imaplib 模块登陆163邮箱及下载
上一篇使用了pop3模块进行邮件的下载,模块提供的功能不如本篇的imap。
本篇将稍微深入的通过imap进行邮件的登陆和下载;
1、邮件登陆信息获取:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
#filename:receive_imap_email.py
import imaplib, os, ConfigParser, re
import pprint
#进行用户的登陆,主要通过config文件进行主机名,用户名和密码的获取
def user_login(verbose=False):#verbose=False为函数参数定义的一种方式,在True的情况下执行
#Read the config file
config = ConfigParser.ConfigParser()
config.read(r'D:\Python\tmp\config.txt')
#Connect to the server
hostname = config.get('server', 'hostname')
if verbose:
print 'Connecting to', hostname
m = imaplib.IMAP4(hostname)
#Login to the account
username = config.get('account', 'username')
passwd = config.get('account', 'passwd')
if verbose:
print 'Logging in as ', username
m.login(username,passwd)
print type(m)#返回instance
return m
#对收件箱进行检查,列出对应的文件夹
def list_inbox():
l_box = user_login(verbose=True)
print type(l_box)
try:
typ, data = l_box.list()#注意这种赋值方式,返回值是状态和inbox,drafts,sent,trash等;即后者的两个元素依次赋给前者
print 'Response code:', typ
print 'Response:'
pprint.pprint(data)
finally:
l_box.logout()
#user_login(verbose=True)#在True的情况下执行
list_inbox()
输出:
>>> ================================ RESTART ================================ >>> Connecting to imap.163.com Logging in as dxx_study <type 'instance'> <type 'instance'> Response code: OK Response: ['() "/" "INBOX"', '(\\Drafts) "/" "&g0l6P3ux-"', '(\\Sent) "/" "&XfJT0ZAB-"', '(\\Trash) "/" "&XfJSIJZk-"', '(\\Junk) "/" "&V4NXPpCuTvY-"', '() "/" "&dcVr0mWHTvZZOQ-"', '() "/" "&Xn9USpCuTvY-"', '() "/" "&i6KWBZCuTvY-"', '() "/" "test"']
从以上可以看出,编码将是这个工作中的难点,因为邮件编码采用的是base64,并且还要区分发件人的编码,目前已遇到的主要有utf-8,这个一般不处理,直接输出,其次是gb2312,再次是gbk,或者英文的直接ascii。
2、邮件解码
对于解码部分又分为,邮件标题和发件人,以及邮件正文。
下面再实例记录下处理的一些方法和技巧:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#filename:receive_imap_email.py
import imaplib, os, ConfigParser, re
import pprint, sys, email, string
#reload(sys)#设置为命令窗口cmd输出
#sys.setdefaultencoding('gbk')
def user_login(verbose=False):#verbose=False为函数参数定义的一种方式,在True的情况下执行
#Read the config file
config = ConfigParser.ConfigParser()
config.read(r'D:\Python\tmp\config.txt')
#Connect to the server
hostname = config.get('server', 'hostname')
if verbose:
print 'Connecting to', hostname
m = imaplib.IMAP4(hostname)
#Login to the account
username = config.get('account', 'username')
passwd = config.get('account', 'passwd')
if verbose:
print 'Logging in as ', username
m.login(username,passwd)
return m
def list_inbox():#罗列收件箱的子目录
l_box = user_login(verbose=True)
try:
typ, data = l_box.list()#注意这种赋值方式,返回值是状态和inbox,drafts,sent,trash等
print 'Response code:', typ
print 'Response:'
pprint.pprint(data)#Mailbox names are in modified UTF7 character set.输出会出现乱码
finally:
l_box.logout()
def status_mailbox():
stat_m = user_login(verbose=True)
try:
typ, data = stat_m.list()
for line in data:#由于字符编码问题,暂无法去匹配对应收件箱的状态,未完待续
print line
finally:
stat_m.logout()
def to_unicode(s, encoding):
if encoding:
return unicode(s, encoding)
else:
return unicode(s)
def parse_email(msg):
for part in msg.walk():
if not part.is_multipart():
content_type = part.get_content_type()
filename = part.get_filename()
charset = part.get_content_charset()
if charset == None or charset == 'utf-8':
return part.get_payload()
elif charset == 'gb2312':
return part.get_payload(decode=True).decode('gb2312').encode('utf-8')
else:
return unicode(part.get_payload(decode=True),charset).encode('utf-8')
def imap_example():
m = user_login(verbose=True)
m.select()
result, message = m.select()
i = 1
try:
typ, data = m.search(None, 'All')#Search mailbox for matching messages
#for num in data[0].split():#与下方等价
for num in string.split(data[0]):
typ, data = m.fetch(num, '(RFC822)')#Fetch (parts of) messages
msg = email.message_from_string(data[0][1])
from_sender = msg['From'].split(' ')
if(len(from_sender) == 2):
fromname = email.Header.decode_header((from_sender[0]).strip('\"'))
sender = 'E-mail From1: ' + to_unicode(fromname[0][0], fromname[0][1]) + from_sender[1]
else:
sender = 'E-mail From2: ' + msg['From']
date = 'Date From: ' + msg['Date']
subject = email.Header.decode_header(msg['Subject'])
if subject[0][1] == 'utf-8':
title = 'Subject: ' + subject[0][0]
mail_content = parse_email(msg)
else:
title = 'Subject: ' + to_unicode(subject[0][0], subject[0][1])
mail_content = parse_email(msg)
print '\n'
print sender,'\n',date,'\n',title
#邮件保存
outf = open('%s.eml' % i, 'w')
outf.write(mail_content)
outf.close()
i = i + 1
finally:
m.logout()
imap_example()
parse_email(msg)
imap_example()
to_unicode(s, encoding)
这三个函数的主要功能依次是,
1、利用email模块解析邮件,实际是进行邮件正文的编码转换和信息提取
2、利用email的email.Header进行邮件sender,subject,date的提取和输出
3、字符编码转换。(这个还不是很理解)
输出:
>>> ================================ RESTART ================================ >>> Connecting to imap.163.com Logging in as dxx_study E-mail From1: 推ぁ校园居士<[email protected]> Date From: Wed, 24 Mar 2010 22:39:36 +0800 Subject: 推 E-mail From1: 幻影<[email protected]> Date From: Thu, 25 Mar 2010 22:49:10 +0800 Subject: 挂科人次 E-mail From1: 贾苏川<[email protected]> Date From: Thu, 25 Mar 2010 23:39:11 +0800 Subject: 挂科人次 ....... 等
这样就不会出现前面提到的乱码了。
另外,对于邮件的下载结果如下:
虽然邮件下载下来了,但是当初想以发件人或者subject来命名邮件的,实际中由于win的命名规则让有些邮件的sender或者subject根本就不能直接作为文件名,要使用,肯定需要进一步检查和处理;
其次,本次下载下来的邮件打开查看时,没有标题时间,只有内容,实际效果不如直接
for msg_id in p.list()[1]:
print msg_id
outf = open('%s.eml' % msg_id, 'w')
outf.write('\n'.join(p.retr(msg_id)[1]))
outf.close() 进行保存的效果好,而且出现乱码的机会也少。
实际使用中可以结合着使用。
3、其它参考及下载附件
对于email模块和解码还参考了下面一个程序:
实际和上面功能差不多,都可以提取date,subject,sender,但是可以下载附件,不过邮件正文保存有问题,不能用于保存邮件。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#filename:receive_mail.py
import imaplib, email, sys
#reload(sys)
#sys.setdefaultencoding('gbk')
def savefile(filename, data, path):#保存文件的方式和位置设置
try:
filepath = path + filename
print 'Saved as ' + filepath#保存路径设置
f = open(filepath, 'w')
f.write(data)#写入数据
f.close()
except:
print ('filename input error')
def my_unicode(s, encoding):#字符编码转换
if encoding:
return unicode(s, encoding)
else:
return unicode(s)
def get_charset(message, default='ascii'):#获取字符编码/但对utf-8需要验证
return message.get_charset
return default
def parse_email(msg, mypath):#解析邮件,区分正文和附件
mail_content = None
content_type = None
suffix = None
for part in msg.walk():#email.message.Message模块中的walk()方法,用于深度遍历信息树对象
if not part.is_multipart():#email模块中 .is_multipart(),Return True if the message’s payload is a list of sub-Message objects,
#otherwise return False. When is_multipart() returns False, the payload should be a string object.
#这里表示,如果message payload是一个string object时进行如下处理
content_type = part.get_content_type()#get_content_type(),Return the message’s content type. The returned string is coerced to lower case of the form maintype/subtype.
#If there was no Content-Type header in the message the default type as given by get_default_type() will be returned.
filename = part.get_filename()#Return the value of the filename parameter of the Content-Disposition header of the message.
#charset = get_charset(part)#调用get_charset()函数,获取字符编码
ch = part.get_content_charset()
if filename :#check the attachment,进行附件处理
h = email.Header.Header(filename)#Create a MIME-compliant header that can contain strings in different character sets.
dh = email.Header.decode_header(h)#Decode a message header value without converting the character set. The header value is in header.
#dh得到的返回值是一个list,即(decoded_string, charset),包含header的decoded parts
fname = dh[0][0]
encodeStr = dh[0][1]#分别取值
if encodeStr != None:
#if charset == None:
if ch == None:
fname = fname.decode(encodeStr, 'gbk')
else:
#fname = fname.decode(encodeStr, charset)#比较dh返回的charset和part中get得到的charset,然后根据类型解码
fname = fname.decode(encodeStr, ch)
data = part.get_payload(decode=True)#Return the current payload, which will be a list of Message objects when is_multipart() is True,
# or a string when is_multipart() is False.
print ('Attachment:' + fname)
if fname != None or fname != '':#如果存在dh[0][0],则save attachment
savefile(fname, data, mypath)#调用保存函数
else:
if content_type in ['text/plain']:#进行message的内容格式判断,并选择后缀名保存方式
suffix = '.txt'
if content_type in ['text/html']:
suffix = '.htm'
#if charset == None:
# mail_content = part.get_payload(decode=True)
#else:
# mail_content = part.get_payload(decode=True).decode(charset)#对utf-8编码邮件会出错
##ch = part.get_content_charset()
if ch:
mail_content = unicode(part.get_payload(decode=True),ch).encode('utf-8')
else:
mail_content = part.get_payload(decode=True).decode('gb2312').encode('utf-8')
return (mail_content, suffix)
def get_mail(mailhost, account, password, mypath, port = 993, ssl = 1):#获取邮件
if ssl == 1:#选择是否采用 SSL login
imap_server = imaplib.IMAP4_SSL(mailhost,port)
else:
imap_server = imaplib.IMAP4(mailhost,port)
imap_server.login(account, password)
s = imap_server.select()#选择邮件箱,默认为收件箱,返回收件箱邮件数目,必须选择!!
#print s #得到信息为:('OK', ['178'])
number = 1#定义编号,方便终端输出显示如 No:3
#Message statues = 'All,Unseen,Seen,Recent,Answered,Flagged'#邮件状态设置,定义从哪里提取邮件
resp, items = imap_server.search(None, 'Unseen')#选择未读收件箱
for i in items[0].split():
resp, data = imap_server.fetch(i, '(RFC822)')#获取parts of message
msg = email.message_from_string(data[0][1])#提取list中第二部分信息,msg为一个instance
whosend = msg['From'].split(' ')#以空格拆分from:sender的信息内容,得到一个list,长度为2,list[1]为发送者的邮箱
if(len(whosend) == 2):
fromname = email.Header.decode_header((whosend[0]).strip('\"'))#先移除双引号,再解码
strfrom = 'From:' + my_unicode(fromname[0][0], fromname[0][1]) + whosend[1]#调用my_unicode()函数进行编码
else:
strfrom = 'From:' + msg['From']
strdate = 'Date:' + msg['Date']
subject = email.Header.decode_header(msg['Subject'])#得到一个list
#print subject[0][0]#邮件标题
#print subject[0][1]#字符编码格式,英文为None,汉字为gbk,或者utf-8时,后续处理有问题
#此处实际有缺陷,加一个检测,如果是utf-8则不进行转换
if subject[0][1] != 'utf-8':
sub = my_unicode(subject[0][0], subject[0][1])#调用my_unicode()进行编码转换
strsub = 'Subject:' + sub
mail_content, suffix = parse_email(msg, mypath)#调用parse_email()进行邮件解析
else:
strsub = 'Subject:' + subject[0][0]
mail_content, suffix = parse_email(msg, mypath)#调用parse_email()进行邮件解析
#提取的邮件信息输出
print '\n'
print 'No:' + str(number)
print strfrom
print strdate
print strsub
'''
print 'content:'
print mail_content
'''
#保存邮件正文,编码还存在问题
if (suffix != None and suffix !='') and (mail_content != None and mail_content !=''):
savefile(str(number) + suffix, mail_content, mypath)#调用savefile()函数进行邮件保存
number = number + 1
imap_server.close()
imap_server.logout()
if __name__ == '__main__':
mypath = "D:\\test_tmp\\" #邮件保存位置
print 'getting e-mail ...'
#get_mail('imap.gmail.com','[email protected]','XXXX',mypath,993,1)
get_mail('imap.163.com','[email protected]','XXXX',mypath,143,0)
print 'download e-mail completed'
输出:
>>> ================================ RESTART ================================ >>> getting e-mail ... No:1 From:人人网<[email protected]> Date:Fri, 1 Nov 2013 23:15:17 +0800 (CST) Subject:王沛: 小伙伴们在关注什么?尽在人人热门分享一周盘点 Saved as D:\test_tmp\1.htm No:2 From:王海<[email protected]> Date:Tue, 5 Nov 2013 15:11:59 +0800 (CST) Subject:testt mail Saved as D:\test_tmp\2.htm No:3 From:王海<[email protected]> Date:Thu, 7 Nov 2013 09:49:47 +0800 (CST) Subject:测试汉字 Saved as D:\test_tmp\3.htm Attachment:hosts.txt #这里保存了一个附件,注意 Saved as D:\test_tmp\hosts.txt No:4 From:王海<[email protected]> Date:Thu, 7 Nov 2013 14:06:31 +0800 (CST) Subject:test attachment Saved as D:\test_tmp\4.htm download e-mail completed >>>
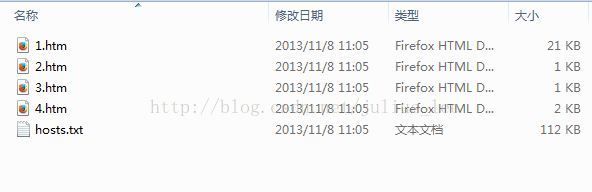
4、以此类推
这个程序读取的是未读邮件,实际是可以根据需求定义的,也可以是已读邮件,标志邮件等
#Message statues = 'All,Unseen,Seen,Recent,Answered,Flagged'#邮件状态设置,定义从哪里提取邮件
resp, items = imap_server.search(None, 'Unseen')#选择未读收件箱 可以设置上面的参数。
5、Python email模块
对于email模块,时间参数还是比较多的,没有去像正则那样仔细看官方文档了,回顾下折腾的最多的还是字符编码这一块,主要是邮件的base64和使用中文导致的,如果都是英文会好很多。
下面粘贴下email模块的相关解释:
email.message_from_string() 这个方法能把String的邮件转换成email.message实例.
下面这样调用:
mail=email.message_from_string(string.join(message,'\n'))
这样就生成了一个email.Message实例
提取邮件内容,和标题,mail支持字典操作,比如下面的操作:
mail['subject'] ,mail.get('subject')
mail['To'],mail.get('to')'
mail.keys() ,mail.items() 等等.
中文邮件的标题和内容都是base64编码的,解码可以使用email.Header 里的decode_header()方法:
比如 print mail['subject'] 显示的都未处理的编码.
'=?GB2312?B?UmU6IFtweXRob24tY2hpbmVzZV0g?=\n\t=?GB2312?B?y63E3LDvztLV0tbQzsS1xFBZVEhPTrP10afRp8+wtcTXysHP?='
email.Header.decode_header(mail['subject']) 下面是解码后的信息.
[('Re: [python-chinese] \xcb\xad\xc4\xdc\xb0\xef\xce\xd2\xd5\xd2\xd6\xd0\xce\xc4\xb5\xc4PYTHON\xb3\xf5\xd1\xa7\xd1\xa7\xcf\xb0\xb5\xc4\xd7\xca\xc1\xcf', 'gb2312')]
返回的是一个列表,里面的内容保存在一个元组里。(解码后的字串,字符编码)
显示解码后的标题就象下面这样
print email.Header.decode_header(mail['subject'])[0][0]
Re: [python-chinese] 谁能帮我找中文的PYTHON初学学习的资料
上面的mail标题编码是'gb2312'的。如果编码是别的比如'utf-8'编码,那么显示出来的就是乱码了,需要使用unicode()方法,unicode('string',‘编码,比如UTF-8'),比如
subject=email.Header.decode_header(mail['subject'])[0][0]
subcode=email.Header.decode_header(mail['subject'])[0][1])
print unicode(subject,subcode)
Re: [python-chinese] 谁能帮我找中文的PYTHON初学学习的资料
如何处理邮件内容:
mail里有很多方法,熟悉这些方法处理邮件就很容易了。
get_payload() 这个方法可以把邮件的内容解码并且显示出来。第一个可选择参数是mail实例,第二个参数是decode='编码' ,一般都是,'base64'编码
is_multipart(),这个方法返回boolean值,如果实例包括多段,就返回True,
print mail.is_multipart()
true ,这说明这个mail邮件包含多个字段。
MIME (Multipurpose Internet Mail Extensions) (RFC 1341)
MIME扩展邮件的格式,用以支持非ASCII编码的文本、非文本附件以及包含多个部分 (multi-part) 的邮件体等。
1. class email.message.Message
__getitem__,__setitem__实现obj[key]形式的访问。
Msg.attach(playload): 向当前Msg添加playload。
Msg.set_playload(playload): 把整个Msg对象的邮件体设成playload。
Msg.add_header(_name, _value, **_params): 添加邮件头字段。
2. class email.mime.base.MIMEBase(_maintype, _subtype, **_params)
所有MIME类的基类,是email.message.Message类的子类。
3. class email.mime.multipart.MIMEMultipart()
在3.0版本的email模块 (Python 2.3-Python 2.5) 中,这个类位于email.MIMEMultipart.MIMEMultipart。
这个类是MIMEBase的直接子类,用来生成包含多个部分的邮件体的MIME对象。
4. class email.mime.text.MIMEText(_text)
使用字符串_text来生成MIME对象的主体文本。
另外:
邮件格式 (RFC 2822)
每封邮件都有两个部分:邮件头和邮件体,两者使用一个空行分隔。
邮件头每个字段 (Field) 包括两部分:字段名和字段值,两者使用冒号分隔。有两个字段需要注意:From和Sender字段。From字段指明的是邮件的作者,Sender字段指明的是邮件的发送者。如果From字段包含多于一个的作者,必须指定Sender字段;如果From字段只有一个作者并且作者和发送者相同,那么不应该再使用Sender字段,否则From字段和Sender字段应该同时使用。
邮件体包含邮件的内容,它的类型由邮件头的Content-Type字段指明。RFC 2822定义的邮件格式中,邮件体只是单纯的ASCII编码的字符序列。
6、总结:
从这一次练习可以看出
1.充分利用已有的模块进行调用,可以起到事半功倍的作用,免得自己在那里解码;
2.解码与编码也是一个学问,特别是对处理邮件,不同客户端和服务端,语言涉及的太多,情况比较复杂;
3.了解了邮件的基本格式,对于处理对象就是要按照其自己的规则来处理的思想;
7、参考文献:
http://pymotw.com/2/imaplib/ 这篇很好,不过从正则匹配编码开始就不能套用了,别个是英文呀!自己的是中文,不过处理方式及基本解释还是很实用的 。
http://www.cs.sfu.ca/CourseCentral/120/havens/python-2.7-docs-html/library/email.message.html email模块
最后一个程序,源自新浪,记不得了,里面有很多错误,自己修改了很多。
http://blog.csdn.net/bravezhe/article/details/7659173
http://tools.ietf.org/html/rfc3501.html
好了,就这么多,折腾了两三天了,到此结束,毕竟只是瞧瞧email ,非专攻!