Coursera公开课笔记: 斯坦福大学机器学习第四课“多变量线性回归(Linear Regression with Multiple Variables)”
来自:http://www.52nlp.cn/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AC%AC%E5%9B%9B%E8%AF%BE%E5%A4%9A%E5%8F%98%E9%87%8F
斯坦福大学机器学习第四课”多变量线性回归“学习笔记,本次课程主要包括7部分:
1) Multiple features(多维特征)
2) Gradient descent for multiple variables(梯度下降在多变量线性回归中的应用)
3) Gradient descent in practice I: Feature Scaling(梯度下降实践1:特征归一化)
4) Gradient descent in practice II: Learning rate(梯度下降实践2:步长的选择)
5) Features and polynomial regression(特征及多项式回归)
6) Normal equation(正规方程-区别于迭代方法的直接解法)
7) Normal equation and non-invertibility (optional)(正规方程在矩阵不可逆情况下的解决方法)
以下是每一部分的详细解读:
1) Multiple features(多维特征)
第二课中我们谈到的是单变量的情况,单个特征的训练样本,单个特征的表达式,总结起来如下图所示:

对于多维特征或多个变量而言:以房价预测为例,特征除了“房屋大小外”,还可以增加“房间数、楼层数、房龄”等特征,如下所示:
定义:
n = 特征数目
x(i) = 第i个训练样本的所有输入特征,可以认为是一组特征向量
x(i)j = 第i个训练样本第j个特征的值,可以认为是特征向量中的第j个值
对于Hypothesis,不再是单个变量线性回归时的公式: hθ(x)=θ0+θ1x
而是:
为了方便,记 x0 = 1,则多变量线性回归可以记为:
其中 θ 和x都是向量。
2) Gradient descent for multiple variables(梯度下降在多变量线性回归中的应用)
对于Hypothesis:
其中参数: θ0 , θ1 ,…, θn 可表示为n+1维的向量 θ
对于Cost Function:
梯度下降算法如下:
对 J(θ) 求导,分别对应的单变量和多变量梯度下降算法如下:
当特征数目为1,也就是n=1时:
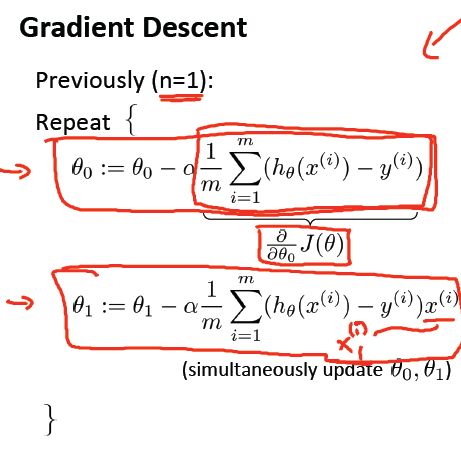
当特征数目大于1也就是n>1时,梯度下降算法如下:
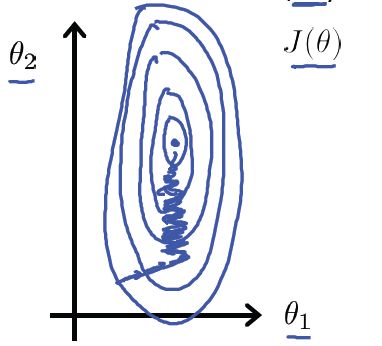
3) Gradient descent in practice I: Feature Scaling(梯度下降实践1:特征归一化)
核心思想:确保特征在相似的尺度里。
例如房价问题:
特征1:房屋的大小(0-2000);
特征2:房间数目(1-5);
简单的归一化,除以每组特征的最大值,则:
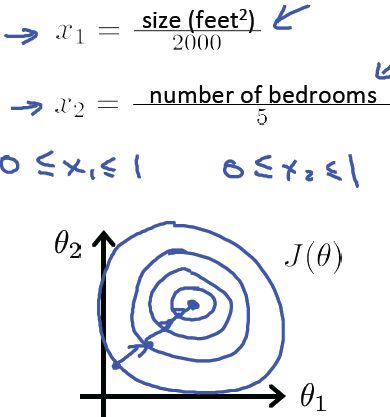
目标:使每一个特征值都近似的落在 −1≤xi≤1 的范围内。
举例:因为是近似落在这个范围内,所以只要接近的范围基本上都可以接受,例如:
0<=x1<=3, -2<=x2<=0.5, -3 to 3, -1/3 to 1/3 都ok;
但是:-100 to 100, -0.0001 to 0.0001不Ok。
Mean Normalization(均值归一化):
用 xi–μi 替换 xi 使特征的均值近似为0(但是不对 x0=1 处理),均值归一化的公式是:
其中 Si 可以是特征的取值范围(最大值-最小值),也可以是标准差(standard deviation).
对于房价问题中的两个特征,均值归一化的过程如下:
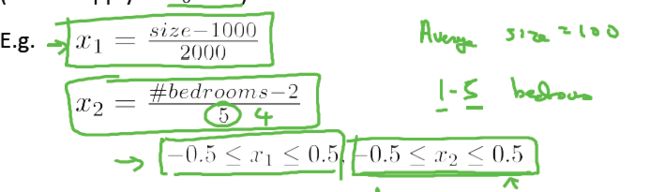
4) Gradient descent in practice II: Learning rate(梯度下降实践2:步长的选择)
对于梯度下降算法:
需要注意两点:
-”调试”:如何确保梯度下降算法正确的执行;
-如何选择正确的步长(learning rate): α ;
第二点很重要,它也是确保梯度下降收敛的关键点。要确保梯度下降算法正确运行,需要保证 J(θ) 在每一步迭代中都减小,如果某一步减少的值少于某个很小的值 ϵ , 则其收敛。例如:

如果梯度下降算法不能正常运行,考虑使用更小的步长 α ,这里需要注意两点:
1)对于足够小的 α , J(θ) 能保证在每一步都减小;
2)但是如果 α 太小,梯度下降算法收敛的会很慢;
总结:
1)如果 α 太小,就会收敛很慢;
2)如果 α 太大,就不能保证每一次迭代 J(θ) 都减小,也就不能保证 J(θ) 收敛;
如何选择 α -经验的方法:
…, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1…
约3倍于前一个数。
5) Features and polynomial regression(特征及多项式回归)
例子-房价预测问题:
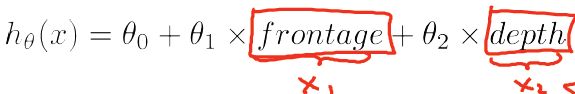
特征 x1 表示frontage(正面的宽度),特征 x2 表示depth(深度)
同时 x1,x2 也可以用一个特征表示:面积 Area = frontage * depth
即 hθ(x)=θ0+θ1x , x表示面积。
多项式回归:
很多时候,线性回归不能很好的拟合给定的样本点,例如:
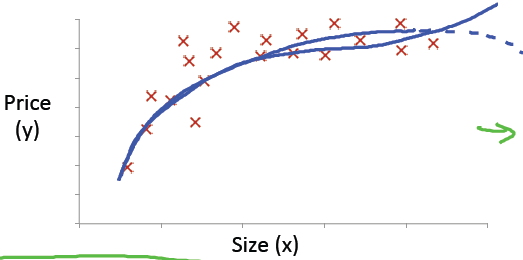
所以我们选择多项式回归:
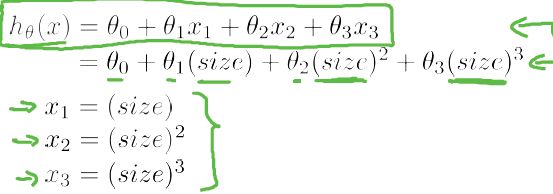
对于特征的选择,除了n次方外,也可以开根号,事实上也是1/2次方:
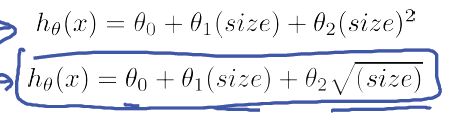
6) Normal equation(正规方程-区别于迭代方法的直接解法)
相对于梯度下降方法,Normal Equation是用分析的方法直接解决 θ .
正规方程的背景:
在微积分里,对于1维的情况,如果 θ 属于R:
求其最小值的方法是令:
然后得到 θ .
同理,在多变量线性回归中,对于 θ∈Rn+1 ,Cost Function是:
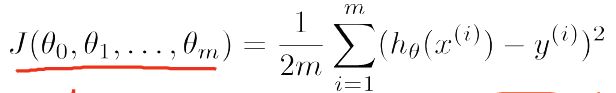
求取 θ 的思路仍然是:
对于有4组特征(m=4)的房价预测问题:
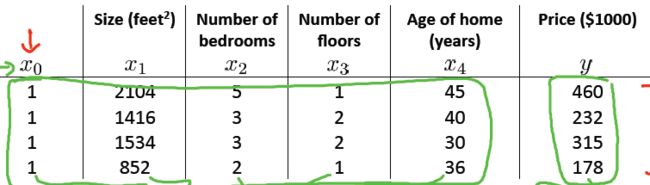
其中X 是m * (n+1)矩阵:
y是m维向量:
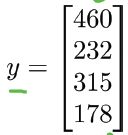
则Normal equation的公式为:
注:这里直接给出了正规方程的公式,没有给出为什么是这样的,如果想知道原因,建议看看MIT线性代数 第4章4.3节“最小二乘法”的相关内容,这里面最关键的一个点是:
“The partial derivatives of ||Ax–b||2 are zero when ATAx=ATb .
举例可见官方的PPT,此处略;
Octave公式非常简洁:pinv(X’ * X) * X’ * y
对于m个样本,n个特征的问题,以下是梯度下降和正规方程的优缺点:
梯度下降:
需要选择合适的learning rate α ;
需要很多轮迭代;
但是即使n很大的时候效果也很好;
Normal Equation:
不需要选择 α ;
不需要迭代,一次搞定;
但是需要计算 (XTX)−1 ,其时间复杂度是 O(n3)
如果n很大,就非常慢
7) Normal equation and non-invertibility (optional)(正规方程在矩阵不可逆情况下的解决方法)
对于Normal Equation,如果 XTX 不可逆怎么办?
1) 去掉冗余的特征(线性相关):
例如以平方英尺为单位的面积x1, 和以平方米为单位的面积x2,其是线性相关的:
x1=(3.28)2x2
2) 过多的特征,例如m <= n:
删掉一些特征,或者使用regularization–之后的课程会专门介绍。
参考资料: