GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断增加component个数,可以任意地逼近任何连续的概率分布,所以我们认为任何样本分布都可以用混合模型来建模。因为高斯函数具有一些很实用的性质,所以高斯混合模型被广泛地使用。
GMM与kmeans类似,也是属于clustering,不同的是,kmeans是把每个样本点聚到其中一个cluster,而GMM是给出这些样本点到每个cluster的概率,每个component就是一个聚类中心。
GMM(Gaussian Mixture Model)高斯混合模型,由K个不同的Gaussian线性组合而成,每个Gaussian是混合模型的一个component,GMM的概率密度函数如下:
根据上式,从GMM中生成一个样本点x分两步:
1,从K个component中随机的选择一个
2,从该component中选择一个点
参数说明:N个样本点,K个component, μk,∑k 是第k个component的均值和协方差矩阵,是模型参数,是需要估计的。 πk 是mixing coefficient,表示第k个component被选中的概率, πk=1N∑Nn=1znk ,也是模型参数,需要估计。N是高斯(正态)分布。
对一个样本集建立高斯混合模型的过程,就是根据已知样本集X反推高斯混合模型的参数( μ,∑,π ),这是一个参数估计问题。首先想到用最大似然的方法求解,也就是,要确定参数 π,μ,∑ 使得它所确定的概率分布生成这些样本点的概率最大,这个概率也就是似然函数,如下:
而一般对于单个样本点其概率较小,多个相乘后更小,容易造成浮点数下溢,所以一般是对似然函数求log,变成加和形式:
这个叫做log似然函数,目标是要最大化它。用log似然函数对参数分别求偏导,令偏导等于0,可求解得参数。
然而,GMM的log似然函数是如下形式:
可以看到对数中有求和,直接求导求解将导致一系列复杂的运算,故考虑使用EM算法。(具体思路见上一篇: EM算法学习笔记)
考虑GMM生成一个样本点的过程,这里对每个 xi 引入隐变量z,z是一个K维向量,如果生成 xi 时选择了第k个component,则 zk=1 ,其他元素都为0, ∑Kk=1zk=1 .
假设z是已知的,则样本集变成了{X,Z},要求解的似然函数变成了:
log似然函数为:
可以看到,这次ln直接对Gaussian作用,求和在ln外面,所以可以直接求最大似然解了。
1,初始化一组模型参数 π,μ,∑
2,E-step
然而,事实上z是不知道的,我们只是假设z已知。而z的值是通过后验概率观测,所以这里考虑用z值的期望在上述似然函数中代替z。
对于一个样本点 x :
后验概率(固定 μ,∑,π ):
因为{ zn }之间是相互独立的。
计算z期望 γ(znk) (z向量只有一个值取1,其余为0):
将z值用期望代替,则待求解的log似然函数(*)式变为:
3,M-step
现在可以最大化似然函数求解参数了,首先对 μ 求偏导,令偏导等于0,可得:
Nk 是“the effective number of points assigned to cluster k”.
再对 ∑k 求偏导,令偏导等于0,可得:
接下来还需求解 π ,注意到 π 需满足 ∑Kk=1πk=1 ,所以这是一个带等式约束的最大值问题,使用拉格朗日乘数法。
构造拉格朗日函数:
对 π 求导,令导数为0:
两边同乘 πk 得:
两边对k求和:
可得: λ=−N
代入可得: πk=NkN.
4,检查是否收敛
重复E-step和M-step两步,直到收敛,即可求得一个局部最优解。
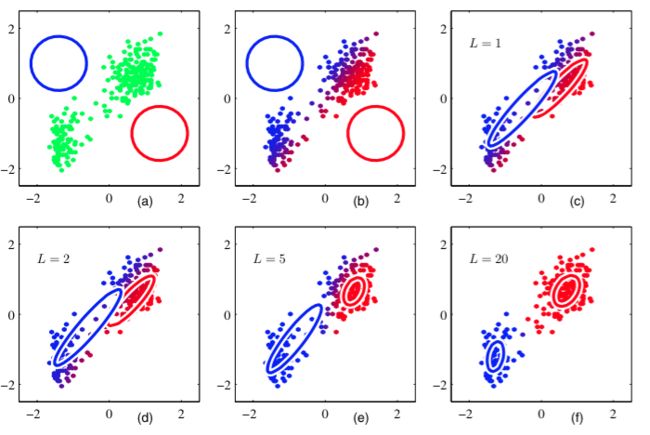
GMM的建模过程如下图(k=2,高斯分布是蓝色和红色圈):
主要参考资料:
《Pattern Recognization and Machine Learning》
帮助理解:
http://blog.pluskid.org/?p=39