SPP-net论文笔记《Spatial Pyramid Pooling in Deep Convolutional Network for Visual Recognition》
1. Introduction
在之前物体检测的文章,比如R-CNN中,他们都要求输入固定大小的图片,这些图片或者经过裁切(Crop)或者经过变形缩放(Warp),都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。两种方式如下所示。
crop:不能包含完整的区域 warp:几何失真
事实上,在网络实现的过程中,卷积层是不需要输入固定大小的图片的,而且还可以生成任意大小的特征图,只是全连接层需要固定大小的输入。因此,固定长度的约束仅限于全连接层。在本文中,提出了Spatial Pyramid Pooling layer 来解决这一问题,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。这样,整体的结构和之前R-CNN有所不同。

2. Spatital Pyramid Pooling
在讲什么是空间金字塔池化之前,先一下什么是空间金字塔。我的理解就是以不同大小的块来对图片提取特征,比如下面这张图
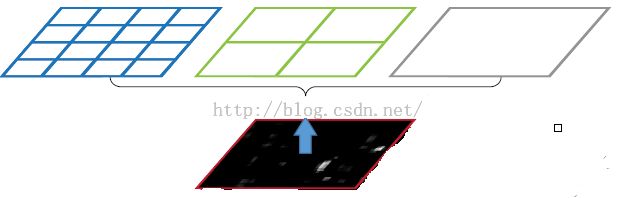

3.物体检测
带有SPP layer的网络叫做SPP-net,它在物体检测上跟R-CNN也有一定的区别。首先是特征提取上,速度提升了好多,R-CNN是直接从原始图片中提取特征,它在每张原始图片上提取2000个Region Proposal,然后对每一个区域建议框进行一次卷积计算,差不多要重复2000次,而SPP-net则是在卷积之后的特征图上提取特征。所有的卷积计算只进行了一次,效率大大提高。
使用SPP-net进行物体检测的流程如下:
①首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
②特征提取,这点和R-CNN是不同的,具体差别上面已经讲诉。
③最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
这样一来,就有个问题需要考虑,如何找到原始图片的候选框区域与feature map中提出特征的对应位置呢,因为候选框是通过一整张原图片进行检测得到的,而feature maps的大小和原始图片的大小是不同的,feature maps是经过原始图片卷积、下采样等一系列操作后得到的。那么我们要如何在feature maps中找到对应的区域呢?这个答案可以在文献中的最后面附录中找到答案:APPENDIX A:
Mapping a Window to Feature Maps。这个作者直接给出了一个很方便我们计算的公式:假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系:
(x,y)=(S*x’,S*y’)
其中S的就是CNN中所有的strides的乘积。比如paper所用的ZF-5:
S=2*2*2*2=16
而对于Overfeat-5/7就是S=12,这个可以看一下下面的表格:
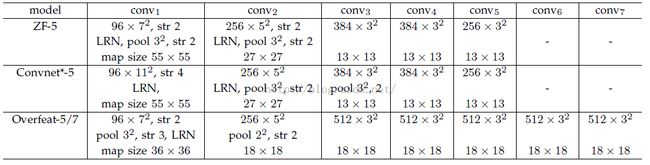
需要注意的是Strides包含了池化、卷积的stride。自己计算一下Overfeat-5/7(前5层)是不是等于12。
反过来,我们希望通过(x,y)坐标求解(x’,y’),那么计算公式如下:
![]()
因此我们输入原图片检测到的windows,可以得到每个矩形候选框的四个角点,然后我们再根据公式:
Left、Top:
![]()
Right、Bottom:
![]()
注:因为感觉自己的组织能力不是很好,所以这篇博文很大程度上都是在参考了一下两篇的基础上写的。
读DL论文心得之SPP:http://blog.csdn.net/liumaolincycle/article/details/49798343
基于空间金字塔池化的卷积神经网络物体检测:http://blog.csdn.net/hjimce/article/details/50187655