UFLDL教程答案(5):Exercise:Self-Taught Learning
教程地址:http://deeplearning.stanford.edu/wiki/index.php/%E8%87%AA%E6%88%91%E5%AD%A6%E4%B9%A0
练习地址:http://deeplearning.stanford.edu/wiki/index.php/Exercise:Self-Taught_Learning
1.习惯性废话几句
1.这个练习要把之前的稀疏自编码器与softmax组合来进行手写数字的分类:
先训练稀疏自编码器提取特征,再把特征和label给softmax分类器进行训练,最后用test数据集进行测试。
2.unlabeledData(784*29404)用于训练自编码器,非监督;trainData(784*15298)用于训练softmax,监督;testData(784*15298)用于测试。
3.由于实际应用中找到大量有标注的样本是非常困难的,所有采用先用大量无标注样本来进行无监督训练自编码器,再用自编码器来提取特征,配合有标注样本来进行有监督训练softmax分类器。
4.数据预处理方面:例如,如果对未标注数据集进行PCA预处理,就必须将得到的矩阵 ![]() 保存起来,并且应用到有标注训练集和测试集上;而不能使用有标注训练集重新估计出一个不同的矩阵
保存起来,并且应用到有标注训练集和测试集上;而不能使用有标注训练集重新估计出一个不同的矩阵![]() (也不能重新计算均值并做均值标准化),否则的话可能得到一个完全不一致的数据预处理操作,导致进入自编码器的数据分布迥异于训练自编码器时的数据分布。
(也不能重新计算均值并做均值标准化),否则的话可能得到一个完全不一致的数据预处理操作,导致进入自编码器的数据分布迥异于训练自编码器时的数据分布。
5.自学习(self-taught learning) 不要求未标注数据 ![]() 和已标注数据
和已标注数据![]() 来自同样的分布。另外一种带限制性的方式也被称为半监督学习,它要求
来自同样的分布。另外一种带限制性的方式也被称为半监督学习,它要求![]() 和
和![]() 服从同样的分布。
服从同样的分布。
2.进入正题
Step 2: Train the sparse autoencoder
opttheta = theta;
% Use minFunc to minimize the function
addpath minFunc/
options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
% function. Generally, for minFunc to work, you
% need a function pointer with two outputs: the
% function value and the gradient. In our problem,
% sparseAutoencoderCost.m satisfies this.
options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
options.display = 'on';
[opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
inputSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, unlabeledData), ...
theta, options);
效果图:
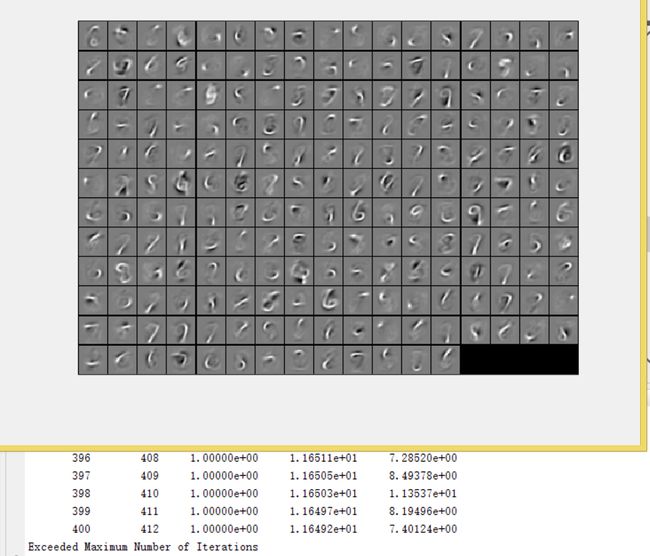
Step 3: Extracting features(feedForwardAutoencoder.m)
根据前面无监督训练计算出的稀疏自编码器的参数,前向传播提取trainData和testData的特征:trainFeatures和testFeatures(均为200*15298)
m=size(data,2); %15298 B1=repmat(b1,1,m); z=W1*data+B1; activation=sigmoid(z);%(200*15298)
Step 4: Training and testing the logistic regression model
把之前softmax相关的m文件拷贝过来
lambda = 1e-4;
options.maxIter = 100;
softmaxModel = softmaxTrain(hiddenSize, numLabels, lambda, ...
trainFeatures, trainLabels, options);
Step 5: Classifying on the test set
[pred] = softmaxPredict(softmaxModel, testFeatures);
最后结果:
Test Accuracy: 98.306968%