计算机网络作业合辑
1.Drawspace-time diagram for the previous HTTP request scenario assuming persistentconnections and pipelining
为之前持久性、流水线型的HTTP请求画时空图。


2. Impact ofusing local web cache
一个对象大小为100K bits, 每秒发送15个对象,那么每秒发送1.5M的数据。
有40%由缓存器接收,60%由接入链路接收,接收链路的使用速率为1.5M*60% = 0.9M
使用率为0.9/1.54 = 0.58.
总的延迟为 0.6*(2.0+~msecs) + 0.4*~msecs = 1.2sec
3.Q: what relationship between seq # size and window size to avoid problem in (b)?
为了避免图b所示的问题,序列号大小和窗口大小应该满足什么关系?

问题在于,接收方不知道对方是因为(应答丢失而)没有收到应答且超时而重传某个序列号,而是下几个窗口发送过程中因为丢失又正好轮到了同一个序列号。
在后面的情况中,接收方会把重复的分组当作新的分组,这样就出现了错误。
在这个例子中,我们认为是窗口太小,或者说序列号太大导致不能分辨新旧帧。我们假设两者窗口大小不变,而尽可能增大序列号(先认为无穷大)如果出现了ACK全部丢失的极端情况,重传时发送编号0,而此时窗口将会滑动到 3 4 5的位置,接收方得到0后,并不会认为这是新的分组,而导致重复接收。我们必须保证这个窗口不会出现0,所以至少需要序列空间大小为6(3位)
#seq size >= window size*2 (如果发送方和接收方windowsize相等的话,最终接收窗口终止的位置就是两倍window size,在ACK全部丢失情况下,要保证不产生歧义,序列号必须在终止位置时保证不回到新的序列),广义上,如果发送方和接收方windowsize不相等,那么size1 + size2 <=seq size
4.TCP中,为什么三次收到相同序列就认为丢包
5.两次握手会出现怎样的问题?
①一方发送请求,一方发送应答,如果应答延迟,客户端将重发请求,而服务器已经建立连接,出现错误。
②一方发送请求,一方发送应答,然后客户端不再有反应,而服务端认为连接建立,一直等待。
③一方发送请求而延迟,进而重新发送请求,等到连接关闭后,第一次的失效请求达到服务器,建立了第二次不需要存在的连接。
6.吞吐量相关计算
已知1500字节的段,100ms的rtt,需要10Gbps的吞吐量。
(10Gbps = 10^4Mbps = 10^10 bps 1500byte = 12 000 bit,100ms = 0.1s)
单位时间内流通的段数为(10^10bit/s)/(1.2*10^4bit * 0.1s)= 83 333
已知平均吞吐量计算公式:
TCP throughput = 1.22*MSS/(RTT*sqrt(L));
计算丢包率:
L = (1.22*MSS/(RTT*throughtput))^2 =(1.22*12 000/0.1*10^10)^2 = 2.143*10^-10
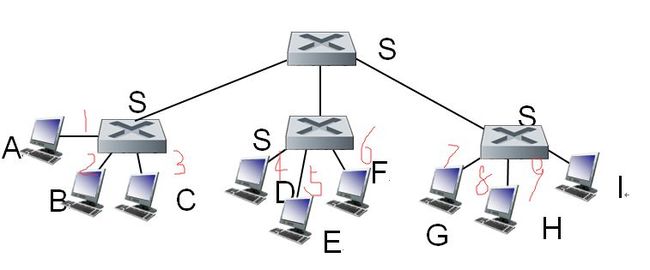
1.交换表为空,S1泛洪,把数据交给S4。
2.S4泛洪,数据交给S3
3.S3泛洪,数据交给I
4.数据通过交换表找到传输链路,从L到C回应