【JavaScript】DOM
DOM描绘了一个层次化的节点树,允许开发人员添加、删除和修改页面的某一部分
一、DOM
1、Node类型
JavaScript中的所有节点都继承自Node类型,因此,所有节点类型都共享着相同的基本属性和方法。每个节点都有一个nodeType属性,用于表明节点的类型。
要了解节点的具体信息,可以使用nodeName和nodeValue这两个属性。对于元素节点,nodeName属性中保存的始终是元素的标签名,而nodeValue的值则始终为null。
(1)节点关系
每个节点都有一个childNodes属性,其中保存着一个NodeList对象,NodeList对象是一种类数组对象,用于保存一组有序的节点,可以通过位置来访问这些节点。访问其中的节点有两种方式:通过方括号[ ],也可以使用item()方法。
将NodeList对象转化为数组:
Array.prototype.slice.call(arguments)能将具有length属性的对象转成数组
//将NodeList对象转换为数组
function convertToArray (nodes) {
var array = null;
try {
array = Array.prototype.slice.call(nodes,0);//针对于非IE浏览器
} catch (ex) {
array = new Array();
for (var i = 0;i < nodes.length;i++) {
array.push(nodes[i]);
}
}
return array;
}parentNode:每个节点都有,该属性指向文档书中的父节点。包含在childLists列表中的所有节点都具有相同的父节点。
previousSibling:访问前一个节点
nextSibling:访问后一个节点
(2)操作节点
1)appendChild():用于向childNodes列表的末尾添加一个节点;
2)insertBefore(要插入的节点,作为参照的节点):把节点放在childNodes列表中的某个特定位置上;
3)replaceChild(要插入的节点,要替换的节点):返回要替换的节点,并将其从文档树种移除,同时由要插入的节点占据其位置;
4)removeChild(要移除的节点):移除某个节点,并将其返回。
以上方法必须先取得父节点(使用parentNode属性)
5)cloneNode():参数为true则深复制,复制节点及整个子节点树;参数为false则浅复制,只复制节点
6)normalize():处理文档书中的文本节点,如果有空文本节点,删除它;如果有相邻的文本节点,将它们合为一个文本节点
2、Document类型
nodeType = 9
(1)文档的子节点
Document节点的子节点可以是DocumentType、Element、ProcessingInstruction或comment。
1)documentElement属性:始终指向html元素
2)body属性:直接指向body元素
3)doctype属性:指向DOCTYPE,该属性用处很有限
(2)文档信息
1)title:包含着title元素中的文本
2)URL属性:包含页面完整的URL
3)domain属性:包含页面的域名
4)referrer属性:保存着链接到当前页面的那个页面的URL。
以上信息都存在于请求的HTTP头部
(3)查找元素
(1)getElementById():按照id查找
(2)getElementsByTagName():按照标签名查找,返回包含0或者多个元素的NodeList,可以使用方括号和item()来访问其中元素。也可以使用namedItem(),通过元素的name特性取得集合中的项。
(3)getElementsByName():返回带有给定name特性的所有元素
(4)一致性检测
检测浏览器实现了DOM的哪些部分:
document.inplementation.hasFeature(要检测的DOM功能,版本号)
3、Element类型
nodeTyle=1
要访问元素的标签名,可以使用nodeName属性,也可以使用tagName属性
(1)取得特性
getAttribute():取得特性值
setAttribute(要设置的特性名,值):设置特性值
removeAttribute(要删除的特性名):删除特性
(2)创建元素
document.createElement(“div”);
(3)HTML元素
每个HTML元素中都存在下列标准特性:
id:元素在文档中的唯一标识
className:对应元素的class
title:有关元素的附加信息说明
lang:元素内容的语言代码,很少使用
dir:语言的方向 ltr(left-to-right),rtl(right-to-left)
3、Text类型
nodeTyle=3
可以通过nodeValue属性或者data属性访问Text节点中包含的文本。
(1)createTextNode(要插入节点中的文本):创建文本节点
(2)splitText(位置):按照指定位置分隔nodeValue的值
4、DocumentFragment类型
nodeTyle=11
在文档中没有对应的标记,但是可以将它作为一个仓库,在里面保存将来可能会添加到文档中的节点。
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8' />
<title>DOM的学习</title>
</head>
<body>
<div id="div"> Hello DOM </div>
<ul id="my-list"></ul>
<script type="text/javascript"> divNode = document.getElementById("div"); if(divNode.nodeType == 1){ alert("Node is an element.") console.log(divNode.nodeValue); } //文档片段,可以用作一个仓库,用来存放将来可能会添加到文档中的节点,这样将li标签放在片段中,可以避免浏览器反复渲染。 var fragment = document.createDocumentFragment(); var ul = document.getElementById("my-list"); var li = null; for (var i = 0; i < 3; i++) { li = document.createElement("li"); li.appendChild(document.createTextNode("Item" + (i+1))); fragment.appendChild(li); } ul.appendChild(fragment); </script>
</body>
</html>
5、DOM操作技术
(1)动态脚本
//加载外部script代码
function loadScript (url) {
var script = document.createElement("script");
script.type = "text/javascript";
script.src = url;
document.appendChild(script);
}(2)动态样式
//动态加载外部样式表
function loadStyle (url) {
var link = document.createElement("link");
link.rel = "stylesheet";
link.type = "text/css";
link.href = url;
var head = document.getElementsByTagName("head")[0]; head.appendChild(link); }DOM操作往往是JavaScript程序中开销最大的部分,因此,要尽量减少DOM操作
二、DOM扩展
1、选择符扩展
(1)querySelector():接收一个CSS选择符,返回与该模式匹配的第一个元素,如果没有找到,则返回null
(2)querySelectorAll():接收一个CSS选择符,但返回的是所有匹配的元素,返回的是一个NodeList实例.
(3)matchesSelector():接收一个参数,即CSS选择符,如果调用元素与之匹配则返回true,否则返回false
//matchesSelector()方法
function matchesSelector (element,selector) {
if (element.matchesSelector) {
return element.matchesSelector(selector);
} else if (element.msMatchesSelector) {
return element.msMatchesSelector(selector);
} else if (element.mozMatchesSelector) {
return element.mozMatchesSelector(selector);
} else if (element.webkitMatchesSelector) {
return element.webkitMatchesSelector(selector);
} else {
throw new Error ("Not supported");
}
}2、HTML5扩展
(1)getElementsByClassName()
参数为包含一或多个类名的字符串,返回带有给定类型的NodeList
(2)classList属性
//删除element元素的className类
function removeClass (element,className) {
//取得类名字符串并拆分成数组
var classNames = element.className.split(/\s+/);
//找到要删除的类名
var len = classNames.length;
for (var i = 0 ; i < len; i ++) {
if (classNames[i] == className) {
break;
}
}
classNames.splice(i,1);
element.className = classNames.join(" ");
}HTML5新增了一种操作类名的方式,可以让操作比上述代码更简单,那就是HTML5为所有元素添加了classList属性。其定义了如下方法:
add(value):将给定的字符串添加到列表中
contains(value):表示列表中是否存在给定的值,如果存在返回true
remove(value):从列表中删除给定的字符串
toggle(value):列表中有就删除,没有就添加
var div = document.querySelector(".strong");
removeClass(div,"red");
div.classList.remove("big");
div.classList.add("red");
div.classList.toggle("strong");支持classList的浏览器有Firefox 3.6+ Chrome
(3)焦点管理
HTML5也添加了辅助管理DOM焦点的功能
document.activeElement属性,始终会引用DOM中当前获得了焦点的元素。
document.hasFocus( ):用于确定文档是否获得了焦点
(4)其他扩展
1)document.readyState属性:有两个可能的取值,loading-正在加载的文档;complete-已经加载完的文档。
使用document.readyState属性的最恰当的方式,就是通过它来实现一个指示文档已经加载完成的指示器
2)document.compatMode属性:告诉开发人员浏览器采用哪种渲染模式。
**在标准模式下,document.compatMode=CSS1Compat;
在混杂模式下,document.compatMode=BackCompat**
(5)插入标记
innerHTML 属性
div.innerHTML = "Hello vicky"插入script元素
div.innerHTML= "<input type=\"hidden\"><script defer> alert('hi');<\/script>"window.toStaticHTML( ):返回经过无害处理后的版本,从源HTML中删除所有脚本节点和时间处理程序属性
innerText属性
//取得元素文本
function getInnerText (element) {
return (typeof element.textContent == "string") ? element.textContent : element.innerText;
}
//设置元素文本
function setInnerText (element,text) {
if (typeof element.textContent == "string") {
element.textContent = text;
} else {
element.innerText = text;
}
}
3、专有扩展
contains():判断某个 节点是不是另一个节点的后代。
innerText属性:插入文本
三、DOM2和DOM3
1、DOM变化
增加了document.defaultView属性,其中保存着一个指针,指向拥有给定文档的窗口,除IE外,其他浏览器都支持这个属性。IE中有个等价的属性名叫parentWindow。
确定文档的归属窗口
var parentWindow = document.defaultView || document.parentWindow;Node类型变化
isSuppported( ):用于确定当前结点具有什么能力。
document.body.isSupported("HTML","2.0");isSameNode( ):两个节点引用同一个对象
isEqualNode( ):两个节点具有相等的属性
2、样式
(1)访问元素的样式(针对于行内样式)
任何支持style特性的HTML元素在JavaScript中都有一个对应的style属性。(对于使用短划线表示的CSS属性,必须要转化为驼峰样式)
DOM样式属性和方法
cssText:能够通过它方位到style特性中的CSS代码
getPropertyValue(propertyName):返回给定属性的字符串值
length:应用给元素的CSS属性的数量
removeProperty():移出某个CSS属性
(2)计算的样式
DOM2级样式为document.defaultView增加了getComputedStyle()方法,这个方法接受两个参数:要取得计算样式的元素和一个伪元素字符串(没有就写null)。IE不支持这个方法,但是为具有style属性的元素提供了currentStyle属性。
//获取CSS样式
function getCSS (element,key) {
var computedStyle = element.currentStyle ? element.currentStyle : document.defaultView.getComputedStyle(element,null);
return computedStyle[key];
}
3、元素的大小
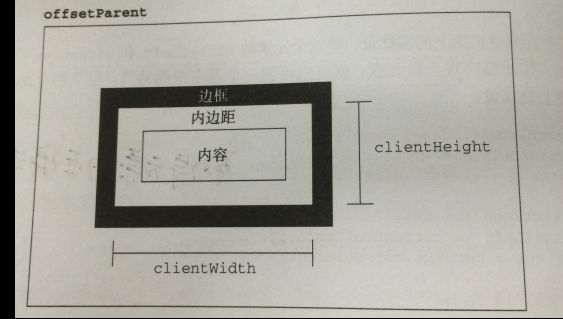
(1)偏移量
offsetHeight,offsetWidth,offsetLeft,offsetTop.
(2)客户区大小
clientWidth,clientHeight.
//取得元素在页面中的位置,返回左偏移量和上偏移量
function getElementLocation (element) {
var loc = {
left:0,
top:0
};
var actualLeft = element.offsetLeft;
var actualTop = element.offsetTop;
var current = element.offsetParent;
while(current !== null) {
actualLeft += current.offsetLeft;
actualTop += current.offsetTop;
current = current.offsetParent;
}
loc.left = actualLeft;
loc.top = actualTop;
return loc;
}4、遍历
NodeIterator 和 TreeWalker,都是基于起点对DOM结构进行深度优先遍历。
(1)NodeIterator
document.createNodeIterator( ),接受四个参数:
root:想要作为搜索起点的书中的节点
whatToShow:表示要访问哪些节点的数字代码
filter:是一个NodeFilter对象,或者一个表示应该接受还是拒绝某种特定节点的函数。
entityReferenceExpansion:布尔值,表示是否要扩展实体应用,HTML中一般是false。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>style样式</title>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<div id="box" style="border: 10px solid green">vicky</div>
<div id="div1">
<p><b>Hello</b> world!</p>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</div>
<script type="text/javascript" src="../Code/commonFunc.js"></script>
<script type="text/javascript"> var box = document.getElementsByTagName("div")[0]; // var computedStyle = document.defaultView.getComputedStyle(box,null); // console.log(computedStyle.width); var width = getCSS(box,"width"); console.log(width); var div = document.getElementById("div1"); var filter = function (node) { return node.tagName.toLowerCase() == "li" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; } var iterator = document.createNodeIterator(div,NodeFilter.SHOW_ELEMENT,filter,false); var node = iterator.nextNode(); while (node != null) { alert(node.tagName); node = iterator.nextNode(); } </script>
</body>
</html>NodeIterator类型的两个主要方法:
nextNode()和previousNode()
(2)TreeWalker
能够在DOM结构中沿任何方向移动
document.createTreeWalker( ),接受四个参数,与NodeIterator的参数一样。
parentNode():遍历到当前节点的父节点
firstChild():遍历到当前节点的第一个子节点
lastChild():遍历到当前节点的最后一个子节点
nextSibling():遍历到当前节点的下一个同辈节点
previousSibling():遍历到当前节点的前一个同辈节点