TaintDroid深入剖析之启动篇
1 背景知识
1.1 Android平台软件动态分析现状
众所周知,在计算机领域中所有的软件分析方法都可以归为静态分析和动态分析两大类,在Android平台也不例外。而随着软件加固、混淆技术的不断改进,静态分析越来越难以满足安全人员的分析要求,因此天生对软件加固、混淆免疫的动态分析技术应运而生。虽然动态分析技术本身有很多局限性,诸如:代码覆盖率低,执行效率低下等等,但是瑕不掩瑜,个人认为熟悉各种动态分析技术的核心原理也应当是安全从业人员的必备要求。
下图1-1展示了部分工业界和学术界在android平台动态分析技术上的成果,有兴趣的同学根据需求进一步了解:

图1-1 当前工业界和学术界在android平台动态分析技术部分成果
ps: 这张图是去年总结的,所以未能将一些最新的系统、工具纳入,欢迎各位大牛补充。
在上述众多优秀的动态分析系统、工具中,个人觉得基于污点跟踪技术的TaintDroid一定是其中最重量级的成果之一,截止今天,该论文的引用次数已经达到了惊人的1788次。虽然很多人都用过TaintDroid,甚至大牛们进行过二次开发,但是目前市面上并没有对TaintDroid进行深入剖析文章。因此本系列文章将会详细分析TaintDroid的具体实现,从源码层深了解TaindDroid的优缺点,希冀能跟大家一起开发出检测效果更好、运行效率更高的污点跟踪系统。
1.2 阅读论文
首先读者需要详细阅读TaintDroid的那篇论文(为方便英文不好的同学,我们已经将其翻译成了中文,由于论文翻译太费时,其中难免有不对的地方,建议大家对照着原文看^_^),该论文详细讲解了TaintDroid的核心技术以及其设计模型等等,充分理解这篇论文对我们后续深入了解TaintDroid的具体实现很有帮助。
1.3 下载源码
本文主要以Android4.1版本的TaintDroid为分析对象(其最新为android4.3版本,主要是添加对selinux的适配,核心内容并没有改变),为了便于读者进行对照分析或测试,建议读者按照官网http://appanalysis.org/download_4.1.html 的提示下载源码。当然,如果读者仅仅是想阅读污点跟踪相关的代码,可以去github中按照自己的需要下载对应部分源码即可。如实现变量级、Native级污点跟踪的代码基本都在dalvik目录下,所以可以在:
https://github.com/TaintDroid/android_platform_dalvik
下载dalvik相关源码。
1.4 系统栈帧概念
由于TaintDroid的变量级和方法级污点跟踪是建立在其对DVM栈和Native栈的修改之上的,所以我们必须熟悉系统栈帧的概念,如图1-2所示:
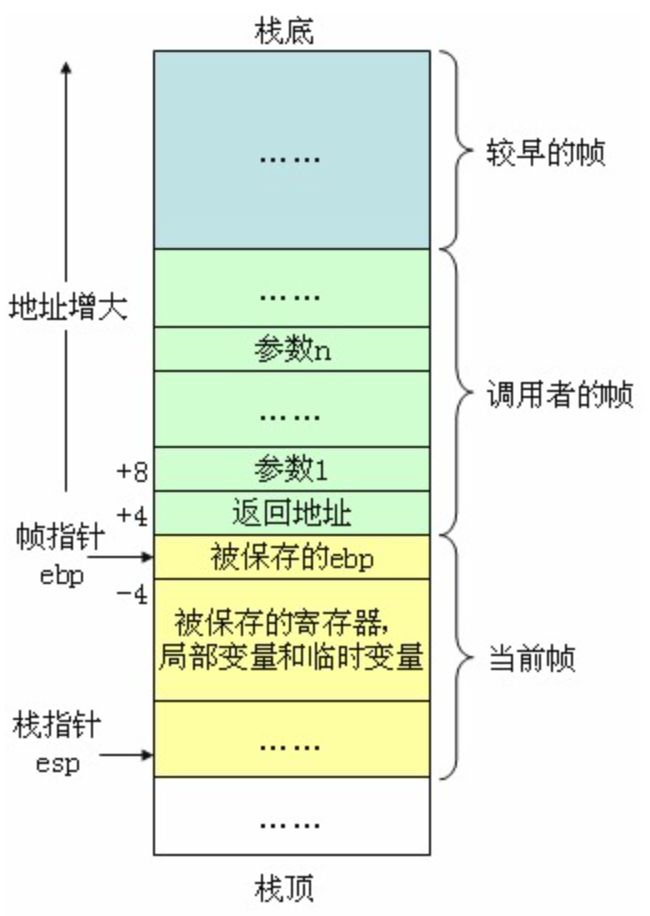
图1-2 系统栈帧分布
单个函数调用操作所使用的栈部分被称为栈帧(stack frame)结构,其一般结构如上图所示。栈帧结构的两端由两个指针来指定。寄存器ebp通常用做帧指针(frame pointer),而esp则用作栈指针(stack pointer)。在函数执行过程中,栈指针esp会随着数据的入栈和出栈而移动,因此函数中对大部分数据的访问都基于帧指针ebp进行。
1.5 内容安排
如下图所述:
鉴于TaintDroid有四种粒度的污点跟踪机制,且这四种污点跟踪机制实现逻辑相对独立,所以本系列文章将会分章讲解各个粒度污点跟踪机制的实现原理、方法,然后再从某些具体的情境出发,详细分析TaintDroid是如何综合利用这4种跟踪机制,以及为了无缝融合这些机制其所作的一些辅助性修改。
2 TaintDroid变量级污点跟踪分析之上篇
严格来说,应该叫做“DVM中interpreted方法的变量级污点跟踪分析”。从论文中我们得知:DVM 有 5 种类型的变量需要进行污点存储:方法的本地变量,方法的参数,类的静态域,类的实例域,数组。鉴于方法的本地变量和方法的参数是存储在方法的执行栈帧中;而类的静态域、实例域却以指针的方式进行存储;至于数组又有自己独特的数据结构ArrayObject。所以为了分析逻辑更加清晰,我们将TaintDroid变量级污点跟踪分析分为上下两篇:上篇主要讲解方法本地变量与方法参数的污点跟踪,下篇主要介绍类的静态域、实例域以及数组的污点跟踪。
TaintDroid为了实现此种机制以及后面章节将介绍的Native方法级污点跟踪机制,它对栈进行了一次大手术!至于这个手术的复杂度和难度系数具体如何,请听我们娓娓道来。
众所周知,在4.4之前的整个Android系统共存在两种类型的方法:
①Interpreted method: 在DVM虚拟机中解释执行的方法;需要注意的是,DVM中存在两种解释器:标准的可移植解释器dvmInterpretStd以及对某个特定平台优化后的解释器dvmMterpStd,前者由C代码实现,后者由汇编实现。
②Native method: 直接执行的C/C++/汇编代码,又可细分为Internal VM Method(如System.arraycopy)和JNI method。
这两类方法有各自的栈帧结构(Interpreted Stack和Native Stack),但是可以互相调用,即存在了以下4种情况:
| a. interpreted → interpreted 同一个类方法之间直接通过GOTO_invoke系列宏进行跳转。不同类的话根据具体情况而定。一直在interpreted stack中执行。 b. interpreted → native 如果目标函数是jni调用那么就判断method的NATIVE标志位,通过native调用桥dvmCallJniMethod进行跳转。常见情况就是JNI调用。 如果目标函数是Internal VM Method,那么就可以通过interpted代码直接调用,只是需要传递一个指向32位寄存器参数的指针以及一个指向返回值的指针即可。常见形式如下: InternalVMfunc(const u4* args, JValue* rResult){……} 由interpreted stack转到native stack。 c. native → native 这里主要说明由Internal VM Method或反射调用跳转到JNI Method的情况。在这种情况下最终会调用dvmPushJNIFrame为目标函数分配一个JNI帧。 d. native → interpreted 反射的话通过dvmInvokeMethod系列函数进行跳转;非反射的JNI调用就通过Jni.cpp中定义的CALL_XXX系列宏通过dvmCallMethodV/A进行跳转,均走dvmPushInterpFrame分支;非反射的Internal VM Method直接返回。常见情况就是jni调用。由native stack转到interpreted stack。 |
具体的栈帧结构会在后文进行详细说明,这里主要说一下TaintDroid对栈结构修改的代码位置。
它对栈结构的修改代码在dalvik/vm/interp/Stack.cpp文件中。按照常识,修改栈帧需要完成两个功能:1)分配新结构的栈帧;2)初始化新结构的栈帧。分配栈帧主要涉及到两个函数:1)dvmPushInterpFrame;2)dvmPushJNIFrame。而初始化栈帧同样涉及到两类函数:1) dvmCallMethodV/A;2) dvmInvokeMethod。
用于分配栈帧的两个函数均且只在callPrep函数中被调用:
| if (dvmIsNativeMethod(method)) { /* native code calling native code the hard way */ if (!dvmPushJNIFrame(self, method)) { …… } } else { /* native code calling interpreted code */ if (!dvmPushInterpFrame(self, method)) { …… } } |
而callPrep函数会在dvmCallMethodV/A以及dvmInvokeMethod中被调用。dvmCallMethodV/A会在jni.cpp中定义的CALL_XXX系列宏中被调用,dvmInvokeMethod会在java.lang.reflect的反射函数中被调用,即前2者用于jni,后者用于反射调用。
同时需要注意的是,TaintDroid也对dvmInvokeMethodV/A以及dvmInvokeMethod函数进行了修改以便正确地对栈帧进行初始化。另外还需要注意的是,上文中的dvmIsNativeMethod方法是用于判断即将被调用的方法是native还是dvm方法,而不是调用此方法的方法是native还是dvm。
鉴于两种栈帧的使用场景和布局大相庭径,且在TaintDroid中修改后的DVM栈帧主要用于实现变量级的污点跟踪,而Native栈帧主要用于实现方法级的污点跟踪,所以本章先分析执行在DVM中的interpreted栈帧,至于Native栈帧,在分析Native方法级污点跟踪的时候再详细说明。下面开始分析Interpreted栈帧的分配函数。
2.1 dvmPushInterpFrame分析
当从DVM内部的函数或通过反射调用一个interpreted method时,系统会为之分配一个栈帧,为了方便,后文将这种栈帧统称为DVM栈帧。注意此方法只有在“由native代码调用一个interpreted代码”的时候才会被调用。主要的更改代码如下:
| #ifdef WITH_TAINT_TRACKING /* taint tags are interleaved, plus "native hack" spacer for args */ stackReq = method->registersSize * 8 + 4 // params + locals + sizeof(StackSaveArea) * 2 // break frame + regular frame + method->outsSize * 8 + 4; // args to other methods # else stackReq = method->registersSize * 4 // params + locals + sizeof(StackSaveArea) * 2 // break frame + regular frame + method->outsSize * 4; // args to other methods #endif
… #ifdef WITH_TAINT_TRACKING /* interleaved taint tracking plus "native hack" spacer for args */ stackPtr -= method->registersSize * 8 + 4 + sizeof(StackSaveArea); #else stackPtr -= method->registersSize * 4 + sizeof(StackSaveArea);
… /* debug -- memset the new stack, unless we want valgrind's help */ #ifdef WITH_TAINT_TRACKING memset(stackPtr - (method->outsSize*8+4), 0xaf, stackReq); #else memset(stackPtr - (method->outsSize*4), 0xaf, stackReq); |
显然TaintDroid在为interpreted方法分配DVM栈帧时对method->registersSize和method->outsSize的内存空间进行了倍增。不过这里有一点奇怪的地方,那就是method->registersSize倍增之后还加了4。其实这个加4对于interpreted方法来说是无用的,只在native方法的栈帧才有用,这里仅仅是为了后续代码的复用(因为对两种栈帧的初始化操作均在dvmCallMethodV/A函数中实现)。
结合论文第4章以及前面的分析我们就可以理解下图的意思了:
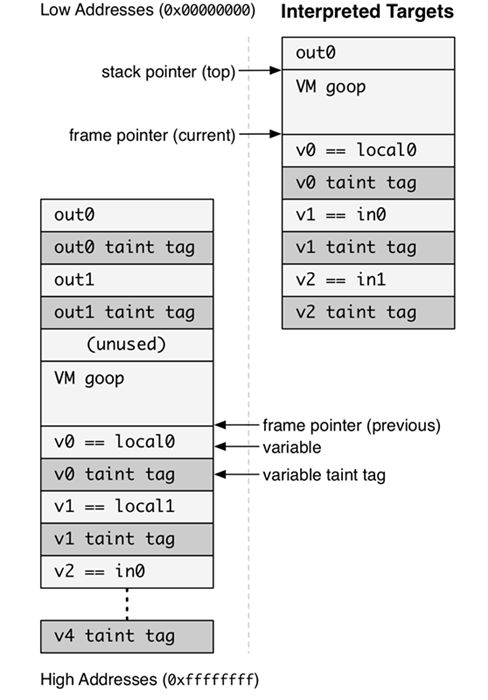
对于Interpreted方法,TaintDroid在变量(locals and ins)之间交叉存储各个变量的污点信息(taint tag)。不过细心的朋友可能会发现在DVM栈帧中,其帧指针(frame pointer)所指向的位置跟我们之前在1.3节中所描述的系统栈帧结构并不相同——前者指向的是第一个本地变量(local0)的地址,而后者却指向被保存的ebp的位置(如果我们将ebp与返回地址也看做一种输入参数的话,那么就可以理解为系统栈帧的帧指针指向的是第一个输入参数in0的位置)。原来对于DVM而言由于它在每个方法执行之前都预先确定好了该方法中所有本地变量会用到本地寄存器的个数(这就是smali代码里面每个方法前都指定了P与V寄存器个数的作用),因此它在分配栈空间的时候,就一次性将输入参数和本地变量共占用的寄存器个数分配完毕,这样fp就直接指向了本地变量之后的位置。
了解DVM栈帧与传统意义的系统栈帧之间的异同点,对我们后续分析TaintDroid如何初始化新的DVM栈帧结构极其有用。
2.2 初始化DVM栈帧
如前文所述,DVM栈帧的初始化工作在Stack.cpp的dvmCallMethodV/A函数中。虽然此函数的代码较多,但是逻辑功能并不复杂,只是需要注意帧指针的位置以及interpreted方法和native方法之间的不同处理策略即可(当前只需要关心interpreted方法的栈帧初始化)。
下面简要分析其初始化过程。
首先:
| #ifdef WITH_TAINT_TRACKING int slot_cnt = 0; bool nativeTarget = dvmIsNativeMethod(method); #endif |
在代码起初部分添加了上述代码,slot_cnt表示跳过的用于变量污点标记的个数(每个变量一个);nativeTarget表示目的方法是否为Native方法,因为TaintDroid对native方法是不会为每个变量交叉存储污点的(tag interleaving),所以这就需要根据目的方法的种类来进行相应的指令偏移计算。
然后调用callPrep为目的方法分配栈帧,其大致实现是:判断方法是否为native,如果是,则调用dvmPushJNIFrame为之分配一个JNI帧,否则调用dvmPushInterpFrame。两个方法涉及到TaintDroid对DVM栈帧的修改,前面已经分析过,这里不再细说,其最终的实现结果就是改变self->interpSave.curFrame,即此时的curFrame已经指向了目的方法的帧结构。
如果是Interp帧的话,它的帧结构的寄存器部分包含参数和本地变量,但是对于JNI帧,它的帧结构的寄存器部分只包含参数变量,是不涉及到本地变量的!所以帧结构的不同,对后续的处理思路也不同。这里先分析Interp帧。
分配完方法所需的栈帧之后:
| /* "ins" for new frame start at frame pointer plus locals */ #ifdef WITH_TAINT_TRACKING if (nativeTarget) { /*对于native方法后面再单独分析*/ } #else ins = ((u4*)self->interpSave.curFrame) + (method->registersSize - method->insSize); #endif |
然后就是根据参数的shorty描述符依次处理各个参数。在TaintDroid中的主要处理就是,将每个参数的tag变为TAINT_CLEAR。需要特别注意的是,TaintDroid在处理完参数后就调用新的dvmInterpret函数:
| #ifdef WITH_TAINT_TRACKING u4 rtaint; /* not used */ dvmInterpret(self, method, pResult, &rtaint); #else dvmInterpret(self, method, pResult); #endif |
该函数用于解释执行interpreted方法,对于TaintDroid而言,这个函数有4个参数,而原本却只有3个参数。此函数的详细功能会在后文加以分析。
至此DVM栈帧的初始化工作就分析完毕了,下一步就是分析TaintDroid是如何在已经被做过大手术的DVM栈帧上正确执行interpreted方法,也就是分析dvmInterpret的实现机制。
2.3 对dvmInterpret的分析
该函数定义在dalvik/vm/interp/Interp.cpp文件中,核心代码如下:
| #ifdef WITH_TAINT_TRACKING void dvmInterpret(Thread* self, const Method* method, JValue* pResult, u4* rtaint) //TaintDroid添加了一个参数 #else void dvmInterpret(Thread* self, const Method* method, JValue* pResult) #endif { InterpSaveState interpSaveState; ExecutionSubModes savedSubModes; …… #ifdef WITH_TAINT_TRACKING self->interpSave.rtaint.tag = TAINT_CLEAR; #endif self->interpSave.method = method; self->interpSave.curFrame = (u4*) self->interpSave.curFrame; self->interpSave.pc = method->insns; …… typedef void (*Interpreter)(Thread*); //申明一个函数指针,参数为Thread*,函数名字为Interpreter Interpreter stdInterp; if (gDvm.executionMode == kExecutionModeInterpFast) stdInterp = dvmMterpStd; #if defined(WITH_JIT) else if (gDvm.executionMode == kExecutionModeJit) stdInterp = dvmMterpStd; #endif else stdInterp = dvmInterpretPortable;
// Call the interpreter (*stdInterp)(self); //这表示调用该函数
*pResult = self->interpSave.retval; #ifdef WITH_TAINT_TRACKING *rtaint = self->interpSave.rtaint.tag; #endif ……
|
显然这里关键就是stdInterp函数的执行,它在不同的执行模式下对应不同的函数(还记得前面提到的DVM虚拟机中存在两种解释器么?),这里以dvmMterpStd为例。此函数定义在dalvik/vm/mterp/Mterp.cpp中,代码如下:
| void dvmMterpStd(Thread* self) { /* configure mterp items */ self->interpSave.methodClassDex = self->interpSave.method->clazz->pDvmDex; …… /* * Handle any ongoing profiling and prep for debugging */ if (self->interpBreak.ctl.subMode != 0) { TRACE_METHOD_ENTER(self, self->interpSave.method); self->debugIsMethodEntry = true; // Always true on startup }
dvmMterpStdRun(self);
#ifdef LOG_INSTR ALOGD("|-- Leaving interpreter loop"); #endif } |
它通过执行dvmMterpStdRun函数以真正地执行方法指令,此函数由汇编实现,代码定义在dalvik/vm/mterp/arm*/entry.S中,注意由于TaintDroid更改了栈结构以及为了实现污点传播,所以它对绝大部分opcode的汇编实现均进行了修改,下面就以简单的加法指令为例进行分析:
ps:所有opcode的汇编实现,都在vm/mterp/armv*_taint目录中。
1)首先,需要理解DVM是如何分配CPU寄存器的(不是DVM的虚拟寄存器VREG!):
| reg nick purpose |
2)再看op_add_int_2addr指令的具体实现,此指令定义在OP_ADD_INT_2ADDR.s中:
| %verify "executed" %include "armv5te_taint/binop2addr.S" {"instr":"add r0, r0, r1"} |
3)显然真正的实现在binop2addr.s:
| /* binop/2addr vA, vB */ mov r9, rINST, lsr #8 @ r9<- A+ A,B表示dvm寄存器编号 mov r3, rINST, lsr #12 @ r3<- B and r9, r9, #15 GET_VREG(r1, r3) @ r1<- vB vB,vA表示dvm寄存器的值 GET_VREG(r0, r9) @ r0<- vA .if $chkzero cmp r1, #0 @ is second operand zero? beq common_errDivideByZero .endif
// begin WITH_TAINT_TRACKING bl .L${opcode}_taint_prop // end WITH_TAINT_TRACKING FETCH_ADVANCE_INST(1) @ advance rPC, load rINST
$preinstr @ optional op; may set condition codes $instr @ $result<- op, r0-r3 changed GET_INST_OPCODE(ip) @ extract opcode from rINST SET_VREG($result, r9) @ vAA<- $result GOTO_OPCODE(ip) @ jump to next instruction /* 10-13 instructions */
%break
.L${opcode}_taint_prop: SET_TAINT_FP(r10) @以r10为基本偏移值,后续的taint系列宏都以这个r10为基准。 GET_VREG_TAINT(r3, r3, r10) @r3 <- vB的污点 GET_VREG_TAINT(r2, r9, r10) @r2 <- vA的污点 orr r2, r3, r2 @相或,r2 = r2 | r3 SET_VREG_TAINT(r2, r9, r10) @将最终的污点存储在vA的污点中,因为vA是返回值。 bx lr
|
4)GET_VREG之类的宏定义在header.s中:
| #ifdef WITH_TAINT_TRACKING #define SET_TAINT_FP(_reg) add _reg, rFP, #4 //fFP+4 #define SET_TAINT_CLEAR(_reg) mov _reg, #0 #define GET_VREG(_reg, _vreg) ldr _reg, [rFP, _vreg, lsl #3] //表示乘以8 #define SET_VREG(_reg, _vreg) str _reg, [rFP, _vreg, lsl #3] #define GET_VREG_TAINT(_reg, _vreg, _rFP) ldr _reg, [_rFP, _vreg, lsl #3] #define SET_VREG_TAINT(_reg, _vreg, _rFP) str _reg, [_rFP, _vreg, lsl #3] #else #define GET_VREG(_reg, _vreg) ldr _reg, [rFP, _vreg, lsl #2] //表示乘以4 #define SET_VREG(_reg, _vreg) str _reg, [rFP, _vreg, lsl #2] #endif /*WITH_TAINT_TRACKING*/ |
简而言之,由于TaintDroid将DVM栈帧的变量进行了倍增(由原来的4字节扩充到8字节),且交叉存储各个变量的污点信息,所以,为了能够正确地取得各个DVM虚拟寄存器VREG的数据,它将GET_VREG宏中的偏移值由以前的乘以4扩大为乘以8,以及为了设置和获取各个变量(VREG)所对应的污点信息,它还添加了SET_VRER_TAINT和GET_VREG_TAINT系列宏定义。
至此关于TaintDroid中针对各个平台优化后的由汇编代码实现的dvmMterpStd解释器如何实现对方法参数和方法变量的变量级污点跟踪机制就分析完毕了,读者可按照同样的方式自行分析TaintDroid中可移植模式的由C代码实现的dvmInterptStd解释器,这个更简单。我们将在下一篇文章中进一步分析TaintDroid对类的静态域、实例域以及数组的污点跟踪机制。
作者:简行、走位@阿里聚安全,更多技术文章,请访问阿里聚安全博客