MMU tlb
实验目的:启用MMU,映射SDRAM的地址空间,操作虚拟地址实现“点灯大法”,借此掌握MMU的使用。
实验环境及说明:恒颐S3C2410开发板H2410。H2410核心板扩展有64MB的K4S561632 SDRAM(4M*16bit*4BANK),地址范围是0x30000000~0x33FFFFFF。GPIO端口的地址范围是0x56000000~0X560000B0。
实验思路:开发板上电启动后,自动将NandFlash开始的4K数据复制到SRAM中,然后跳转到0地址开始执行,然后初始化存储控制器SDRAM,把2K后的代码从SRAM中复制到SDRAM中(存放在0x30004000,前16KB用来存放页表)、设置页表、启动MMU实现虚拟地址映射GPIO寄存器和SDRAM,最后跳转到SDRAM中(地址0xB0004000)运行。重新设置栈指针,跳到点灯代码的入口点实现点灯操作。
知识掌握:MMU地址转换、内存访问权限检查、TLB及Cache的使用
一、MMU地址转换:
1.首先弄清除为什么要使用MMU纳?MMU即内存管理单元,直白一点的讲,就像食堂的餐具,所有的学生一起吃饭时不够用,但食堂又不想再出资购买新的餐具(原因很明显:一方面要成本,另一方面又占地方。这就像增加内存一样),那么有没有解决办法?根据以往经验得知不可能全学校的学习一起都到食堂吃饭,于是食堂就找几个人负责餐具的管理(相当于MMU),他们一方面发放餐具,保证来的同学有餐具可用,另一方面又回收用完的餐具(这就相当于虚拟地址到物理地址之间建立了一个映射一样,内存还是那么多,但从任意单个程序角度都好像用不完一样)。当然如果有同学一个人拿好几套餐具肯定不允许的(这就相当于内存的权限检查)。MMU在地址转换过程中涉及到三种地址:(VA---Virtual Address,虚拟地址)---这个就相当于餐具存放的地方(大家都可以领到餐具)。CPU核心看到和用到的只是虚拟地址VA,至于VA如果去对应物理地址PA,CPU核心不理会,大家也不会去关心总共有多少餐具吧;(MVA---Modified Virtual Address,变换后的虚拟地址)---这个相当于放假的时候,人很少,只发餐具好了,用过的就不先回收了,节省人员了。Caches和MMU看不到VA,他们利用MVA转换得到PA,放假了回收餐具的人也不需要一直寻找用完的餐具;(PA---Physical Address,物理地址)---实际的餐具量,就那些。实际设备看不到VA、MVA,读写它们使用的是物理地址PA,同学们就餐一般会领到餐具。
2.虚拟地址到物理地址的转换过程。ARM使用页表来进行转换,S3C2410最多会用到两级页表,以段(Section,1M)的方式进行转换时只用到一级页表,以页(Page)的方式进行转换时用到两级页表。页的大小有3种:大页(64KB)、小页(4KB)和极小页(1KB)。本文只是以段地址转换过程为例来讲解一下,页的转换大同小异。
★首先有个页表基址寄存器(位置为协处理器CP15的寄存器C2),它里面写入的就是一级页表的地址,通过读取它就可以找到一级页表存放的起始位置。一级页表的地址是16K对齐(所以[13:0]为0,使用[31:14]存储页表基址)。一级页表使用4096个描述符来表示4GB空间,所以每个描述符对应1MB的虚拟地址,存储它对应的1MB物理空间的起始地址,或者存储下一级页表的地址。使用MVA[31:20]来索引一级页表(31-20一共12位,2^12=4096,所以是4096个描述符),得到一个描述符,每个描述符占4个字节。
★描述符最后两位为0B10时,即是段的方式映射。[31:20]为段基址,此描述符低20位填充0后就是一块1MB物理地址空间的起始地址。MVA[19:0]用来在这1MB空间中寻址。描述符的位[31:20]和MVA[19:0]构成了这个虚拟地址MVA对应的物理地址。以段的方式进行映射时,虚拟地址MVA到物理地址PA的转换过程如下:①页表基址寄存器位[31:14]和MVA[31:20]组成一个低两位为0的32位地址,MMU利用这个地址找到段描述符;②取出段描述符的位[31:20](段基址),它和MVA[19:0]组成一个32位的物理地址(这就是MVA对应的PA)。
二、内存的访问权限检查
内存的访问权限检查决定一块内存是否允许读/写。这由CP15寄存器C3(域访问控制)、描述符的域(Domain)、CP15寄存器C1的R/S/A位和描述符的AP位共同决定。“域”决定是否对某块内存进行权限检查,"AP"决定如何对某块内容进行权限检查。S3C2440有16个域,CP15寄存器C3中每两位对应一个域(一共32位),用来表示这个域是否进行权限检查。
每两位数据的含义:00---无访问权限(任何访问都将导致"Domain fault"异常);01---客户模式(使用段描述符、页描述符进行权限检查);10---保留(保留,目前相当于“无访问权限”);11---管理模式(不进行权限检查,允许任何访问)。"Domain"占用4位,用来表示内存属于0-15哪一个域。
三、TLB和Cache
首先说两者都是利用程序访问的局部性原理,通过设置高速、小容量的存储器来提高性能。
1.(TLB---Translation Lookaside Buffers,转译查找缓存):由于从MVA到PA的转换需要访问多次内存,大大降低了CPU的性能,故提出TLB办法改进。当CPU发出一个虚拟地址时,MMU首先访问TLB。如果TLB中含有能转换这个虚拟地址的描述符,则直接利用此描述符进行地址转换和权限检查,否则MMU访问页表找到描述符后再进行地址转换和权限检查,并将这个描述符填入TLB中,下次再使用这个虚拟地址时就直接使用TLB用的描述符。使用TLB需要保证TLB中的内容与页表一致,在启动MMU之前,页表中的内容发生变化后,尤其要注意。一般的做法是在启动MMU之前使整个TLB无效,改变页表时,使所涉及的虚拟地址对应的TLB中条目无效。
2.(Cache,高速缓存):为提高程序的运行速度,在主存和CPU通用寄存器之间设置一个高速的、容量相对较小的存储器,把正在执行的指令地址附近的一部分指令或数据从主存调入这个存储器,供CPU在一段时间内使用。
★写数据的两种方式:①(Write Through,写穿式)---任一CPU发出写信号送到Cache的同时,也写入主存,保证主存的数据同步更新。优点是操作简单,但由于主存速度慢,降低了系统的写速度并占用了总线的时间。②(Write Back,回写式)---数据一般只写到Cache,这样可能出现Cache中的数据得到更新而主存中的数据不变(数据陈旧)的情况。此时可在Cache中设一个标志地址及数据陈旧的信息,只有当Cache中的数据被换出或强制进行”清空“操作时,才将原更新的数据写入主存响应的单元中,保证了Cache和主存中数据一致。
★Cache有以下两个操作:①(Clean,清空)---把Cache或Write buffer中已经脏的(修改过,但未写入主存)数据写入主存。②(Invalidate,使无效)---使之不能再使用,并不将脏的数据写入主存。
★S2C2440内置了(ICaches,指令Cache)、(DCaches,数据Cache)和(Write buffer,写缓存),操作时需要用到描述符中的C位(Ctt)和B位(Btt)。①(ICaches,指令Cache)---系统刚上电或复位时,ICaches中的内容是无效的,并且ICaches功能关闭。往Icr位(CP15协处理器中寄存器1的第12位)写1可以启动ICaches,写0停止ICaches。ICaches一般在MMU开启后使用,此时描述符的C位用来表示一段内存是否可以被Cache。若Ctt=1,允许Cache,否则不允许。如果MMU没有开启,ICaches也可以被使用,此时CPU读取指令时所涉及的内存都被当做允许Cache。ICaches关闭时,CPU每次取指都要读取主存,性能低,所以通常尽早启动ICaches。ICaches开启后,CPU每次取指时都会先在ICaches中查看是否能找到所用指令,而不管Ctt是0还是1。如果找到成为Cache命中,找不到称为Cache丢失,ICaches被开启后,CPU的取指有如下三种情况:Cache命中且Ctt为1时,从ICaches中取指,返回CPU;Cache丢失且Ctt为1时,CPU从主存中取指,并且把指令缓存到Cache中;Ctt为0时,CPU从主存中取指。②(DCaches,数据Cache)---与ICaches相似,系统刚上电或复位时,DCaches中的内容无效,并且DCaches功能关闭,Write buffer中的内容也是被废弃不用的。往Ccr位(CP15协处理器 中寄存器1的第二位)写1启动DCaches,写0停止DCaches。Write buffer和DCaches紧密结合,额米有专门的控制来开启和停止它。与ICaches不同,DCaches功能必须在MMU开启之后才能被使用。DCaches被关闭时,CPU每次都去内存取数据。DCaches被开启后,CPU每次读写数据时都会先在DCaches中查看是否能找到所要的数据,不管Ctt是0还是1,找到了称为Cache命中,找不到称为Cache丢失。
★使用Cache时需要保证Cache、Write buffer的内容和主存内容一致,保证下面两个原则:①清空DCaches,使主存数据得到更新。②使无效ICaches,使CPU取指时重新读取主存。
在实际编写程序时,要注意如下几点:①开启MMU前,使无效ICaches,DCaches和Write buffer。②关闭MMU前,清空ICaches、DCaches,即将“脏”数据写到主存上。③如果代码有变,使无效ICaches,这样CPU取指时会从新读取主存。④使用DMA操作可以被Cache的内存时:将内存的数据发送出去时,要清空Cache;将内存的数据读入时,要使无效Cache。⑤改变页表中地址映射关系时也要慎重考虑。⑥开启ICaches或DCaches时,要考虑ICaches或DCaches中的内容是否与主存保持一致。⑦对于I/O地址空间,不使用Cache和Write buffer。
四、MMU、TLB及Cache的控制指令
S3C2410除了ARM920T的CPU核心外,还有若干个协处理器,用来帮助主CPU完成一些特殊功能,对MMU、TLB及Cache等的操作就涉及到协处理器。格式如下:
<MCR|MRC>{条件} 协处理器编码,协处理器操作码1,目的寄存器,源寄存器1,源寄存器2,协处理器操作码2
<MCR|MRC> {cond} p#,<expression1>,Rd,cn,cm{,<expression2>}
MRC //从协处理器获得数据,传给ARM920T CPU核心寄存器
MCR //数据从ARM920T CPU核心寄存器传给协处理器
{cond} //执行条件,省略时表示无条件执行
p# //协处理器序号
<expression1> //一个常数
Rd //ARM920T CPU核心的寄存器
cn和cm //协处理器中的寄存器
<expression2> //一个常数
其中,<expression1>、cn、cm、<expression2>仅供协处理器使用,它们的作用如何取决于具体的协处理器。
示例代码解析:
开启MMU,并将虚拟地址0xA0000000~0xA0100000映射到物理地址0x56000000~0x56100000(GPFCON物理地址为0x56000050,GPFDAT物理地址为0x56000054);将虚拟地址0xB0000000~0xB3FFFFFF映射到物理地址0x30000000~0x33FFFFFF。本示例以段的方式进行地址映射,只使用一级页表,通过上面内容可知一级页表使用4096个描述符来表示4G空间(每个描述符对应1MB),每个描述符占4字节,所以一级页表占16KB。使用SDRAM的开始16KB存放一级页表,所以剩下的内存开始地址就为0x30004000,这个地址最终会对应虚拟地址0xB0004000(所以代码运行地址为0xB0004000)。
★程序执行主要流程的示例代码。
.text
.global _start
_start:
bl disable_watch_dog @ 关闭WATCHDOG,否则CPU会不断重启
bl mem_control_setup @ 设置存储控制器以使用SDRAM
ldr sp, =4096 @ 设置栈指针,以下是C函数调用前需要设好栈
bl copy_2th_to_sdram @ 将第二部分代码复制到SDRAM
bl create_page_table @ 设置页表
bl mmu_init @ 启动MMU,启动以后下面代码都用虚拟地址
ldr sp, =0xB4000000 @ 重设栈指针,指向SDRAM顶端(使用虚拟地址)
ldr pc, =0xB0004000 @ 跳到SDRAM中继续执行第二部分代码
halt_loop:
b halt_loop
★设置页表。
void create_page_table(void)
{
/*
* 用于段描述符的一些宏定义:[31:20]段基址,[11:10]AP,[8:5]Domain,[3]C,[2]B,[1:0]0b10为段描述符
*/
#define MMU_FULL_ACCESS (3 << 10) /* 访问权限AP */
#define MMU_DOMAIN (0 << 5) /* 属于哪个域 Domain*/
#define MMU_SPECIAL (1 << 4) /* 必须是1 */
#define MMU_CACHEABLE (1 << 3) /* cacheable C位*/
#define MMU_BUFFERABLE (1 << 2) /* bufferable B位*/
#define MMU_SECTION (2) /* 表示这是段描述符 */
#define MMU_SECDESC (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_SECTION)
#define MMU_SECDESC_WB (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_CACHEABLE | MMU_BUFFERABLE | MMU_SECTION)
#define MMU_SECTION_SIZE 0x00100000 /*每个段描述符对应1MB大小空间*/
unsigned long virtuladdr, physicaladdr;
unsigned long *mmu_tlb_base = (unsigned long *)0x30000000; /*SDRAM开始地址存放页表*/
/*
* Steppingstone的起始物理地址为0,第一部分程序的起始运行地址也是0, 为了在开启MMU后仍能运行第一部分的程序, 将0~1M的虚拟地址映射到同样的物理地址
*/
virtuladdr = 0;
physicaladdr = 0;
/*虚拟地址[31:20]用于索引一级页表,找到它对应的描述符,对应于(virtualaddr>>20)。段描述符中[31:20]保存段的物理地址,对应(physicaladdr & 0xFFF00000)*/
*(mmu_tlb_base + (virtuladdr >> 20)) = (physicaladdr & 0xFFF00000) | MMU_SECDESC_WB;
/*
* 0x56000000是GPIO寄存器的起始物理地址,GPBCON和GPBDAT这两个寄存器的物理地址0x56000010、0x56000014, 为了在第二部分程序中能以地址0xA0000010、0xA0000014来操作GPBCON、GPBDAT,
* 把从0xA0000000开始的1M虚拟地址空间映射到从0x56000000开始的1M物理地址空间
*/
virtuladdr = 0xA0000000;
physicaladdr = 0x56000000;
*(mmu_tlb_base + (virtuladdr >> 20)) = (physicaladdr & 0xFFF00000) | MMU_SECDESC;
/*
* SDRAM的物理地址范围是0x30000000~0x33FFFFFF, 将虚拟地址0xB0000000~0xB3FFFFFF映射到物理地址0x30000000~0x33FFFFFF上, 总共64M,涉及64个段描述符
*/
virtuladdr = 0xB0000000;
physicaladdr = 0x30000000;
while (virtuladdr < 0xB4000000)
{
*(mmu_tlb_base + (virtuladdr >> 20)) = (physicaladdr & 0xFFF00000) | MMU_SECDESC_WB;
virtuladdr += MMU_SECTION_SIZE;
physicaladdr += MMU_SECTION_SIZE;
}
}
★ 启动MMU。
void mmu_init(void)
{
unsigned long ttb = 0x30000000;
__asm__(
"mov r0, #0\n"
"mcr p15, 0, r0, c7, c7, 0\n" /* 使无效ICaches和DCaches */
"mcr p15, 0, r0, c7, c10, 4\n" /* drain write buffer on v4 */
"mcr p15, 0, r0, c8, c7, 0\n" /* 使无效指令、数据TLB */
"mov r4, %0\n" /* r4 = 页表基址 */
"mcr p15, 0, r4, c2, c0, 0\n" /* 设置页表基址寄存器 */
"mvn r0, #0\n"
"mcr p15, 0, r0, c3, c0, 0\n" /* 域访问控制寄存器设为0xFFFFFFFF, 不进行权限检查*/
/*
* 对于控制寄存器,先读出其值,在这基础上修改感兴趣的位,然后再写入
*/
"mrc p15, 0, r0, c1, c0, 0\n" /* 读出控制寄存器的值 */
/* 控制寄存器的低16位含义为:.RVI ..RS B... .CAM
* R : 表示换出Cache中的条目时使用的算法,0 = Random replacement;1 = Round robin replacement
* V : 表示异常向量表所在的位置,0 = Low addresses = 0x00000000;1 = High addresses = 0xFFFF0000
* I : 0 = 关闭ICaches;1 = 开启ICaches
* R、S : 用来与页表中的描述符一起确定内存的访问权限
* B : 0 = CPU为小字节序;1 = CPU为大字节序
* C : 0 = 关闭DCaches;1 = 开启DCaches
* A : 0 = 数据访问时不进行地址对齐检查;1 = 数据访问时进行地址对齐检查
* M : 0 = 关闭MMU;1 = 开启MMU
*/
/*
* 先清除不需要的位,往下若需要则重新设置它们
*/
/* .RVI ..RS B... .CAM */
"bic r0, r0, #0x3000\n" /* ..11 .... .... .... 清除V、I位 */
"bic r0, r0, #0x0300\n" /* .... ..11 .... .... 清除R、S位 */
"bic r0, r0, #0x0087\n" /* .... .... 1... .111 清除B/C/A/M */
/*
* 设置需要的位
*/
"orr r0, r0, #0x0002\n" /* .... .... .... ..1. 开启对齐检查 */
"orr r0, r0, #0x0004\n" /* .... .... .... .1.. 开启DCaches */
"orr r0, r0, #0x1000\n" /* ...1 .... .... .... 开启ICaches */
"orr r0, r0, #0x0001\n" /* .... .... .... ...1 使能MMU */
"mcr p15, 0, r0, c1, c0, 0\n" /* 将修改的值写入控制寄存器 */
: /* 无输出 */
: "r" (ttb) );
}
1 页面

(b)页面大小为4KB(2的12次方)



一、MMU的介绍
MMU全称Memory Management Unit,中文称内存管理单元
主要有两个功能:
A.将虚拟地址转换成实际的物理地址
B.对物理内存设置访问权限
二、MMU的工作过程
在s3c2410中MMU是由协处理器(cp15)控制的,s3c2410/s3c2440最多会用到两级页表:以段(Section,1MB)的方式进行转换时只用到一级页表,以页(page)的方式进行转换时用到两级页表。页的大小有3种:大页(64KB),小页(4KB),极小页(1KB)。
明确一个概念:
条目也称为"描述符"(Descriptor),有:段描述符,大页描述符,小页描述符,极小页描述符----它们保存段、大页、小页或极小页的起始物理地址;粗页表描述符、细页表描述符---他们保存二级页表的物理地址
转换过程如下:
(1) 根据给定的虚拟地址找到一级页表中的条目
(2)如果此条目是段描述符,则返回物理地址,转换结束
(3)如果此条目是二级页表描述符,继续利用虚拟地址在二级页表中找到下一个条目;
(4)如果这第二个条目是叶描述符,则返回物理地址,转换结束;
(5)其他情况出错

注意:这里面所有的转换过程都是由MMU完成的
以段的方式映射实例说明:
例如:虚拟地址 0xa0004000
注意:当MMU打开以后,所有的地址都会被MMU拦截,然后将其转换,cpu是不管虚拟地址还是实际物理地址的。
转换如下:
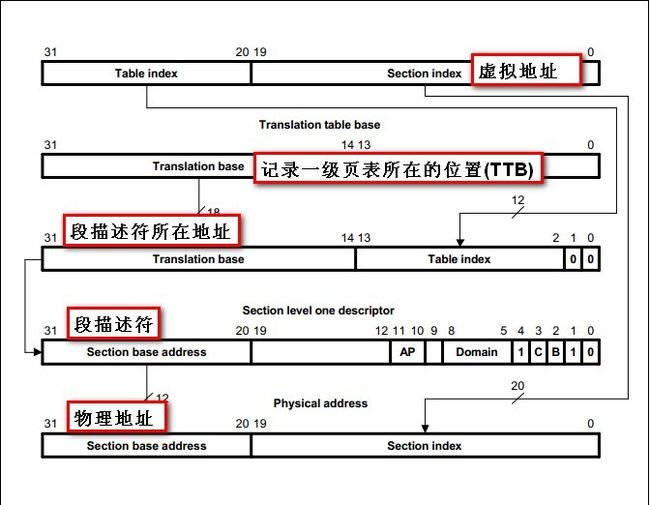
先来看看TTB
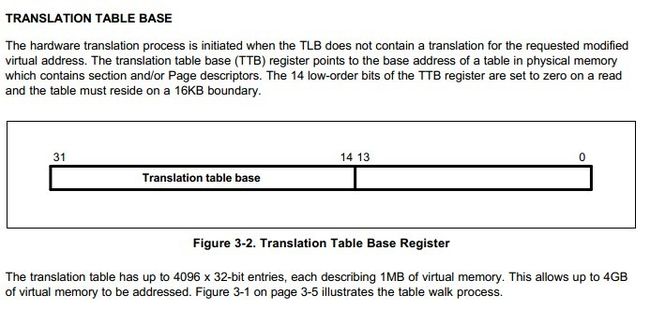
简单的来说,它保存了一级页表所存放的实际物理地址,要求16KB对齐,以段的方式映射,4GB的虚拟地址空间,需要段描述符4096个(每个段描述符映射1M空间),没个描述符占用4byte,所以一段的方式映射一级页表占用的空间为16KB。
在这里我们假设,我们的一级页表存放在物理地址:0x30000000.
第一步:
获得虚拟地址所对应的段描述符所在的地址
addr = TTB&0xffffc000 | ((viraddr >> 20) << 2 ) = 0x30000000 & 0xfffc000 | ((0xa0004000 >> 20) << 2)= 0x30000000 | (0xa00 << 2) = 0x30002800
第二步:
从0x30002800取出虚拟地址所对应的段描述符
段描述的构造我们到后面再来讲解,这里我们假设我们把0xa0004000映射到实际的物理地址0x30004000,则这里的[31:20]为0x300
第三步:
组合成实际的物理地址
![]()
phyaddr = 0x300 << 20 | (0xa0004000 & 0xfffff) = 0x30004000
三.实验
目标:以段的方式映射s3c2410的地址空间,一级页表存放在0x30000000
流程:
A.计算每个虚拟地址对应段描述符所在的地址(addr),方法如下:

B.构造段描述符

注意:Section base address 存放的是实际的物理地址的[31:20]
C.存放段描述符
(unsigned int *)addr = section descriptor
D.使能MMU
整个流程比较复杂的就是段描述符的构造,具体的流程大家可以直接看芯片手册,写的很详细
实例代码:
/*Nand 启动sdram的起始地址*/
#define SRAM_START_ADDR 0x00000000
/*内存空间地址*/
#define VMRAM_ADDR_START 0xa0000000
#define SDRAM_ADDR_END 0x34000000
/*IO空间地址*/
#define VMIO_ADDR_START 0xb0000000
#define PHIO_ADDR_START 0x56000000
#define PHIO_ADDR_END 0x56010000
/*用SDRAM起始地址开始的16KB,存放页表*/
#define PAGE_TABLE_BASE 0x30000000
/*MASK*/
#define PAGE_TABLE_BASE_MASK 0xffffc000
#define VIRADDR_MASK 0xfff00000
#define PHYADDR_MASK 0xfff00000
/*页表项内容*/
#define PAGE_TABLE_SECTION_AP (0x01 << 10)
#define APGE_TABLE_SECTION_DOMAIN (0x0 << 5)
#define PAGE_TABLE_SECTION_CACHE_WB (0x0 << 2)
#define PAGE_TABLE_SECTION_4BIT (1 << 4)
#define PAGE_TABLE_SECTION_TYPE (0x2)
/*段大小*/
#define SECTION_SIZE 0x100000
//根据虚拟地址和页表基地址确定页表项所在的物理地址
unsigned int get_pgtindex_addr(unsigned int viraddr,unsigned int pgtaddr)
{
unsigned int addr;
/*[31:14]页表基地地址
*[13: 2]虚拟地址>>20位得到的page index
*[1 : 0]总是为0,因为每一项占用4byte
*/
addr = (pgtaddr & PAGE_TABLE_BASE_MASK) | (((viraddr & VIRADDR_MASK) >> 20) << 2);
return addr;
}
//获取页表项
unsigned int get_page_entry(unsigned int phyaddr)
{
unsigned int entry_value;
/*[31:20]section base address
*[19:12]
*[11:10]AP
*[9]
*[8:5]Domain
*[4]:1
*[3]:C
*[2]:B
*[1:0]:Type
*/
entry_value = (phyaddr & PHYADDR_MASK) | PAGE_TABLE_SECTION_AP |\
PAGE_TABLE_SECTION_CACHE_WB | PAGE_TABLE_SECTION_4BIT|\
PAGE_TABLE_SECTION_TYPE;
return entry_value;
}
/*创建一级页表:段描述符*/
void create_page_table()
{
int i;
unsigned int pgt_index_addr;
unsigned int viraddr,phyaddr,pgtaddr;
/*我们代码的起始运行地址0x00000000在这里需要注意的是:当我们开启MMU后,cpu发出的地址都会被MMU拦截,要想程序正常运行,pc所用的的地址必须是虚拟地址。然而此时cpu执行下一条指令实际运行的地址是物理地址,但是MMU会将此物理地址当作虚拟虚拟地址处理。晕,乱套了。为了解决这个问题,我们通常的做法是,让开启MMU的附近地址指令的虚拟地址和物理地址空间做一个等价的映射。在这里我们将0x00000000开始的1M物理空间映射到0x00000000开始的虚拟地址空间。*/
phyaddr = SRAM_START_ADDR;
viraddr = phyaddr;
pgtaddr = PAGE_TABLE_BASE;
pgt_index_addr = get_pgtindex_addr(viraddr,pgtaddr);
*(volatile unsigned int *)pgt_index_addr = get_page_entry(phyaddr);
#if 1
/*映射64MSDRAM*/
for(phyaddr = SDRAM_ADDR_START,viraddr = VMRAM_ADDR_START;\
phyaddr < SDRAM_ADDR_END;phyaddr += SECTION_SIZE,\
viraddr += SECTION_SIZE)
{
pgtaddr = PAGE_TABLE_BASE;
pgt_index_addr = get_pgtindex_addr(viraddr,pgtaddr);
*(volatile unsigned int *)pgt_index_addr = get_page_entry(phyaddr);
}
#endif
/*映射IO地址空间*/
phyaddr = PHIO_ADDR_START;
viraddr = VMIO_ADDR_START;
pgtaddr = PAGE_TABLE_BASE;
pgt_index_addr = get_pgtindex_addr(viraddr,pgtaddr);
*(volatile unsigned int *)pgt_index_addr = get_page_entry(phyaddr);
return;
}
/*
Care must be taken if the translated address differs from the
untranslated address as several instructions following the
enabling of the MMU may have been prefetched with the MMU off
(using physical = virtual address - flat translation) and enabling
the MMU may be considered as a branch with delayed execution. A similar
situation occurs when the MMU is disabled. Consider the following code
sequence:
MRC p15, 0, R1, c1, C0, 0: Read control rejectio
ORR R1, #0x1
MCR p15,0,R1,C1, C0,0 ; Enable MMUS
Fetch Flat
Fetch Flat
Fetch Translated
*/
void init_mmu()
{
unsigned long mmu_table_base = PAGE_TABLE_BASE;
asm(
/*set Translation Table Base(TTB) register*/
"mrc p15,0,r0,c2,c0,0\n"
"mov r0,%0\n"
"mcr p15,0,r0,c2,c0,0\n"
/*set Domain Access Control register*/
"mrc p15,0,r0,c3,c0,0\n"
"mvn r0,#0\n"
"mcr p15,0,r0,c3,c0,0\n"
/*Enable MMU*/
"mrc p15,0,r0,c1,c0,0\n"
"orr r0, #0x1\n"
"mcr p15,0,r0,c1,c0,0\n"
"mov r0,r0\n"
"mov r0,r0\n"
"mov r0,r0\n"
:
:"r"(mmu_table_base)
:"r0"
);
return;
}
start.S
.text
.global _start
_start:
#define pWTCON 0x53000000
#define CLKDIVN 0x4c000014
#define MPLLCON 0x4c000004
#define MEMBASE 0x48000000
#define SRAM_2_ADDR 2048
#define SDRAM_2_ADDR 0x30004000
#define SRAM_SIZE 4096
start_code:
@set the cpu to SVC32 mode
mrs r0,cpsr
bic r0,r0,#0x1f
orr r0,r0,#0xd3
msr cpsr,r0
@打开指令cache
mrc p15,0,r0,c1,c0,0
@orr r0,r0,#0x1000
mcr p15,0,r0,c1,c0,0
@设置栈指针位置
ldr sp,=4096
@关看门狗
bl disable_watchdog
@初始化系统时钟
bl init_sys_clock
@初始化内存
bl init_sdram
@拷贝SRAM的代码到SDRAM
bl copy_to_sdram
@创建页表
bl create_page_table
@启动MMU
bl init_mmu
@运行led程序
ldr sp,=0xa3000000 @重设sp指针,mmu之后,@cpu操作的地址都是虚拟地址
ldr pc,_main
halt_loop:
b halt_loop
_main:
.word main
disable_watchdog:
@关看门狗,不然cpu会不断重启
ldr r0,=pWTCON
mov r1,#0
str r1,[r0]
mov pc,lr
init_sys_clock:
@目前为止,cpu工作在12MHZ频率下
@提升cpu工作频率FCLK:HCLK:PCLK=1:2:4
ldr r0,=CLKDIVN
mov r1,#3
str r1,[r0]
@ifHDIVN=1,must asynchronous buf mode
mrc p15,0,r0,c1,c0,0
orr r0,r0,#0xc0000000
mcr p15,0,r0,c1,c0,0
@设置MPLL,使cpu工作在202.80MHZ
ldr r0,=MPLLCON
ldr r1,=0x000a1031
str r1,[r0]
mov pc,lr
copy_to_sdram:
ldr r0,=SRAM_2_ADDR @第二阶段代码起始地址(2048)
ldr r1,=SDRAM_2_ADDR @第二阶段代码存放的物理地址(0x30004000)
1:
ldr r2,[r0],#4
str r2,[r1],#4
cmp r0,#SRAM_SIZE
bne 1b
mov pc,lr
init_sdram:
@初始化sdram
ldr r0,=MEMBASE @13个寄存器的首地址
adrl r1,SMRDATA @13个寄存器值存放的地址
mov r2,#52 @13 * 4 = 52
add r2,r2,r1
1:
ldr r3,[r1],#4
str r3,[r0],#4
cmp r1,r2
bne 1b
/*every thing is fine now*/
mov pc,lr
.ltorg @声明一个数据缓冲池的开始
SMRDATA:
.word 0x2201d110 @BWSCON 设置BANK3位宽16,使能nWait,使能UB/LB
.word 0x0700 @BANKCON0
.word 0x700 @BANKCON1
.word 0x700 @BANKCON2
.word 0x700 @BANKCON3
.word 0x700 @BANKCON4
.word 0x700 @BANKCON5
.word (3 << 15) + (1 << 0) @BANKCON6
.word 0x18001 @BANKCON7
.word (1 << 23) + (2 << 18) + (1256 << 0) @REFRESH
.word (1 << 7) + (1 << 0) @BANKSIZE
.word (3 << 4) @MRSRB6
.word (3 << 4) @MRSRB7
led.c
//#include "s3c2410.h"
/*虚拟地址*/
#define GPFCON (*(volatile unsigned long *) 0xb0000050)
#define GPFDAT (*(volatile unsigned long *) 0xb0000054)
//初始化
static inline void led_init()
{
//GPFCON -> [8:15]清零
GPFCON &= ~(0xff << 8);
//GPF4 GPF5 GPF6 GPF7设为输出模式
GPFCON |= 0x55 << 8;
//输出高低平,关闭四路LED灯
GPFDAT |= 0xf << 4;
return;
}
//关闭LED
static inline int led_off()
{
GPFDAT |= 0xf << 4;
return 0;
}
//延时函数
static inline int delay_time(int time)
{
int i,j;
//让两个for循环作为延时
for(i = 0;i < time;i ++)
for(j = 0;j < time;j ++);
return 0;
}
//流水灯
static inline int run_water_led(int count)
{
int i = 0;
while(count --)
{
led_off();
delay_time(500);
for(i = 4;i < 8;i ++)
{
GPFDAT &= ~(0x1 << i);
delay_time(500);
}
}
return 0;
}
int main()
{
led_init();
run_water_led(5);
led_off();
delay_time(5000);
return 0;
}
Makefile:
led.bin:start.S led.c
arm-none-linux-gnueabi-gcc -c start.S -o start.o
arm-none-linux-gnueabi-gcc -c mmu.c -o mmu.o
arm-none-linux-gnueabi-gcc -c led.c -o led.o
#arm-none-linux-gnueabi-ld -Ttext 0x00000000 start.o led.o -o led_elf
arm-none-linux-gnueabi-ld -Tmap.lds start.o mmu.o led.o -o led_elf
arm-none-linux-gnueabi-objcopy -O binary -S led_elf led.bin
cp led.bin /tftpboot
clean:
rm -rf *.o led_elf led.bin
连接脚本(map.lds)
OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm", "elf32-littlearm")
/*OUTPUT_FORMAT("elf32-arm", "elf32-arm", "elf32-arm")*/
OUTPUT_ARCH(arm)
ENTRY(_start)
SECTIONS
{
firtst 0x00000000:
{
start.o
mmu.o
}
second 0xa0004000:
AT(2048)
{
led.o
}
}