MySQL 优化综述专题
对于一个以数据为中心的应用,数据库的好坏直接影响到程序的性能,因此数据库性能至关重要。
一般来说,要保证数据库的效率,要做好以下四个方面的工作:
① 数据库设计
② sql语句优化
③数据库参数配置
④恰当的硬件资源和操作系统
这个顺序也表现了这四个工作对性能影响的大小
1. 数据库表设计要合理
如果表的设计都不合理,再优化都没什么用了
表设计要符合3NF3范式(规范的模式) , 当然有时我们需要适当的逆范式
SQL三范式深入理解博客文章
有时我们需要适当的逆范式,如下面2个例子:
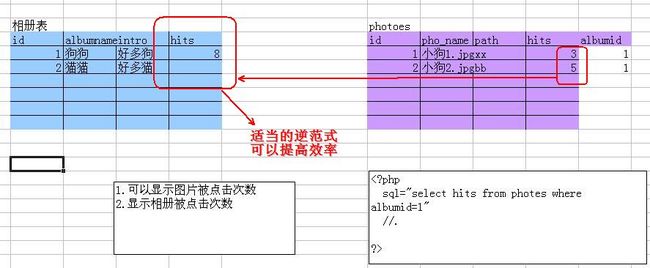

2. sql语句的优化
面试题 :sql语句有几类
ddl (数据定义语言) [create alter drop]
dml(数据操作语言)[insert delete upate ]
select
dtl(数据事务语句) [commit rollback savepoint]
dcl(数据控制语句) [grant revoke]
show status命令
该命令可以显示你的mysql数据库的当前状态.
我们主要关心的是 “com”开头的指令
show status like ‘Com%’ <=> show session status like ‘Com%’
//显示当前控制台的情况
show global status like ‘Com%’ ;
//显示数据库从启动到 查询的次数

为了做好一个项目
我们最好将数据库搞大来测试
搞一个海量表(mysql存储过程)
mysql用存储过程比较少,Oracle用的比较多
#创建表DEPT CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, dname VARCHAR(20) NOT NULL DEFAULT "", loc VARCHAR(13) NOT NULL DEFAULT "" ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; #创建表EMP雇员 CREATE TABLE emp (empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, ename VARCHAR(20) NOT NULL DEFAULT "", job VARCHAR(9) NOT NULL DEFAULT "", mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, hiredate DATE NOT NULL, sal DECIMAL(7,2) NOT NULL, comm DECIMAL(7,2) NOT NULL, deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 )ENGINE=MyISAM DEFAULT CHARSET=utf8 ; #工资级别表 CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MyISAM DEFAULT CHARSET=utf8; INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999); # 随机产生字符串 #定义一个新的命令结束符合 delimiter $$ #删除自定的函数 drop function rand_string $$ #这里我创建了一个函数. create function rand_string(n INT) returns varchar(255) begin declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i = i + 1; end while; return return_str; end $$ delimiter ; select rand_string(6); # 随机产生部门编号 delimiter $$ drop function rand_num $$ #这里我们又自定了一个函数 create function rand_num( ) returns int(5) begin declare i int default 0; set i = floor(10+rand()*500); return i; end $$ delimiter ; select rand_num(); #****************************************** #向emp表中插入记录(海量的数据) delimiter $$ drop procedure insert_emp $$ create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i + 1; insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num()); until i = max_num end repeat; commit; end $$ delimiter ; #调用刚刚写好的函数, 1800000条记录,从100001号开始 call insert_emp(100001,1800000); #************************************************************** # 向dept表中插入记录 delimiter $$ drop procedure insert_dept $$ create procedure insert_dept(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i + 1; insert into dept values ((start+i) ,rand_string(10),rand_string(8)); until i = max_num end repeat; commit; end $$ delimiter ; call insert_dept(100,10); #------------------------------------------------ #向salgrade 表插入数据 delimiter $$ drop procedure insert_salgrade $$ create procedure insert_salgrade(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; ALTER TABLE emp DISABLE KEYS; repeat set i = i + 1; insert into salgrade values ((start+i) ,(start+i),(start+i)); until i = max_num end repeat; commit; end $$ delimiter ; #测试不需要了 #call insert_salgrade(10000,1000000); #----------------------------------------------
目的,就是看看怎样处理,在海量表中,查询的速度很快!
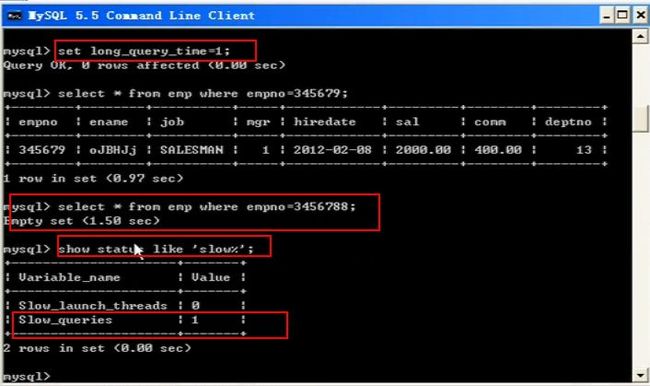
这里我们优化的重点是在 慢查询.
( mysql5.5.19在默认情况下是10 )
显示查看慢查询的默认时间为多长,用下面的命令
show variables like ‘long_query_time’
需求:
如何在一个项目中,找到慢查询的select , mysql数据库支持把慢查询语句,记录到日志中供程序员分析.
(但是注意,默认情况下不启动.)
实现步骤:
1. 要这样启动mysql
进入到 mysql安装目录
2. 启动 xx>bin\mysqld.exe –slow-query-log 这点注意
遇到慢查询,如何优化呢?
比如
select * from emp where empno=34678 ;
用了1.5秒,我现在优化.
快速体验:
在emp表的 empno建立索引.
alter table emp add primary key(empno);
//删除主键索引
alter table emp drop primary key
然后,再查速度会变快.
索引的原理是什么呢?
1,索引可以优化查询速度,但是是以牺牲删除、修改、添加为代价的。
2,索引信息是存储在 *.myi 文件中,以 牺牲存储空间为代价的。
介绍一款非常重要工具explain
这个分析工具可以对 sql语句进行分析,可以预测你的sql执行的效率.
基本用法是:
explain sql语句\G
//根据返回的信息,我们可知,该sql语句是否使用索引,从多少记录中取出,可以看到排序的方式.


在什么列上添加索引比较合适
① 在经常查询的列上加索引.
② 列的数据,内容就只有少数几个值,不太适合加索引.
③ 内容频繁变化,不合适加索引
索引的种类
① 主键索引 (把某列设为主键,则就是主键索引)
② 唯一索引(unique) (即该列具有唯一性,同时又是索引)
③ index (普通索引)
④ 全文索引(FULLTEXT)
中文用全文索引不太好使,因为中文的词语逻辑比较复杂
select * from article where content like ‘%李连杰%’;
hello, i am a boy
l 你好,我是一个男孩 =>中文sphinx
⑤ 复合索引(多列和在一起)
create index myind on 表名 (列1,列2);
如何创建索引
如果创建unique / 普通/fulltext 索引
1. create [unique|FULLTEXT] index 索引名 on 表名 (列名...)
2. alter table 表名 add index 索引名 (列名...)
//如果要添加主键索引
alter table 表名 add primary key (列...)
删除索引
1. drop index 索引名 on 表名
2. alter table 表名 drop index index_name;
3. alter table 表名 drop primary key
显示索引
showindex(es) from 表名
showkeys from 表名
desc表名
如何查询某表的索引
show indexes from 表名
使用索引的注意事项
查询要使用索引最重要的条件是查询条件中需要使用索引。
下列几种情况下有可能使用到索引:
1,对于创建的多列索引,只要查询条件使用了最左边的列,索引一般就会被使用。
2,对于使用like的查询,查询如果是 ‘%aaa’ 不会使用到索引 ‘aaa%’会使用到索引。
下列的表将不使用索引:
1,如果条件中有or,即使其中有条件带索引也不会使用。
2,对于多列索引,不是使用的第一部分,则不会使用索引。
3,like查询是以%开头
4,如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。
5,如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
如何检测你的索引是否有效

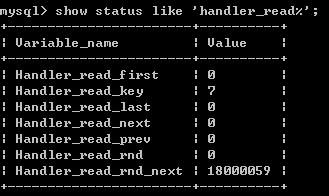
结论:Handler_read_key 越大越少
Handler_read_rnd_next 越小越好
- MyISAM 和 Innodb区别是什么
- MyISAM 不支持外键, Innodb支持
- MyISAM 不支持事务,不支持外键.
- 对数据信息的存储处理方式不同.(如果存储引擎是MyISAM的,则创建一张表,对于三个文件..,如果是Innodb则只有一张文件 *.frm,数据存放到ibdata1)
对于 MyISAM 数据库,需要定时清理
optimize table 表名
常见的sql优化手法
1. 使用order by null 禁用排序
比如 select *from dept group by ename order by null
2. 在精度要求高的应用中,建议使用定点数(decimal)来存储数值,以保证结果的准确性
1000000.32 万
create table sal(t1 float(10,2));
create table sal2(t1 decimal(10,2));
问?在php中 ,int 如果是一个有符号数,最大值. int- 4*8=32 2 31 -1



表的垂直分割




3. 数据的配置(缓存设大)

4. 适当硬件配置和操作系统
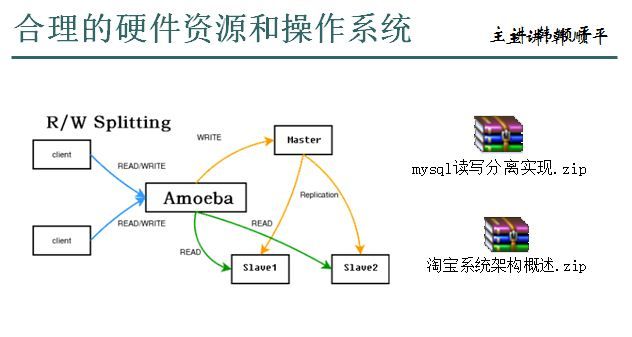
读写分离博客文章
小结:
- 数据库优化工作
- 数据库表设计
- SQL语句优化
- SQL语句优化-show参数
- SQL语句优化-定位慢查询
- SQL语句优化-explain分析问题
- 建立适当的索引
- 索引的原理说明
- 哪些列上适合添加索引
- 索引的类型
- 索引的使用
- 常用SQL优化
- 选择合适的存储引擎
- 选择合适的数据类型
- 对表进行水平划分
- 对表进行垂直划分
- 选择适当的字段类型,特别是主键
- 文件、图片等大文件用文件系统存储
- 数据库参数配置
- 合理的硬件资源和操作系统