linux awk使用简介
awk 是一种程序语言. 它具有一般程序语言常见的功能.
因awk语言具有某些特点, 如 : 使用直译器(Interpreter)不需先行编译; 变量无类型之分(Typeless), 可使用文字当数组的下标(Associative Array)...等特色. 因此, 使用awk撰写程序比起使用其它语言更简洁便利且节省时间. awk还具有一些内建功能, 使得awk擅于处理具数据行(Record), 字段(Field)型态的资料; 此外, awk内建有pipe的功能, 可将处理中的数据传送给外部的 Shell命令加以处理, 再将Shell命令处理后的数据传回awk程序, 这个特点也使得awk程序很容易使用系统资源.
由于awk具有上述特色, 在问题处理的过程中, 可轻易使用awk来撰写一些小工具; 这些小工具并非用来解决整个大问题,它们只扮演解决个别问题过程的某些角色, 可藉由Shell所提供的pipe将数据按需要传送给不同的小工具进行处理, 以解决整个大问题. 这种解题方式, 使得这些小工具可因不同需求而被重复组合及重用(reuse); 也可藉此方式来先行测试大程序原型的可行性与正确性, 将来若需要较高的执行速度时再用C语言来改写.这是awk最常被应用之处.若能常常如此处理问题, 读者可以以更高的角度来思考抽象的问题, 而不会被拘泥于细节的部份.
本手册为awk入门的学习指引, 其内容将先强调如何撰写awk程序,未列入进一步解题方式的应用实例, 这部分将留待UNIX进阶手册中再行讨论.
.命令行方式 awk [-F field-separator] 'commands' input-file(s) 其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。
awk程序中主要语法是 Pattern { Actions}, 故常见之awk 程序其型态如下 :
Pattern1 { Actions1 }
Pattern2 { Actions2 }
......
Pattern3 { Actions3 }
Pattern 是什么 ?
awk 可接受许多不同型态的 Pattern. 一般常使用 "关系表达式"(Relational expression) 来当成 Pattern.
例如:
x > 34 是一个Pattern, 判断变量 x 与 34 是否存在大于的关系.
x == y 是一个Pattern, 判断变量 x 与变量 y 是否存在等于的关系.
上式中 x >34 , x == y 便是典型的Pattern.
awk 提供 C 语言中常见的关系运算符(Relational Operators) 如
>, <, >=, <=, ==, !=
此外, awk 还提供 ~ (match) 及 !~(not match) 二个关系运算符(注一).
其用法与涵义如下:
若 A 为一字符串, B 为一正则表达式(Regular Expression)
A ~ B 判断 字符串A 中是否 包含 能匹配(match)B表达式的子字符串.
A !~ B 判断 字符串A 中是否 不包含 能匹配(match)B表达式的子字符串.
例如 :
"banana" ~ /an/ 整个是一个Pattern.
因为"banana"中含有可以匹配 /an/ 的子字符串, 故此关系式成立(true),整个Pattern的值也是true.
相关细节请参考 附录 A Patterns, 附录 E Regular Expression
(注一:) 有少数awk论著, 把 ~, !~ 当成另一类的 Operator,并不视为一种 Relational Operator. 本手册中将这两个运算符当成一种 Relational Operator.
现在我们测试一下:
源文件为test:
PID :name count money
A125 :pptv 100 210
A341 :dsp 110 215
P158 :soft 130 209
P148 :henner 125 220
A123 :quta 95 210
awk '{print $0}' test
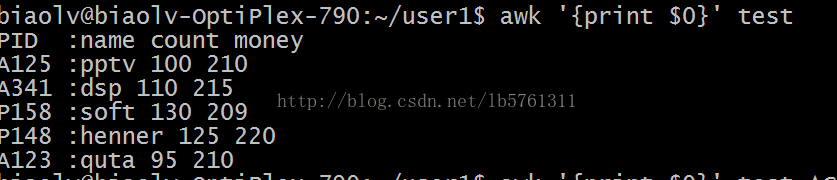
awk -F :'{print $0}' test-F 后面紧跟分隔符,awk默认以空格作为分隔符。当我们需要按照自己意愿分隔处理的时候,就需要用-F。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
所以 $0代表这一行,$1第一列,$2表示第二列一次类推
awk -F :'{print $0}' test
PID A125 A341 P158 P148 A123
<pre name="code" class="php" style="line-height: 19.5px;">awk -F :'{print $2}' test
name count money pptv 100 210 dsp 110 215 soft 130 209 henner 125 220 quta 95 210现在我们修改一下test内容:
PID :name count money A125 :pptv 100 210 A341 :dsp 110 215 P158 :soft 10 209 P148 :henner 9 220 A123 :quta 95 210
想取出来里面count数量<100的行。并打印出来,
awk '$3<100{print $0}' test
P158 :soft 10 209 P148 :henner 9 220 A123 :quta 95 210
只打印count小于100的count
awk '$3<100{print $3}' test
10 9 95
想查找test里面是否有name=pptv的字符串打印出这一行
awk '$2 ~/pptv/{print $0}' test
A125 :pptv 100 210
你也可以使用
awk '/pptv/{print $0}' test
Actions 是什么?
Actions 是由许多awk指令构成. 而awk的指令与 C 语言中的指令十分类似.
例如 :
awk的 I/O指令 : print, printf( ), getline...
awk的 流程控制指令 : if(...){..} else{..}, while(...){...}...
向我们上面写的{print } 都是action具体如下:
Actions 是由下列指令(statement)所组成 :
- 表达式 ( function calls, assignments..)
- print 表达式列表
- printf( 格式化字符串, 表达式列表)
- if( 表达式 ) 语句 [else 语句]
- while( 表达式 ) 语句
- do 语句 while( 表达式)
- for( 表达式; 表达式; 表达式) 语句
- for( variable in array) 语句
- delete
- break
- continue
- next
- exit [表达式]
- 语句
awk 中大部分指令与 C 语言中的用法一致, 此处仅介绍较为常用或容易混淆的指令的用法.
Ø流程控制指令
l if 指令
语法
if (表达式) 语句1 [else 语句2 ]
范例 :
if( $1 > 25 )
print "The 1st field is larger than 25"
else print "The 1st field is not larger than 25"
(a)与 C 语言中相同, 若 表达式 计算(evaluate)后之值不为 0 或空字符串, 则执行 语句1; 否则执行 语句2.
(b)进行逻辑判断的表达式所返回的值有两种, 若最后的逻辑值为true, 则返回1, 否则返回0.
(c)语法中else 语句2 以[ ] 前后括住表示该部分可视需要而予加入或省略.
if使用实例:还是用以前的test内容,我现在想查看test内是否有name=pptv,如果有的话且count大于90就打印出it is good。小于打印count is 加数值
awk '/pptv/{if($3 > 90) print "it is good";else print "count is " $3;}' test
it is good
l while 指令
语法 :
while( 表达式 ) 语句
范例 :
while( match(buffer,/[0-9]+\.c/ ) ){
print "Find :" substr( buffer,RSTART, RLENGTH)
buff = substr( buffer, RSTART + RLENGTH)
}
上列范例找出 buffer 中所有能匹配 /[0-9]+.c/(数字之后接上 ".c"的所有子字符串).
范例中 while 以函数 match( )所返回的值做为判断条件. 若buffer 中还含有匹配指定条件的子字符串(match成功), 则 match()函数返回1,while 将持续进行其后的语句.
l do-while 指令
语法 :
do 语句 while(表达式)
范例 :
do{
print "Enter y or n ! "
getline data
} while( data !~ /^[YyNn]$/)
(a) 上例要求用户从键盘上输入一个字符, 若该字符不是Y, y, N, 或 n则会不停执行该循环, 直到读取正确字符为止.
(b)do-while 指令与 while 指令 最大的差异是 : do-while 指令会先执行statement而后再判断是否应继续执行. 所以, 无论如何其 statement 部分至少会执行一次.
l for Statement 指令(一)
语法 :
for(variable in array ) statement
范例 : 执行下列命令
awk '
BEGIN{
X[1]= 50; X[2]= 60; X["last"]= 70
for( any in X )
printf("X[%s] = %d\n", any, X[any] )
}'
结果输出 :
X[last] = 70
X[1] = 50
X[2] = 60
(a)这个 for 指令, 专用以查找数组中所有的下标值, 并依次使用所指定的变量予以记录. 以本例而言, 变量 any 将逐次代表 "last", 1 及2 .
(b)以这个 for 指令, 所查找出的下标之值彼此间并无任何次续关系.
(c)第5节中有该指令的使用范例, 及解说.
l for Statement 指令(二)
语法 :
for(expression1; expression2; expression3) statement
范例 :
for(i=1; i< =10; i++) sum = sum + i
说明 :
(a)上列范例用以计算 1 加到 10 的总和.
(b)expression1 常用于设定该 for 循环的起始条件, 如上例中的 i=1
expression2 用于设定该循环的停止条件, 如上例中的 i <= 10
expression3 常用于改变 counter 之值, 如上例中的 i++
l break 指令
break 指令用以强迫中断(跳离) for, while, do-while 等循环.
范例 :
while( getline < "datafile" > 0 )
{
if( $1 == 0 )
break
else
print $2 / $1
}
上例中, awk 不断地从文件 datafile 中读取资料, 当$1等于0时,就停止该执行循环.
l continue 指令
循环中的 statement 进行到一半时, 执行 continue 指令来略过循环中尚未执行的statement.
范例 :
for( index in X_array)
{
if( index !~ /[0-9]+/ ) continue
print "There is a digital index", index
}
上例中若 index 不为数字则执行 continue, 故将略过(不执行)其后的指令.
需留心 continue 与 break 的差异 : 执行 continue 只是掠过其后未执行的statement, 但并未跳离开该循环.
l next 指令
执行 next 指令时, awk 将掠过位于该指令(next)之后的所有指令(包括其后的所有Pattern { Actions }), 接著读取下一笔数据行,继续从第一个 Pattern {Actions} 执行起.
范例 :
/^[ \t]*$/ { print "This is a blank line! Do nothing here !"
next
}
$2 != 0 { print $1, $1/$2 }
上例中, 当 awk 读入的数据行为空白行时( match /^[ \]*$/ ),除打印消息外只执行 next, 故 awk 将略过其后的指令, 继续读取下一笔资料, 从头(第一个 Pattern { Actions })执行起.
l exit 指令
执行 exit 指令时, awk将立刻跳离(停止执行)该awk程序.
Øawk 中的 I/O 指令
l printf 指令
该指令与 C 语言中的用法相同, 可借由该指令控制资料输出时的格式.
语法 :
printf("format", item1, item2,.. )
范 例 :
id = "BE-2647"; ave = 89
printf("ID# : %s Ave Score : %d\n", id, ave)
(a)结果印出 :
ID# : BE-2647 Ave Score : 89
(b)format 部分是由 一般的字串(String Constant) 及 格式控制字符(Formatcontrol letter, 其前会加上一个%字符)所构成. 以上式为例"ID# : " 及 " Ave Score : " 为一般字串. %s 及 %d 为格式控制字符.
(c)打印时, 一般字串将被原封不动地打印出来. 遇到格式控制字符时,则依序把 format后方之 item 转换成所指定的格式后进行打印.
(d)有关的细节, 读者可从介绍 C 语言的书籍上得到较完整的介绍.
(e)print 及 printf 两个指令, 其后可使用 > 或 >> 将输出到stdout 的数据重定向到其它文件, 7.1 节中有完整的
l print 指令
范 例 :
id = "BE-267"; ave = 89
print "ID# :", id, "Ave Score :"ave
(a)结果印出 :
ID# : BE-267 Ave Score :89
(b)print 之后可接上字串常数(Constant String)或变量. 它们彼此间可用"," 隔开.
(c)上式中, 字串 "ID# :" 与变量 id 之间使用","隔开, 打印时两者之间会以自动 OFS(请参考 附录D 內建变量 OFS) 隔开. OFS 之值一般內定为 "一个空格"
(d)上式中, 字串 "Ave Score :" 与变量ave之间并未以","隔开, awk会将这两者先当成字串concate在一起(变成"Ave Score :89")后,再予打印
l getline 指令
语法
| 语法 |
由何处读取数据 |
数据读入后置于 |
| getline var < file |
所指定的 file |
变量 var(var省略时,表示置于$0) |
| getline var |
pipe 变量 |
变量 var(var省略时,表示置于$0) |
| getline var |
见 注一 |
变量 var(var省略时,表示置于$0) |
getline 一次读取一行资料, 若读取成功则return 1,若读取失败则return -1, 若遇到文件结束(EOF), 则return 0
当其左右无重定向符 | 或 < 时,getline作用于当前文件,读入当前文件的第一行给其后跟的变量var 或$0(无变量);应该注意到,由于awk在处理getline之前已经读入了一行,所以getline得到 的返回结果是隔行的,
例如:test内容:
PID :name count money A125 :pptv 100 210 A341 :dsp 110 215 P158 :soft 10 209 P148 :henner 9 220 A123 :quta 95 210
awk '{print;{getline }}' test
结果是
PID :name count money A341 :dsp 110 215 P148 :henner 9 220
因为print和getline都是action和IO指令。每执行一次
awk '{print;{getline }}' test
读取两行数据,为什么读取两行数据呢??原因是默认情况下每执行一次awk命令读取一行,但是我们这个命令中getline为awk输入指令。getline会再读一行数据,又由于getline读取后没有进一步处理。所以打印时候少了2 .4 .6行。在getline加上print后就会完整输出
使用命令
awk '{print;{getline;print}}' test
getline 加print后打印结果:
PID :name count money A125 :pptv 100 210 A341 :dsp 110 215 P158 :soft 10 209 P148 :henner 9 220 A123 :quta 95 210
这个getline在处理特定数据时候非常有用比如:
- partition_index: SYS0 partition_name: PRELOADER file_name: none is_download: true type: SV5_BL_BIN linear_start_addr: 0 physical_start_addr: 0x0 partition_size: 0x40000 - partition_index: SYS1 partition_name: MBR file_name: none is_download: true type: NORMAL_ROM linear_start_addr: 0x0 physical_start_addr: 0x0 partition_size: 0x80000 region: EMMC_USER
上面两端文字非常类似,只有极少不同。现在我们想修改第二段文字file_name: none为file_name: hello,用普通方法比较难,这时候我们使用
awk -F ' ' '{print; if("MBR"==$2||$1=="partition_name") { getline; print " file_name: hello";} }' MM.text
结果
- partition_index: SYS0 partition_name: PRELOADER file_name: none is_download: true type: SV5_BL_BIN linear_start_addr: 0 physical_start_addr: 0x0 partition_size: 0x40000 - partition_index: SYS1 partition_name: MBR file_name: hello is_download: true type: NORMAL_ROM linear_start_addr: 0x0 physical_start_addr: 0x0 partition_size: 0x80000 region: EMMC_USER
结果成功
命令 -F 表示以空格为分隔符,print; if("MBR"==$2||$1=="partition_name") 先打印出这一行,然后判断这一行的("MBR"==$2||$1=="partition_name"是否成立,不成立继续读取下一行打印。当成立的时候。执行getline;读取file_name: none,我们打印file_name: hello,
当然这个命令也可以这样写:
awk -F ' ' '{print; if("MBR"==$2||$1=="partition_name") { getline;$2="hello";print} }' MM.text
结果一样
上面虽然从屏幕上看是修改了file_name: none。当你打开MM.text文件发现没有修改。若是想真正修改 使用这个命令
awk -F ' ' '{print; if("MBR"==$2||$1=="partition_name") { getline;$2="hello";print} }' 1<> MM.text
l close 指令
该指令用以关闭一个打开的文件, 或 pipe (见下例)
范 例 :
BEGIN { print "ID # Salary" > "data.rpt" }
{ print $1 , $2 * $3 | "sort -k 1 > data.rpt" }
END{ close( "data.rpt" )
close( "sort -k 1 > data.rpt" )
print " There are", NR, "records processed."
}
说 明 :
(a)上例中, 一开始执行 print "ID # Salary" > "data.rpt" 指令来输出一行抬头. 它使用 I/O Redirection ( > )将数据转输出到data.rpt,故此时文件 data.rpt 是处於 Open 状态.
(b)指令 print $1, $2 * $3 不停的将输出的资料送往 pipe(|), awk在程序将结束时才会呼叫 shell 使用指令 "sort -k 1 > data.rpt" 来处理 pipe 中的数据; 并未立即执行, 这点与 Unix 中pipe的用法不尽相同.
(c)最后希望於文件 data.rpt 的末尾处加上一行 "There are.....".但此时, Shell尚未执行 "sort -k 1 > data.rpt" 故各数据行排序后的 ID 及 Salary 等数据尚未写入data.rpt. 所以得命令 awk 提前先通知 Shell 执行命令 "sort -k 1 > data.rpt" 来处理pipe 中的资料. awk中这个动作称为 close pipe. 是由执行 close ( "shell command" )来完成. 需留心 close( )指令中的 shell command
需与"|"后方的 shell command 完全相同(一字不差), 较佳的方法是先以该字串定义一个简短的变量, 程序中再以此变量代替该shell command
(d)为什么执行 close("data.rpt") ? 因为 sort 完后的资料也将写到data.rpt,而该文件正为awk所打开使用(write)中, 故awk程式中应先关闭data.rpt. 以免造成因二个 processes 同时打开一个文件进行输出(write)所产生的错误.
l system 指令
该指令用以执行 Shell上的 command.
范 例 :
DataFile = "invent.rpt"
system( "rm " DataFile )
说明 :
(a)system("字符串")指令接受一个字符串当成Shell的命令. 上例中, 使用一个字串常数"rm " 连接(concate)一个变量 DataFile 形成要求 Shell 执行的命令.Shell 实际执行的命令为 "rm invent.rpt".
l "|" pipe指令
"|" 配合 awk 输出指令, 可把 output 到 stdout 的资料继续转送给Shell 上的某一命令当成input的资料.
"|" 配合 awk getline 指令, 可呼叫 Shell 执行某一命令, 再以 awk 的 getline 指令将该命令的所产生的资料读进 awk 程序中.
范 例 :
{ print $1, $2 * $3 | "sort -k 1 > result" }
"date" | getline Date_data
读者请参考7.2 节,其中有完整的范例说明.
Øawk 释放所占用的记忆体的指令
awk 程式中常使用数组(Array)来记忆大量数据, delete 指令便是用来释放数组中的元素所占用的内存空间.
范 例 :
for( any in X_arr )
delete X_arr[any]
读者请留心, delete 指令一次只能释放数组中的一个元素.
Øawk 中的数学运算符(Arithmetic Operators)
+(加), -(減), *(乘), /(除), %(求余数), ^(指数) 与 C 语言中用法相同
Øawk 中的赋值运算符(Assignment Operators)
=, +=, -=, *= , /=, %=, ^=
x += 5 的意思为 x = x + 5, 其余类推.
Øawk 中的条件运算符(Conditional Operator)
语 法 :
判断条件 ? value1 : value2
若 判断条件 成立(true) 则返回 value1, 否则返回 value2.
Øawk 中的逻辑运算符(Logical Operators)
&&( and ), ||(or), !(not)
Extended Regular Expression 中使用 "|" 表示 or 请勿混淆.
Øawk 中的关系运算符(Relational Operators)
>, >=, <, < =, ==, !=, ~, !~
Øawk 中其它的运算符
+(正号), -(负号), ++(Increment Operator), - -(Decrement Operator)
Øawk 中各运算符的运算级
按优先高低排列:
$ (栏位运算元, 例如 : i=3; $i表示第3栏)
^ (指数运算)
+ ,- ,! (正,负号,及逻辑上的 not)
* ,/ ,% (乘,除,余数)
+ ,- (加,減)
>, > =,< , < =, ==, != (关系运算符)
~, !~ (match, not match)
&& (逻辑上的 and)
|| (逻辑上的 or )
? : (条件运算符)
= , +=, -=,*=, /=, %=, ^= (赋值运算符)