使用Spark Streaming + Kudu + Impala构建一个预测引擎
随着用户使用天数的增加,不管你的业务是扩大还是缩减了,为什么你的大数据中心架构保持线性增长的趋势?很明显需要一个稳定的基本架构来保障你的业务线。当你的客户处在休眠期,或者你的业务处在淡季,你增加的计算资源就处在浪费阶段;相对应地,当你的业务在旺季期,或者每周一每个人对上周的数据进行查询分析,有多少次你忒想拥有额外的计算资源。
根据需求水平动态分配资源 VS 固定的资源分配方式,似乎不太好实现。幸运的是,借助于现今强大的开源技术,可以很轻松的实现你所愿。在这篇文章中,我将给出一个解决例子,基于流式API数据来演示如何预测资源需求变化来调整资源分配。
我们旨在用流式回归模型预测接下来十分钟的海量事件数据,并与传统批处理的方法预测的结果进行对比。这个预测结果可用来动态规划计算机资源,或者业务优化。传统的批处理方法预测采用Impala和Spark两种方法,动态预测使用Spark Streaming。
任何预测的起点是基于海量历史数据和实时更新的数据来预测未来的数据业务。流式API提供稳定的流失RSVP数据,用来预测未来一段时间RSVP数据。
动态资源分配预测架构图
这个例子的数据通过流式API进入Kafka,然后使用Spark Streaming从Kafka加载数据到Kudu。Kafka允许数据同时进入两个独立的Spark Streaming作业:一个用来进行特征工程;一个用来使用MLlib进行流式预测。预测的结果存储在Kudu中,我们也可以使用Impala或者Spark SQL进行交互式查询,见图1。
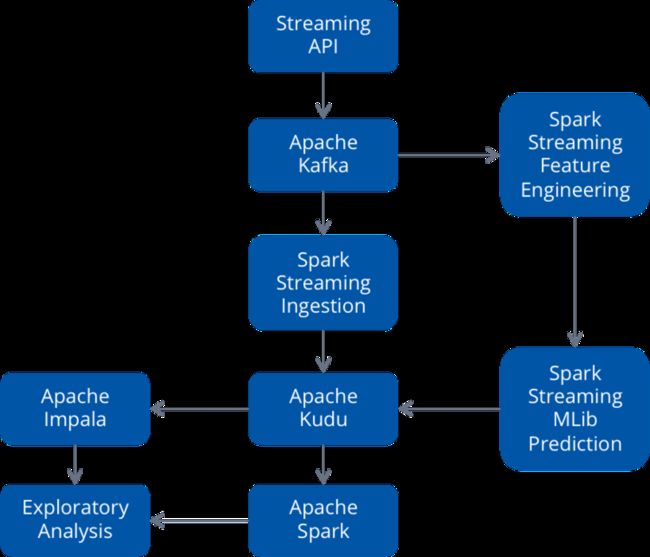
图1
你可能急切想知道我的技术选型,下面是一些技术概要:
- Kafka:Kafka可抽象数据输入,支持扩展,并耦合Spark Streaming框架。Kafka拥有每秒处理百万事件的扩展能力,并能和其他各项技术集成,比如,Spark Streaming。
- Spark Streaming:Spark Streaming能够处理复杂的流式事件,并且采用Scala编程仅需简单的几行代码即可,也支持Java、Python或者R语言。Spark Streaming提供和Kafka、MLlib(Spark的机器学习库)的集成。
Apache Kudu:Kudu支持事件的增量插入,它旨在提供一种基于HDFS(HDFS优势在于大数据存储下的快速扫描能力)和HBase(HBase优势是基于主键的快速插入/查询)之间超存储层。本项目可以采用HBase或者Cassandra,但Kudu为数据分析提供了快速的扫描能力、列式存储架构。
- Impala:使用Impala可很容易的即席查询。它提供一个查询引擎直接查询加载到Kudu上的数据,并能理解生成模型。作为可选的方案可使用Spark SQL,但这里为了比较使用MADlib库训练的回归模型和使用Saprk MLlib训练的模型,故用Impala。
构建实例
现在解释下架构的选择,详细细节如下:
首先,粗略浏览一下流式数据源。通过Kafka来监测文件,tail文件变化发送到Kafka,部分代码见Github。下面给出RSVP内容样例:
{"response":"yes","member":{"member_name":"Richard
Williamson","photo":"http:\/\/photos3.meetupstatic.com\/photos\/member\/d\/a\/4\/0\/thu
mb_231595872.jpeg","member_id":29193652},"visibility":"public","event":
{"time":1424223000000,"event_url":"http:\/\/www.meetup.com\/Big-Data-
Science\/events\/217322312\/","event_id":"fbtgdlytdbbc","event_name":"Big Data Science
@Strata Conference,
2015"},"guests":0,"mtime":1424020205391,"rsvp_id":1536654666,"group":{"group_name":"Big
Data
Science","group_state":"CA","group_city":"Fremont","group_lat":37.52,"group_urlname":"Big-
Data-Science","group_id":3168962,"group_country":"us","group_topics":
[{"urlkey":"data-visualization","topic_name":"Data Visualization"},{"urlkey":"data-
mining","topic_name":"Data Mining"},{"urlkey":"businessintell","topic_name":"Business
Intelligence"},{"urlkey":"mapreduce","topic_name":"MapReduce"},
{"urlkey":"hadoop","topic_name":"Hadoop"},{"urlkey":"opensource","topic_name":"Open
Source"},{"urlkey":"r-project-for-statistical-computing","topic_name":"R Project for Statistical
Computing"},{"urlkey":"predictive-analytics","topic_name":"Predictive Analytics"},
{"urlkey":"cloud-computing","topic_name":"Cloud Computing"},{"urlkey":"big-
data","topic_name":"Big Data"},{"urlkey":"data-science","topic_name":"Data Science"},
{"urlkey":"data-analytics","topic_name":"Data Analytics"},
{"urlkey":"hbase","topic_name":"HBase"},
{"urlkey":"hive","topic_name":"Hive"}],"group_lon":-121.93},"venue":
{"lon":-121.889122,"venue_name":"San Jose Convention Center, Room
210AE","venue_id":21805972,"lat":37.330341}}
一旦Kafka运行起来,数据从Kafka经过Spark Streaming进入Kudu,代码见这里。
流式作业在Kudu上初始化一个表,接着运行Spark Streaming加载数据到数据表。你可以创建一个Impala外部表,并指向Kudu上存储的数据。
CREATE EXTERNAL TABLE `kudu_meetup_rsvps` ( `event_id` STRING, `member_id` INT, `rsvp_id` INT, `event_name` STRING, `event_url` STRING, `TIME` BIGINT, `guests` INT, `member_name` STRING, `facebook_identifier` STRING, `linkedin_identifier` STRING, `twitter_identifier` STRING, `photo` STRING, `mtime` BIGINT, `response` STRING, `lat` DOUBLE, `lon` DOUBLE, `venue_id` INT, `venue_name` STRING, `visibility` STRING ) TBLPROPERTIES( 'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler', 'kudu.table_name' = 'kudu_meetup_rsvps', 'kudu.master_addresses' = 'quickstart.cloudera:7051', 'kudu.key_columns' = 'event_id, member_id, rsvp_id' );
紧接着用Impala表查询获得小时RSVP数据:
create
table rsvps_by_hour as
select from_unixtime(cast(mtime/1000 as bigint), "yyyy-MM-dd") as mdate
,cast(from_unixtime(cast(mtime/1000 as bigint), "HH") as int) as mhour
,count(*) as rsvp_cnt
from kudu_meetup_rsvps
group
by 1,2
有了RSVP数据后可以画随时间的变化图,见图2:
图2
接着可以进行特征工程,为了后续可以直接用Impala建立预测模型:
create
table rsvps_by_hr_training as
select
case when mhour=0 then 1 else 0 end as hr0
,case when mhour=1 then 1 else 0 end as hr1
,case when mhour=2 then 1 else 0 end as hr2
,case when mhour=3 then 1 else 0 end as hr3
,case when mhour=4 then 1 else 0 end as hr4
,case when mhour=5 then 1 else 0 end as hr5
,case when mhour=6 then 1 else 0 end as hr6
,case when mhour=7 then 1 else 0 end as hr7
,case when mhour=8 then 1 else 0 end as hr8
,case when mhour=9 then 1 else 0 end as hr9
,case when mhour=10 then 1 else 0 end as hr10
,case when mhour=11 then 1 else 0 end as hr11
,case when mhour=12 then 1 else 0 end as hr12
,case when mhour=13 then 1 else 0 end as hr13
,case when mhour=14 then 1 else 0 end as hr14
,case when mhour=15 then 1 else 0 end as hr15
,case when mhour=16 then 1 else 0 end as hr16
,case when mhour=17 then 1 else 0 end as hr17
,case when mhour=18 then 1 else 0 end as hr18
,case when mhour=19 then 1 else 0 end as hr19
,case when mhour=20 then 1 else 0 end as hr20
,case when mhour=21 then 1 else 0 end as hr21
,case when mhour=22 then 1 else 0 end as hr22
,case when mhour=23 then 1 else 0 end as hr23
,case when mdate in ("2015-02-14","2015-02-15") then 1 else 0 end as weekend_day
,mdate
,mhour
,rsvp_cnt
from rsvps_by_hour;
在Impala上安装MADlib,这样就可以直接在Impala上构建回归模型。
采用MADlib训练回归模型的第一步:
select printarray(linr(toarray(hr0,hr1,hr2,hr3,hr4,hr5,hr6,hr7,hr8,hr9,hr10,hr11,hr12,hr13,hr14, hr15,hr16,hr17,hr18,hr19,hr20,hr21,hr22,hr23,weekend_day), rsvp_cnt)) from rsvps_by_hr_training;
下面展示回归系数。你可看到前面的24个系数显示了一天的按小时趋势,在晚上很少的人在线;最后一个系数是周末,如果是周末的话,系数是负值。
Feature Coefficient hr0 8037.43 hr1 7883.93 hr2 7007.68 hr3 6851.91 hr4 6307.91 hr5 5468.24 hr6 4792.58 hr7 4336.91 hr8 4330.24 hr9 4360.91 hr10 4373.24 hr11 4711.58 hr12 5649.91 hr13 6752.24 hr14 8056.24 hr15 9042.58 hr16 9761.37 hr17 10205.9 hr18 10365.6 hr19 10048.6 hr20 9946.12 hr21 9538.87 hr22 9984.37 hr23 9115.12 weekend_day -2323.73
通过上述系数进行预测:
select mdate,
mhour,
cast(linrpredict(toarray(8037.43, 7883.93, 7007.68, 6851.91,
6307.91, 5468.24, 4792.58, 4336.91, 4330.24, 4360.91, 4373.24, 4711.58, 5649.91,
6752.24, 8056.24, 9042.58, 9761.37, 10205.9, 10365.6, 10048.6, 9946.12,
9538.87, 9984.37, 9115.12, -2323.73), toarray(hr0, hr1, hr2, hr3, hr4,
hr5, hr6, hr7, hr8, hr9, hr10, hr11, hr12, hr13, hr14, hr15, hr16, hr17,
hr18, hr19, hr20, hr21, hr22, hr23, weekend_day)) as int) as rsvp_cnt_pred,
rsvp_cnt
from rsvps_by_hr_testing
图3 按小时对比预测数据和RSVP真实值,由于数据有限,只列出两天的预测。
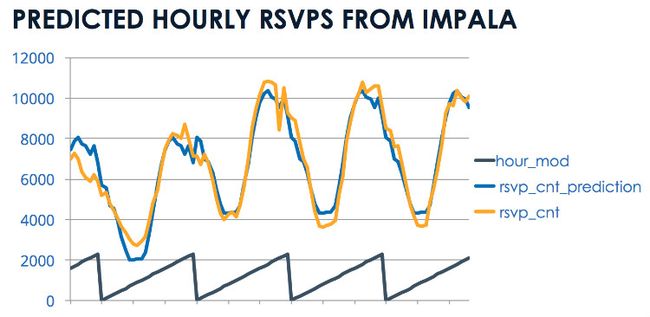
图3
使用Spark MLlib训练模型
下面使用Spark MLlib建立类似的模型,在海量数据下这种方式更优吸引力。
首先,Spark加载JSON文件并使用Spark SQL注册为一张表。你也可以直接从Kudu加载数据,但此列子直接用Spark读取JSON文件。
val path = "/home/demo/meetupstream1M.json"
val meetup = sqlContext.read.json(path)
meetup.registerTempTable("meetup")
你可以使用Spark SQL运行一个类似在前面Impala中使用的查询语句来获取小时的RSVP数据:
val meetup2 = sqlContext.sql("
select from_unixtime(cast(mtime/1000 as bigint), 'yyyy-MM-dd') as dy,
case when from_unixtime(cast(mtime/1000 as bigint),'yyyy-MM-dd') in ('2015-02-14','2015-02-15') then 1 else 0 end as weekend_day,
from_unixtime(cast(mtime/1000 as bigint), 'HH') as hr,
count(*) as rsvp_cnt
from meetup
where from_unixtime(cast(mtime/1000 as bigint), 'yyyy-MM-dd') >= '2015-10-30'
group
by from_unixtime(cast(mtime/1000 as bigint), 'yyyy-MM-dd'),
from_unixtime(cast(mtime/1000 as bigint), 'HH')")
接下来,创建特征向量。你可以参照前面类的方法做特征工程,但这里介绍一个Andrew Ray的简便方法,使用一句话即可实现特征向量:
val meetup3 = meetup2.groupBy("dy","weekend_day","hr","rsvp_cnt").pivot("hr").count().orderBy("dy")
现在有了这些数据,可以训练回归模型了:
import org.apache.spark.mllib.regression.RidgeRegressionWithSGD
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
val trainingData = meetup3.map { row =>
val features = Array[Double](1.0,row(1).toString().toDouble,row(4).toString().toDouble,
row(5).toString().toDouble,row(6).toString().toDouble,
row(7).toString().toDouble,row(8).toString().toDouble,
row(9).toString().toDouble,row(10).toString().toDouble,
row(11).toString().toDouble,row(12).toString().toDouble,
row(13).toString().toDouble,row(14).toString().toDouble,
row(15).toString().toDouble,row(16).toString().toDouble,
row(17).toString().toDouble,row(18).toString().toDouble,
row(19).toString().toDouble,row(20).toString().toDouble,
row(21).toString().toDouble,row(22).toString().toDouble,
row(23).toString().toDouble,row(24).toString().toDouble,
row(25).toString().toDouble,row(26).toString().toDouble,
row(27).toString().toDouble)
LabeledPoint(row(3).toString().toDouble, Vectors.dense(features))
}
trainingData.cache()
val model = new RidgeRegressionWithSGD().run(trainingData)
得到一个新的数据集评分,
val scores = meetup3.map { row =>
val features = Vectors.dense(Array[Double](1.0,row(1).toString().toDouble,
row(4).toString().toDouble,row(5).toString().toDouble,
row(6).toString().toDouble,row(7).toString().toDouble,
row(8).toString().toDouble,row(9).toString().toDouble,
row(10).toString().toDouble,row(11).toString().toDouble,
row(12).toString().toDouble,row(13).toString().toDouble,
row(14).toString().toDouble,row(15).toString().toDouble,
row(16).toString().toDouble,row(17).toString().toDouble,
row(18).toString().toDouble,row(19).toString().toDouble,
row(20).toString().toDouble,row(21).toString().toDouble,
row(22).toString().toDouble,row(23).toString().toDouble,
row(24).toString().toDouble,row(25).toString().toDouble,
row(26).toString().toDouble,row(27).toString().toDouble))
(row(0),row(2),row(3), model.predict(features))
}
scores.foreach(println)
图4描述Spark模型结果和真实RSVP数据的对比。
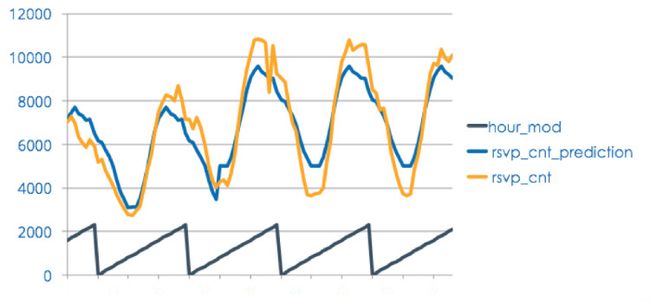
图4
使用Spark Streaming建立回归模型
前面的两个例子展示了我们如何基于批处理数据构建模型和即席查询,现在开始建立一个Spark Streaming回归模型。使用流式的方法建立模型使得我们可以更频繁的更新模型,获取最新的数据,预测也更准确。
这里可能和批处理的方法稍有不同。为了展示使用流式回归模型,这里简单的使用每分钟的RSVP数据(替代前面批量预测中按小时处理)来生成连续的流数据来预测接下来的十分钟内的数据。
首先,使用Kafka来输入数据,代码见这里。这部分代码简单的设置Kafka为输入源,设置topic、broker list和Spark Streaming作为输入参数,它可以连接Kafka并获取数据。
def loadDataFromKafka(topics: String,
brokerList: String,
ssc: StreamingContext): DStream[String] = {
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]
("metadata.broker.list" -> brokerList)
val messages = KafkaUtils.createDirectStream[String,
String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
messages.map(_._2)
}
val dstream = loadDataFromKafka(topics, brokerList, ssc)
对DStream进行transform操作获得RSVP值:
val stream = dstream.transform { rdd =>
val parsed1 = sqlContext.read.json(rdd)
parsed1.registerTempTable("parsed1")
val parsed2 = sqlContext.sql("
select m,
cnt,
mtime
from (select (round(mtime/60000)-(" + current_time + "/60000 ))/1000.0 as m,
count(*) as cnt,
round(mtime/60000) as mtime
from (select distinct * from parsed1) a
group
by (round(mtime/60000)-(" + current_time + "/60000 ))/1000.0,
round(mtime/60000) ) aa
where cnt > 20
")
parsed2.rdd
}
stream.print()
转换数据结构来训练模型:一个数据流为训练数据,actl_stream;另一个数据流用来预测,pred_stream。预测数据流为当前训练数据流时刻的下一个10分钟时间间隔。
val actl_stream = stream.map(x =>
LabeledPoint(x(1).toString.toDouble,Vectors.dense(Array(1.0,x(0).toString.toDouble))) ).cache()
actl_stream.print()
val pred_stream = stream.map(x =>
LabeledPoint((x(2).toString.toDouble+10)*60000,Vectors.dense(Array(1.0,x(0).toString.toDouble))) )
pred_stream.print()
用时间间隔的数据作为特征训练流式模型,这里的场景非常简单,只是为了说明问题。实际的产品模型需要结合前面讨论的按天和周末的模型来提高预测的准确性。
val numFeatures = 2
val model = new StreamingLinearRegressionWithSGD().setInitialWeights(Vectors.zeros(numFeatures)
model.trainOn(actl_stream)
最后,应用预测模型对下一个时间间隔的数据进行预测:
val rslt_stream = model.predictOnValues(pred_stream.map(lp => (lp.label, lp.features)))
rslt_stream.print()
图5为流式模型预测的结果。
图5
如你所见,假如我们利用最近十分钟的RSVP数据,可以更好的预测接下来的十分钟左右的数据。将来为了更好的预测需要考虑增加更多的特征来提高模型的健壮性。预测的结果流式的写入Kudu,使用API可以很容易的使用这些预测数据来自动的分配资源。