学习笔记--内核中C语言和汇编的使用
前言
好像有好长一段时间没有写认真这一个技术型的博客了。感觉没有将新学的知识记录下来,很快就丢掉了,回过头来,还是一场空。所以,写博客是一个长期而持久的事情。
最近,在学习linux内核,用到了AT&T汇编和C语言。在内核中,总是出现两者的混编,在这里总结一些最近的学习成果。等到以后需要用到的时候,可以快速回忆起来。
下面开始进入主题了。希望我的这个文章,不会让读者嫌弃,如有错误,请指出。
C语言的编译和连接
编译过程介绍
在学习内核的时候,每次看看一本新的书都要先介绍一些编译连接的过程。自己看了好多遍了,但是都没有好好的总结一下。这里简单介绍下:
一个源程序,一般经过下面的几个步骤:
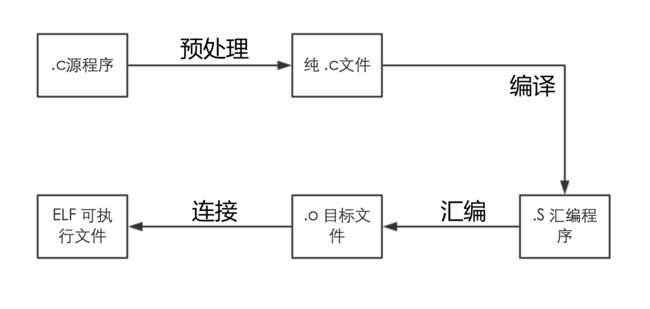
上图中写到,C程序编译连接为目标文件,一共有5个步骤。分别为预处理,编译,汇编,连接。
- 预处理:主要处理源代码的文本文件,对源代码做一些预处理,编程纯粹的C语言文件。主要处理的有用定义,文件包含和条件编译。
- 编译:将C语言(高级语言)生成汇编(低级语言)。
- 汇编:把汇编语言翻译成机器语言,即将汇编语言变成0101010…… 需要注意的是,上面的三步都是相对于单个文件进行操作的,最后通过下面的连接,将他们连接成一个可执行的程序。
- 连接:用来把要执行的程序与库文件或其他已经翻译好的子程序(能完成一种独立功能的程序模块)连接在一起,形成机器能执行的程序。
实际例子讲解
源程序
test.h
#define VALUE 0test.c
#include"test.h"
#ifndef MARK
#undef VALUE
#define VALUE 100
#else
#undef VALUE
#define VALUE 200
#endif
int main(){
int vlaue = VALUE;
return vlaue;
}预处理之后的纯C文件
在shell中,键入:
gcc -o test.i -E test.c
产生下面的纯C文件:
int main(){
int vlaue = 100;
return vlaue;
}之前源文件中的宏定义,文件包含等等的都被预处理程序处理掉了,生成了一个干净的C文件。
编译之后的汇编文件
在shell中,键入:
gcc -o test.S -S test.i
产生下面的汇编文件:
.file "test.c" #文件名
.text #代码段
.globl main #定义全局函数
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $100, -4(%rbp)
movl -4(%rbp), %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 5.2.1-22ubuntu2) 5.2.1 20151010"
.section .note.GNU-stack,"",@progbits通过编译将C文件编译成了汇编文件。这里面的语法,我们先不用了解,在后面的讲解中,会慢慢解释。
将汇编文件汇编成目标文件
在shell中,键入:
gcc -o test.o -c test.S
产生下面的二进制文件:
7f45 4c46 0201 0100 0000 0000 0000 0000 0100 3e00 0100 0000 0000 0000 0000 0000 0000 0000 0000 0000 1002 0000 0000 0000 ………………
在汇编步骤中,将以前我们人类易于理解的指令代码,变成了机器易于理解的二进制。汇编步骤,其实就是将汇编码翻译成为机器码。
将目标文件连接成可执行文件
在shell中,键入:
gcc -o test test.o
产生下面的二进制文件:
7f45 4c46 0201 0100 0000 0000 0000 0000 0200 3e00 0100 0000 0004 4000 0000 0000 4000 0000 0000 0000 c019 0000 0000 0000 ………………
通过连接,将test函数和其他的库,启动函数,等等文件连接。ps:没有连接启动函数,test文件无法被执行,恕我知识浅薄,现在所了解的,就只有这么一点了。希望读者多多提意见。
C语言嵌入汇编
在内核中,C语言中,嵌入汇编语言是一种比较常见的方式,汇编用于执行效率要求高的代码块。
下面是嵌入汇编格式:
asm("汇编语言"
:输出寄存器
:输入寄存器
:会被修改的寄存器);下面对上面格式进行简单介绍:
+ asm:为内联汇编语句的关键词
+ 输出寄存器:表示当这段嵌入式汇编执行完之后,哪些寄存器用于输出数据。
+ 输入寄存器:表示执行汇编代码时,指定一些寄存器中应存放的输入值。
+ 会被修改的寄存器:表示你已对其中列出的寄存器中的值进行了改动。
实际例子讲解
#define get_seg_byte(seg,addr) ({ \
register char __res; \
__asm__("push %%fs; //保存fs寄存器内容
mov %%ax,%%fs; //给fs赋予ax中的内容(ax的内容 在"输入寄存器"模块 中已经设置)
movb %%fs:%2,%%al; //取seg:addr处1字节内容到al寄存器中
pop %%fs" //返回fs寄存器内容
:"=a" (__res) //输出寄存器:将eax寄存器中的内容赋给__res变量
:"0" (seg),"m" (*(addr))); //输入寄存器:eax寄存器=seg 内存地址=addr地址
__res;})下面是对这个例子的详细描述:
首先:要分析一个嵌入汇编代码块,需要先看的就是:输出寄存器,输入寄存器,会被修改的寄存器这三个模块。
- 输出寄存器:在代码执行完毕之后,将eax寄存器中数据赋值给变量__res。这里需要注意赋值的格式:”=a”(__res)
- 输入寄存器:在代码执行之前,给eax赋予值seg,给内存地址赋予值*addr。
- 会被修改的寄存器:表示你已对列出的寄存器中的值进行改动了。这样gcc编译器就知道不能在依赖于它原先对这些寄存器加载值了。
对在输入寄存器中的数字0进行说明:
在嵌入汇编程序规定把输入输出寄存器统一按照顺序编号,顺序是从输入寄存器序列从左到右从上到下以”%0”开始,分别为%1,%2,%3……对寄存器a,m进行说明:
在输入寄存器中有=a,在输出寄存器中有m,那么他们是怎么和寄存器映射的呢?下面是映射关系图:
| 代码 | 说明 | 代码 | 说明 |
|---|---|---|---|
| a | 使用寄存器eax | m | 使用内存地址 |
| b | 使用寄存器ebx | o | 使用内存地址并可以加偏移值 |
| c | 使用寄存器ecx | I | 使用常数0-31 |
| d | 使用寄存器edx | J | 使用常数0-63 |
| S | 使用esi | K | 使用常数0-255 |
| D | 使用edi | L | 使用常数0-65535 |
| q | 使用动态分配字节可寻址寄存器(eax,ebx,ecx或edx | M | 使用常数0-3 |
| r | 使用任意动态分配的寄存器 | N | 使用1字节常数(0-255) |
| g | 使用通用有效的地址即可(eax,ebx,ecx,edx或内存变量) | O | 使用常数0-31 |
| A | 使用eax与edx联合(64位 | = | 输出操作数,输出值将替换前值 |
| + | 表示操作数可读可写 | & | 早期汇编的操作数。表示在使用完操作数之前,内容会被修改 |
- 代码模块分析:
- 格式注意,在嵌入汇编中,我们需要对汇编代码加上双引号,例如“push %%fs”
- 对输入输出寄存器的操作:之前讲到,我们通过%num来操作输入输出寄存器,下面就是一个例子:
movb %%fs:%2,%%al; //fs之前赋值了,等于seg,%2表示*addr地址
经过这样一番描述,你是不是对嵌入汇编有了一定的了解呢? ^_^~~ 如果还是不怎么懂的话,可以把你的问题贴出来,大家一起研究哦(ps:我是菜鸟~)