《数据结构》复习之图
- 图的存储结构
- 1邻接矩阵
- 2邻接表
- 图的遍历
- 图的特殊算法
- 1最小生成树算法
- 2最短路径算法
- 3关键路径算法
1.图的存储结构
1.1邻接矩阵
邻接矩阵是图的顺序存储结构,由邻接矩阵的行数和列数可知图中的顶点数。对于无向图,邻接矩阵是对称的,矩阵中“1”的个数为图中总边数的2倍,矩阵中第i行或第i列的元素之和即为顶点i的度。对于有向图,矩阵中“1”的个数为图的边数,矩阵中第i行的元素之和即为顶点i的出度,第j列元素之和即为顶点j的入度。
邻接矩阵一般用二维数组表示。
1.2邻接表
邻接表是图的一种链式存储结构。所谓的邻接表就是对图中的每个顶点i建立一个单链表,每个单链表的第一个节点存放有关顶点的信息,把这一个节点看作链表的表头,其余节点存放有关边的信息。如下图所示:
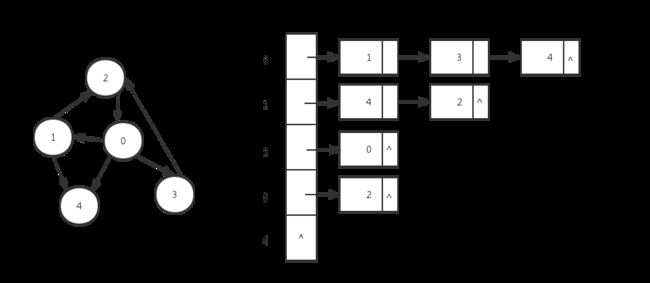
邻接表的存储表示的定义如下:
typedef struct ArcNode//边结点
{
int adjvex; //该边所指向节点的 位置
double info; //边的信息存储权值
struct ArcNode *next; //下一条边的指针
}ArcNode;
typedef struct VNode //顶点结点
{
int data; //存储节点信息
ArcNode *firstarc; //边表头指针
}VNode;
typedef struct
{
VNode adjlist[Maxsize]; //邻接表
int n; //顶点数
int e; //边数
}AGraph;当然也有简化的定义,比如不需要知道顶点信息,只需要知道边信息的简化邻接表如下:
typedef struct //简化的邻接表的边
{
int to; //该边指向的点
int val; //边的权值
int next; //下一条边序号,序号为el数组的下标
}edge;
int head[n]; //存储的是初始边的序号
edge el[e]; //边的数组2.图的遍历
图的遍历算法主要有深度优先搜索遍历(DFS)和广度优先搜索遍历(BFS),具体的思想不再做阐述,这边我们给出邻接矩阵形式的图的遍历和邻接表的图的遍历。
- 邻接矩阵的图的遍历代码:
#include<iostream>
#include<queue>
using namespace std;
int visit[50];
int map[50][50];
void dfs(int k,int n) //深搜,参数n为图的顶点数
{
int i;
cout<<k<<" ";
visit[k]=1;//千万不要忘
for(i=0;i<n;i++)
{
if(map[k][i]==1&&visit[i]==0)
dfs(i,n);
}
}
void bfs(int n) //广搜
{
int temp,i;
queue<int> q;
visit[0]=1; //注意广搜的时候必须是先访问后入队
cout<<0<<" ";
q.push(0);
while(!q.empty())
{
temp=q.front();
q.pop();
for(i=0;i<n;i++)
{
if(map[temp][i]==1&&visit[i]==0)
{
visit[i]=1;
cout<<i<<" ";
q.push(i);
}
}
}
}
int main()
{
int n,i,j;
cin>>n;
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
{
cin>>map[i][j];
}
}
for(i=0;i<n;i++)
{
visit[i]=0;
}
for(i=0;i<n;i++) //每个顶点都要访问到
{
if(visit[i]==0)
{
bfs(n);
//dfs(n);
}
}
cout<<endl;
return 0;
} - 邻接表的图的遍历代码:
#include<iostream>
#include<string.h>
#include<queue>
using namespace std;
typedef struct //简化的邻接表的边
{
int to;
int next;
}edge;
int ednum;
int *head;
int *visit;
edge *el;
void adde(int x, int y) //增加边数
{
el[ednum].to = y;
el[ednum].next = head[x];
head[x] = ednum;
ednum++;
}
void dfs(int x) //深搜
{
int i;
visit[x] = 1;
cout << x << " ";
for (i = head[x]; i != -1; i = el[i].next)
{
if (visit[el[i].to] == 0)
{
dfs(el[i].to);
}
}
}
void bfs(int x) //广搜
{
int temp, temp2;
queue<int> q;
cout << x << " ";
visit[x] = 1;
q.push(x);
while (!q.empty())
{
temp = q.front();
q.pop();
temp2 = head[temp];
while (temp2 != -1)
{
if (visit[el[temp2].to] == 0)
{
cout << el[temp2].to << " ";
visit[el[temp2].to] = 1;
q.push(el[temp2].to);
}
temp2 = el[temp2].next;
}
}
}
int main()
{
int n, m, temp, x, y, i, flag;
while (cin >> n >> m, n != 0)
{
flag = 0;
head = new int[n + 1];
visit = new int[n + 1];
el = new edge[2 * m];
memset(head, -1, sizeof(int)*(n + 1));
memset(visit, 0, sizeof(int)*(n + 1));
temp = m;
ednum = 0;
while (temp > 0)
{
cin >> x >> y;
adde(x, y);
adde(y, x);
temp--;
}
for (int i = 1; i <= n; ++i) //深搜
{
if (visit[i] == 0)
{
dfs(i);
// bfs(i);
}
}
cout << endl;
delete[] head;
delete[] visit;
delete[] el;
}
return 0;
}
不管是深搜还是广搜都是图的算法的重要组成部分,也是解决很多图的问题模板方法。
3.图的特殊算法
归纳一下,图的特殊算法包括,最小生成树算法(Prim算法和Kruskal算法),最短路径算法( Dijkstra算法和Floyd算法),拓扑排序和关键路径。如图所示:
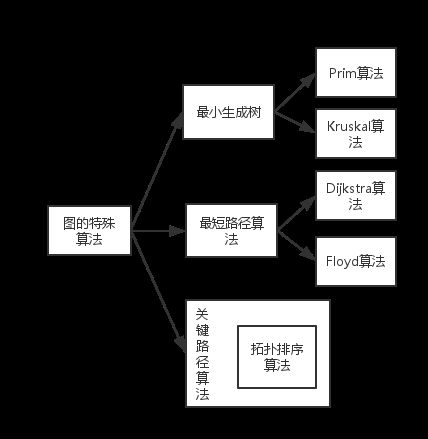
3.1最小生成树算法
- Prim算法
算法思想:
从图中任意取出一个顶点,把它当做一棵树,然后从与这棵树相接的边中选取一条最短(权值最小)的边,并将这条边及其所连接的顶点也并入这棵树中,此时得到了一棵有两个顶点的树。然后从与这棵树相接的边中选取一条最短的边,并将这条边及其所连顶点并入当前树中,得到一棵3个顶点的树。以此类推,直到图中所有顶点都被并入树中为止,此时得到的生成树就是最小生成树。
程序的过程可以如下表示:
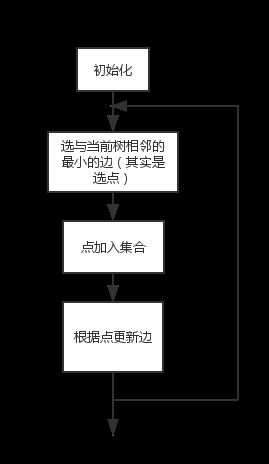
算法的代码如下:
#define MaxSize 100
#define INFINITE 9999
#include<iostream>
using namespace std;
int Graph[MaxSize + 1][MaxSize + 1];
int Prim(int n) //Prim算法的时间复杂度只与图中的顶点有关系,与边数没有关系。
{
int sum = 0;
int mincost[MaxSize + 1];
int minset[MaxSize + 1];
bool set[MaxSize + 1];
set[1] = true; //假设从1开始
for (int i = 2; i <= n; i++) //算出第一个点的情况
{
mincost[i] = Graph[1][i];
minset[i] = 1;
set[i] = false;
}
for (int i = 1; i < n; i++) //循环n-1次 1.选最小的 2.加入集合 3.更新边
{
int min = INFINITE;
int j = 1;
for (int k = 2; k <= n; k++) //找出最小的边
{
if (mincost[k] < min && (!set[k]))
{
min = mincost[k];
j = k;
}
}
cout << j << " " << minset[j] << endl;
set[j] = true;
sum += min;
for (int k = 2; k <= n; k++)
{
if (Graph[j][k] < mincost[k] && (!set[k])) //为什么不会有回路,因为每次加入的点都是不在集合中的
{
mincost[k] = Graph[j][k];
minset[k] = j;
}
}
}
return sum;
}
int main()
{
int n, m;
int x1, x2, x3;
cout << "创建图,请输入顶点个数:" << endl;
cin >> n;
cout << "请输入边条数:" << endl;
cin >> m;
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= n; j++)
{
Graph[i][j] = INFINITE;
}
}
cout << "现在请输入相连的信息(格式:顶点1(空格)顶点2(空格)权值):" << endl;
for (int i = 1; i <= m; i++)
{
cin >> x1 >> x2 >> x3;
Graph[x1][x2] = x3;
Graph[x2][x1] = x3;
}
cout << "最小生成树是:" << endl;
int sum = Prim(n);
cout << "最小权值是:" << sum << endl;
return 0;
} 时间复杂度分析:
Prim算法主要是一个双重循环,因此时间复杂度为O(n2)。由算法可见,Prim算法的时间复杂度只与图中的顶点有关系,与边数没有关系,因此Prim算法适用于稠密图。
- Kruskal算法
算法思想:
将图中边按照权值从小到大排序,然后从最小边开始扫描各边,并检测当前边是否为候选边,即是否该边的并入会构成回路,如不构成回路,则将该边并入当前的生成树,直到所有边都被检测完为止。
判断回路需要用到并查集。并查在这里不做多的介绍,可参考http://blog.csdn.net/dellaserss/article/details/7724401/
算法代码如下:
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
typedef struct L
{
int i;
int j;
int val;
}L;
int map[50][50];
bool compare(L a,L b)
{
return a.val<b.val;
}
int find(int r,int pre[])
{
while(r!=pre[r])
r=pre[r];
return r;
}
int main()
{
int sum=0;
int n,i,j;
cin>>n;
vector <L> eu;
L temp;
for(i=0;i<n;i++)
{
for(j=0;j<n;j++)
{
cin>>map[i][j];
if(map[i][j]&&i>j) //无向图,只要记住一条边就行,用i>j来筛选
{
temp.val=map[i][j];
temp.i=i;
temp.j=j;
eu.push_back(temp);
}
}
}
int length=eu.size();
int pre[length];
sort(eu.begin(),eu.end(),compare);
for(i=0;i<length;i++)
{
pre[i]=i;
}
int k;
for(k=0;k<length;k++)
{
if(find(eu[k].i,pre)!=find(eu[k].j,pre))
{
pre[eu[k].i]=eu[k].j;
sum+=eu[k].val;
}
}
cout<<sum<<endl;
return 0;
}
时间复杂度分析:
从上述代码可以发现,Kruskal算法的时间主要话费在sort()函数和单循环上,由于循环是线性的,可以认为算法时间主要花费在sort()函数上。因此Kruskal算法的时间复杂度由排序算法决定。排序算法所处理数据规模由图的边数e决定,与顶点数无关,因此Kruskal算法适用于稀疏图。
3.2最短路径算法
Dijkstra算法
算法思想:
设有两个顶点集合S和T,集合S中存放图中已找到最短路径的顶点,集合T存放图中剩余顶点。初始状态时,集合S中只包含源点v0,然后不断从集合T中选取到顶点v0路径长度最短的顶点vu并入到集合S中。集合S每并入一个新的顶点vu,都要修改顶点v0到集合T中顶点的最短路径长度值。不断重复此过程,直到集合T的顶点全部并入到S中为止。
算法代码如下:
#define INF 99999
#include<iostream>
#include<set>
using namespace std;
int map[50][50];
int main()
{
int n, i, j, s;
cin >> n >> s;
int *dis=new int[n];
for (i = 0; i<n; i++)
{
for (j = 0; j<n; j++)
{
cin >> map[i][j]; //要注意输入的时候0相当于无穷不能直接用
if (map[i][j] == 0)
{
map[i][j] = INF;
}
if (i == s)
{
dis[j] = map[i][j];
}
}
}
set <int> uion;
uion.insert(s);
int minval;
int flag;
while (uion.size() != n)
{
minval = INF;
for (i = 0; i<n; i++)
{
if ((uion.find(i) == uion.end()) && dis[i]<=minval) //==才是没有找到,!=是找到了
{
minval = dis[i];
flag = i;
}
}
uion.insert(flag);
for (i = 0; i<n; i++)
{
if ((uion.find(i) == uion.end()) && dis[i]>dis[flag] + map[flag][i])
{
dis[i]=dis[flag] + map[flag][i];
}
}
}
for (i = 0; i<n; i++)
{
if (i != s)
{
cout << dis[i] << " ";
}
}
cout << endl;
return 0;
}
Dijkstra算法和Prim算法的异同点:
可以看到Dijkstra算法和Prim算法非常相似,它们都有如下的过程:
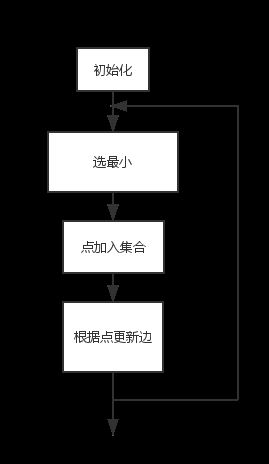
但是它们的目的是不同的,Prim算法是求最小生成树,Dijkstra算法是求最短路径,Prim算法是找当前树到树之外其余点的最小边,Dijkstras算法是找起点到其余点的距离最小值,必须要搞清楚其区别不能搞混。
Dijkstra算法的时间复杂度:O(n2)(双重循环)
Dijkstra算法的另一种变形:SPFA算法
SPFA(Shortest Path Faster Algorithm)(队列优化)算法是求单源最短路径的一种算法。很多时候,给定的图存在负权边,这时类似Dijkstra算法等便没有了用武之地。这时就可以用SPFA算法。直接贴代码:
#define INF 99999
#include<iostream>
#include<queue>
using namespace std;
int map[50][50];
int *dis;
int visit[50];
int relax(int u, int v)
{
if (dis[v]>dis[u] + map[u][v])
{
dis[v] = dis[u] + map[u][v];
return 1;
}
else
{
return 0;
}
}
void SPFA(int src, int n)
{
int i, x, temp;
dis[src] = 0;
queue<int> q;
q.push(src);
visit[src] = 1;
while (!q.empty())
{
x = q.front();
q.pop();
visit[x] = 0;
for (i = 0; i<n; i++)
{
if (map[x][i] != -1&&visit[i]==0&&relax(x, i))
{
q.push(i);
}
}
}
}
int main()
{
int n, i, j, s;
cin >> n >> s;
dis = new int[n];
for (i = 0; i<n; i++)
{
for (j = 0; j<n; j++)
{
cin >> map[i][j]; //要注意输入的时候0相当于无穷不能直接用
if (map[i][j] == 0)
{
map[i][j] = -1;
}
}
}
for (i = 0; i<n; i++)
{
dis[i] = INF;
visit[i] = 0;
}
SPFA(s, n);
for (i = 0; i<n; i++)
{
if (i != s)
{
if (dis[i] != INF)
{
cout << dis[i] << " ";
}
else
{
cout << -1 << " ";
}
}
}
cout << endl;
return 0;
}
Floyd算法
Floyd算法代码相对简单,但时间复杂度较高。它的算法思想是以k为中间点对所有的顶点{i,j}进行检测和修改
代码如下:
#define INF 99999
#include<iostream>
using namespace std;
int map[50][50];
int path[50][50]; //用于记录路径
int main()
{
int n, i, j;
cin >> n ;
for (i = 0; i<n; i++)
{
for (j = 0; j<n; j++)
{
cin >> map[i][j]; //要注意输入的时候0相当于无穷不能直接用
if (map[i][j] == 0&&i!=j)
{
map[i][j] = INF;
}
result[i][j] = map[i][j];
path[i][j]=-1;
}
}
for (int k = 0; k < n; k++)
{
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++)
{
if (result[i][j] > result[i][k] + result[k][j])
{
result[i][j] = result[i][k] + result[k][j];
path[i][j]=k;
}
}
}
}
for (i = 0; i<n; i++)
{
for (j = 0; j < n; j++)
{
if (result[i][j] != INF)
{
cout << result[i][j] << " ";
}
else{
cout << -1 << " ";
}
}
cout << endl;
}
cout << endl;
return 0;
} Floyd算法的时间复杂度:O(n3)(三层循环)
Floyd算法和Dijkstra算法用法的区别:Dijkstra算法是求图中某一顶点都其余各顶点的最短路径,而Floyd算法是求图中任意一对顶点间的最短路径。当然Dijkstra算法的时间复杂度要远远小于Floyd算法。
3.3关键路径算法
介绍一下拓扑排序算法:
在一个有向图中找到一个拓扑排序序列的过程如下:
1) 从有向图中选择一个没有前驱(入度为0)的顶点输出
2) 删除1)中的顶点,并且删除从该顶点发出的全部边
3) 重复上述两步,直到剩余的网中不存在没有前驱的顶点为止。
拓扑排序可以判断是否有环路,若顶点均被删除(有拓扑排序)则无环路,(无拓扑排序)否则有环路。(其实深搜就能判断是否有环路,对于无向图来说,若深搜的过程中遇到了回边,即检测到visit[i]不为0,则必定存在回环。对于有向图则不那么简单,如果从有向图中的某个顶点v出发进行深搜,若在顶点v处遍历其他邻接顶点过程结束前出现一条从顶点u指向v的回边,则有向图必定包含v和u的环)。
拓扑排序若以邻接表为结构,则根据上述过程,要在顶点结点出加count来统计当前结点的入度,顶点结点结构体如下:
typedef struct VNode
{
int data;
int count; //用来统计顶点当前入度
ArcNode *firstarc;
}VNode;算法代码如下:
int TopSort(AGraph *G)
{
int i,j,n=0;
int stack[maxSize],top=-1;
ArcNode *p;
for(i=0;i<=G->n;i++)//将图中入度为0的顶点入栈
{
if (G->adjlist[i].count==0)
{
stack[top++]=i;
}
while(top!=-1)
{
i=stack[top--];
++n;
cout<<i<<" ";
p=G->adjlist[i].firstarc;
/*下面的循环实现了将所有由此顶点引出的边所指向的顶点的入度都减少1,并将这个过程中入度变为0的顶点入栈*/
while(p!=NULL)
{
j=p->adjvex;
--(G->adjlist[j].count)
if (G->adjlist[j].count==0)
{
stack[++top]=j;
}
p=p->nextarc;
}
}
if (n==G->n)
{
return 1;//n==顶点数,说明拓扑排序成功
}
else
{
return 0;
}
}
}关键路径核心算法:关键路径的算法由于篇幅太长,暂时没有写。