行在结果中只出现一次。
(4)不能显示指定DISTINCT字句,如果不指定ALL,则默认使用DISTINCT。
(5)当Query1与Query2比较某行记录是否相等时,会认为取值为NULL的列是相等的列。
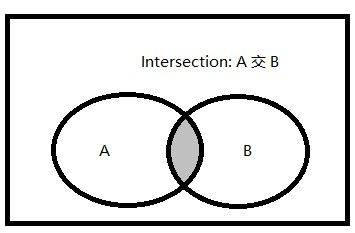
三、INTERSECT(交集)集合运算
1.交集的文氏图
交集:两个集合(记为集合A和集合B)的交集是由既属于A,也属于B的所有元素组成的集合。
图中阴影区域代表集合A与集合B的交集
2.INTERSECT DISTINCT集合运算
(1)假设Query1返回 m 行,Query2返回 n 行,Query1和Query2有相同的 h 行,则Query1 INTERSECT Query2返回 h 行;
(2)INTERSECT集合运算在逻辑上首先删除两个输入多集中的重复行(把多集变为集合),然后返回只在两个集合中都出现的行;
(3)INTERSECT 会删除重复行,所以它的结果就是集合;
(4)相同的行在结果中只出现一次。
(5)不能显示指定DISTINCT字句,如果不指定ALL,则默认使用DISTINCT。
(6)当Query1与Query2比较某行记录是否相等时,会认为取值为NULL的列是相等的列。
(7)用内联接或EXISTS谓词可以代替INTERSECT集合运算,但是必须对NULL进行处理,否则这两种方法对NULL值进行比较时,比较结果都是UNKNOWN,这样的行会被过滤掉。
3.INTERSECT ALL集合运算
(1)ANSI SQL支持带有ALL选项的INTERSECT集合运算,但SQL Server2008现在还没有实现这种运算。后面会提供一种用于T-SQL实现的替代方案;
(2)假设Query1返回 m 行,Query2返回 n 行,如果行R在Query1中出现了x次,在Query2中出现了y次,则行R应该在INTERSECT ALL运算之后出现minimum(x,y)次。
下面提供用于T-SQL实现的INTERSECT ALL集合运算:公用表表达式 + 排名函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
WITH
INTERSECT_ALL
AS
(
SELECT
ROW_NUMBER() OVER ( PARTITION
BY
country, region, city
ORDER
BY
(
SELECT
0
) )
AS
rownum ,
country ,
region ,
city
FROM
HR.Employees
INTERSECT
SELECT
ROW_NUMBER() OVER ( PARTITION
BY
country, region, city
ORDER
BY
(
SELECT
0
) )
AS
rownum ,
country ,
region ,
city
FROM
Sales.Customers
)
SELECT
country ,
region ,
city
FROM
INTERSECT_ALL
|
结果如下:
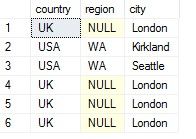
其中UK NULL London有四个重复行,
在排序函数的OVER字句中使用 ORDER BY ( SELECT <常量> )可以告诉SQL Server不必在意行的顺序。
四、EXCEPT(差集)集合运算
1.差集的文氏图
差集:两个集合(记为集合A和集合B)的由属于集合A,但不属于集合B的所有元素组成的集合。
图中阴影区域代表集合A与集合B的差集
2.EXCEPT DISTINCT集合运算
(1)假设Query1返回 m 行,Query2返回 n 行,Query1和Query2有相同的 h 行,则Query1 INTERSECT Query2返回 m - h 行,而Query2 INTERSECT Query1 返回 n - h 行
(2)EXCEPT集合运算在逻辑上先删除两个输入多集中的重复行(把多集转变成集合),然后返回只在第一个集合中出现,在第二个集合众不出现所有行。
(3)EXCEPT 会删除重复行,所以它的结果就是集合;
(4)EXCEPT是不对称的,差集的结果取决于两个查询的前后关系。
(5)相同的行在结果中只出现一次。
(6)不能显示指定DISTINCT字句,如果不指定ALL,则默认使用DISTINCT。
(7)当Query1与Query2比较某行记录是否相等时,会认为取值为NULL的列是相等的列。
(8)用左外联接或NOT EXISTS谓词可以代替INTERSECT集合运算,但是必须对NULL进行处理,否则这两种方法对NULL值进行比较时,比较结果都是UNKNOWN,这样的行会被过滤掉。
3.EXCEPT ALL集合运算
(1)ANSI SQL支持带有ALL选项的EXCEPT集合运算,但SQL Server2008现在还没有实现这种运算。后面会提供一种用于T-SQL实现的替代方案;
(2)假设Query1返回 m 行,Query2返回 n 行,如果行R在Query1中出现了x次,在Query2中出现了y次,且x>y,则行R应该在EXCEPT ALL运算之后出现 x - y 次。
下面提供用于T-SQL实现的EXCEPT ALL集合运算:公用表表达式 + 排名函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
WITH
INTERSECT_ALL
AS
(
SELECT
ROW_NUMBER() OVER ( PARTITION
BY
country, region, city
ORDER
BY
(
SELECT
0
) )
AS
rownum ,
country ,
region ,
city
FROM
HR.Employees
EXCEPT
SELECT
ROW_NUMBER() OVER ( PARTITION
BY
country, region, city
ORDER
BY
(
SELECT
0
) )
AS
rownum ,
country ,
region ,
city
FROM
Sales.Customers
)
SELECT
country ,
region ,
city
FROM
INTERSECT_ALL
|
结果如下:
五、集合运算的优先级
1.INTERSECT>UNION=EXCEPT
2.首先计算INTERSECT,然后从左到右的出现顺序依次处理优先级的相同的运算。
3.可以使用圆括号控制集合运算的优先级,它具有最高的优先级。
六、特殊处理
1.只有ORDER BY能够直接应用于集合运算的结果;
2.其他阶段如表运算符、WHERE、GROUP BY、HAVING等,不支持直接应用于集合运算的结果,这个时候可以使用表表达式来避开这一限制。如根据包含集合运算的查询定义个表表达式,然后在外部查询中对表表达式应用任何需要的逻辑查询处理;
3.ORDER BY字句不能直接应用于集合运算中的单个查询,这个时候可以TOP+ORDER BY字句+表表达式来避开这一限制。如定义一个基于该TOP查询的表表达式,然后通过一个使用这个表表达式的外部查询参与集合运算。
七、练习题
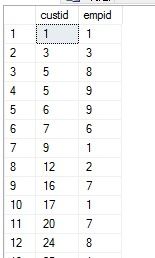
1.写一个查询,返回在2008年1月有订单活动,而在2008年2月没有订单活动的客户和雇员。
期望结果:
方案一:EXCEPT
(1)先用查询1查询出2008年1月份有订单活动的客户和雇员
(2)用查询2查询2008年2月份客户的订单活动的客户和雇员
(3)用差集运算符查询2008年1月有订单活动而2008年2月没有订单活动的客户和雇员
|
1
2
3
4
5
6
7
8
9
10
11
|
SELECT
custid ,
empid
FROM
Sales.Orders
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
EXCEPT
SELECT
custid ,
empid
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
|
方案二:NOT EXISTS
必须保证custid,empid不能为null,才能用NOT EXISTS进行查询,如果custid或empid其中有null值存在,则不能用NOT EXISTS进行查询,因为比较NULL值的结果是UNKNOWN,这样的行用NOT EXISTS查询返回的子查询的行会被过滤掉,所以最后的外查询会多出NULL值的行,最后查询结果中会多出NULL值的行。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
SELECT
custid ,
empid
FROM
Sales.Orders
AS
O1
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
AND
NOT
EXISTS (
SELECT
*
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
AND
custid = o1.custid
AND
empid = o1.empid )
ORDER
BY
O1.custid ,
O1.empid
|
如果我往Sales.Orders表中插入两行数据:
插入cutid=NULL,empid=1,orderdate='20080101'
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
INSERT
INTO
[TSQLFundamentals2008].[Sales].[Orders]
( [custid] ,
[empid] ,
[orderdate] ,
[requireddate] ,
[shippeddate] ,
[shipperid] ,
[freight] ,
[shipname] ,
[shipaddress] ,
[shipcity] ,
[shipregion] ,
[shippostalcode] ,
[shipcountry]
)
VALUES
(
NULL
,
1 ,
'20080101'
,
'20080101'
,
'20080101'
,
1 ,
1 ,
'A'
,
'20080101'
,
'A'
,
'A'
,
'A'
,
'A'
)
GO
|
插入cutid=NULL,empid=1,orderdate='20080201'
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
INSERT
INTO
[TSQLFundamentals2008].[Sales].[Orders]
( [custid] ,
[empid] ,
[orderdate] ,
[requireddate] ,
[shippeddate] ,
[shipperid] ,
[freight] ,
[shipname] ,
[shipaddress] ,
[shipcity] ,
[shipregion] ,
[shippostalcode] ,
[shipcountry]
)
VALUES
(
NULL
,
1 ,
'20080201'
,
'20080101'
,
'20080101'
,
1 ,
1 ,
'A'
,
'20080101'
,
'A'
,
'A'
,
'A'
,
'A'
)
GO
|
用方案一查询出来结果为50行,会把cutid=NULL,empid=1的行过滤掉
用方案二查询出来结果为51行,不会把cutid=NULL,empid=1的行过滤掉
用下面的方案可以解决上面的问题,需要处理cutid=NULL,或者empid=null的情况。返回50行
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
SELECT
custid ,
empid
FROM
Sales.Orders
AS
O1
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
AND
NOT
EXISTS (
SELECT
*
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
AND
( custid = o1.custid
AND
empid = o1.empid
)
OR
( o1.custid
IS
NULL
AND
custid
IS
NULL
AND
empid = o1.empid
)
OR
( o1.custid
IS
NULL
AND
custid
IS
NULL
AND
o1.empid
IS
NULL
AND
custid
IS
NULL
)
OR
( custid = o1.custid
AND
o1.empid
IS
NULL
AND
custid
IS
NULL
) )
|
2.写一个查询,返回在2008年1月和在2008年2月都有订单活动的客户和雇员。
期望结果:
方案一:INTERSECT
(1)先用查询1查询出2008年1月份有订单活动的客户和雇员
(2)用查询2查询2008年2月份客户的订单活动的客户和雇员
(3)用交集运算符查询2008年1月和2008年2月都有订单活动的客户和雇员
|
1
2
3
4
5
6
7
8
9
10
11
|
SELECT
custid ,
empid
FROM
Sales.Orders
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
INTERSECT
SELECT
custid ,
empid
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
|
方案二:EXISTS
必须保证custid,empid不能为null,才能用EXISTS进行查询,如果custid或empid其中有null值存在,则不能用EXISTS进行查询,因为比较NULL值的结果是UNKNOWN,这样的行用EXISTS查询返回的子查询的行会被过滤掉,所以最后的外查询会少NULL值的行,最后查询结果中会少NULL值的行。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
SELECT
custid ,
empid
FROM
Sales.Orders
AS
O1
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
AND
EXISTS (
SELECT
*
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
AND
custid = o1.custid
AND
empid = o1.empid )
ORDER
BY
O1.custid ,
O1.empid
|
如果我往Sales.Orders表中插入两行数据:
插入cutid=NULL,empid=1,orderdate='20080101'
插入cutid=NULL,empid=1,orderdate='20080201'
用方案一查询出来结果为6行,不会把cutid=NULL,empid=1的行过滤掉
用方案二查询出来结果为5行,会把cutid=NULL,empid=1的行过滤掉
用下面的方案可以解决上面的问题,需要处理cutid=NULL,或者empid=null的情况。返回6行。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
SELECT
custid ,
empid
FROM
Sales.Orders
AS
O1
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
AND
EXISTS (
SELECT
*
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
AND
( custid = o1.custid
AND
empid = o1.empid
)
OR
( o1.custid
IS
NULL
AND
custid
IS
NULL
AND
empid = o1.empid
)
OR
( o1.custid
IS
NULL
AND
custid
IS
NULL
AND
o1.empid
IS
NULL
AND
custid
IS
NULL
)
OR
( custid = o1.custid
AND
o1.empid
IS
NULL
AND
custid
IS
NULL
) )
|
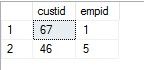
3.写一个查询,返回在2008年1月和在2008年2月都有订单活动,而在2007年没有订单活动的客户和雇员
期望结果:
方案一:INTERSECT + EXCEPT
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
SELECT
custid ,
empid
FROM
Sales.Orders
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
INTERSECT
SELECT
custid ,
empid
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
EXCEPT
SELECT
custid ,
empid
FROM
Sales.Orders
WHERE
orderdate >=
'20070101'
AND
orderdate <
'20080101'
|
方案二:EXISTS + NOT EXISTS
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
SELECT
custid ,
empid
FROM
Sales.Orders
AS
O1
WHERE
orderdate >=
'20080101'
AND
orderdate <
'20080201'
AND
EXISTS (
SELECT
*
FROM
Sales.Orders
WHERE
orderdate >=
'20080201'
AND
orderdate <
'20080301'
AND
( custid = o1.custid
AND
empid = o1.empid
)
OR
( custid = o1.custid
AND
custid
IS
NULL
AND
empid = o1.empid
)
OR
( custid = o1.custid
AND
custid
IS
NULL
AND
empid = o1.empid
AND
custid
IS
NULL
)
OR
( custid = o1.custid
AND
empid = o1.empid
AND
custid
IS
NULL
)
OR
( custid = o1.custid
AND
custid
IS
NULL
AND
empid = o1.empid
AND
custid
IS
NULL
) )
AND
NOT
EXISTS (
SELECT
*
FROM
Sales.Orders
WHERE
orderdate >=
'20070101'
AND
orderdate <
'20080101'
AND
( custid = o1.custid
AND
empid = o1.empid
)
AND
( custid = o1.custid
AND
empid = o1.empid
)
OR
( custid = o1.custid
AND
custid
IS
NULL
AND
empid = o1.empid
)
OR
( custid = o1.custid
AND
custid
IS
NULL
AND
empid = o1.empid
AND
custid
IS
NULL
)
OR
( custid = o1.custid
AND
empid = o1.empid
AND
custid
IS
NULL
)
OR
( custid = o1.custid
AND
custid
IS
NULL
AND
empid = o1.empid
AND
custid
IS
NULL
) )
ORDER
BY
O1.custid ,
O1.empid
|
转载自:http://www.cnblogs.com/jackson0714/p/TSQLFundamentals_05.html
参考资料:
《SQL2008技术内幕:T-SQL语言基础》